См. также: Прикладная
математическая статистика (материалы к семинарам)
Заводская лаборатория. - 1997. - Т.63. - № 5. - С. 43-49.
УДК 519.24
Робастные методы оценивания и отбраковка аномальных измерений
Б.Ю. Лемешко
При решении задач статистического анализа и, в частности, при вычислении оценок параметров распределений проблема наличия в выборке аномальных измерений имеет чрезвычайно важное значение. Присутствие единственного аномального наблюдения может приводить к оценкам, которые совершенно не согласуются с выборочными данными.
В борьбе с грубыми погрешностями измерений, если они не были обнаружены в процессе измерений, используют два подхода:
· исключение резко выделяющихся аномальных измерений из дальнейшей обработки;
· использование робастных методов обработки.
В данной работе остановимся на комплексе взаимосвязанных вопросов: “простом” способе робастного оценивания параметров непрерывных законов распределения, мощности критериев согласия и достаточно эффективном параметрическом методе отбраковки аномальных наблюдений.
В статистике под робастностью понимают нечувствительность к малым отклонениям от предположений [1].
Понятно желание каждого исследователя, чтобы найденные оценки были как можно менее чувствительны к аномальным наблюдениям. В противном случае прежде чем переходить к оцениванию, приходится использовать процедуры исключения грубых ошибок измерений, что выливается в непростую задачу, которая, как справедливо отмечается в [2], без устойчивых методов надёжно не решается. Соглашаясь в принципе со справедливыми доводами, приводимыми в этой работе в поддержку вывода о неустойчивости параметрических методов отбраковки резко выделяющихся наблюдений, мы не склонны хоронить параметрические методы, так как при определённых условиях получаются очень хорошие результаты.
Воспользуемся почти дословно постановкой задачи отбраковки, как она изложена в
[2]. Рассматривается ситуация, когда ![]() числа.
Резко выделяется одно наблюдение, для определенности
числа.
Резко выделяется одно наблюдение, для определенности ![]() . При нулевой гипотезе
. При нулевой гипотезе ![]() наблюдения
наблюдения ![]() рассматриваются
как реализация независимых одинаково распределенных случайных величин
рассматриваются
как реализация независимых одинаково распределенных случайных величин ![]() с функцией распределения
с функцией распределения ![]() . При альтернативной гипотезе
. При альтернативной гипотезе ![]() случайные величины
случайные величины ![]() также независимы,
также независимы, ![]() имеют распределение
имеют распределение ![]() , а
, а ![]() -
распределение
-
распределение ![]() , которое “существенно сдвинуто
вправо” относительно
, которое “существенно сдвинуто
вправо” относительно ![]() ,
например
,
например ![]() , где
, где ![]() достаточно
велико. Если
достаточно
велико. Если ![]() , то принимается гипотеза
, то принимается гипотеза ![]() , в противном случае - гипотеза
, в противном случае - гипотеза ![]() . При справедливости нулевой гипотезы
. При справедливости нулевой гипотезы ![]() , и критическое значение
, и критическое значение ![]() определяется из уравнения
определяется из уравнения ![]() . При больших
. При больших ![]() и
малых
и
малых ![]()
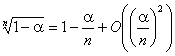 ,
(1)
,
(1)
поэтому
в качестве хорошего приближения к ![]() рассматривают
рассматривают
![]() -квантиль распределения
-квантиль распределения ![]() .
.
Неустойчивость такой процедуры отбраковки в работе [2] связана с возможным
неточным определением закона ![]() и
трудностью различения близких законов распределения с помощью критериев
согласия и, в частности, с помощью критерия Колмогорова. Приводимые доводы
справедливы. Те исследователи, кто неоднократно в своей практике пытался
идентифицировать закон распределения, связанный с конкретной выборкой, убедился,
что достаточно часто используемый критерий согласия не даёт оснований отвергать
целый ряд законов распределения. Способность критерия различать близкие
альтернативные гипотезы определяется его мощностью. Именно недостаточная
мощность критерия не позволяет нам принять решение.
и
трудностью различения близких законов распределения с помощью критериев
согласия и, в частности, с помощью критерия Колмогорова. Приводимые доводы
справедливы. Те исследователи, кто неоднократно в своей практике пытался
идентифицировать закон распределения, связанный с конкретной выборкой, убедился,
что достаточно часто используемый критерий согласия не даёт оснований отвергать
целый ряд законов распределения. Способность критерия различать близкие
альтернативные гипотезы определяется его мощностью. Именно недостаточная
мощность критерия не позволяет нам принять решение.
Приводимые далее примеры и выводы получены на основании результатов, которые были использованы при создании программной системы [3], разработанной в Новосибирском государственном техническом университете, и опыте её применения.
В программной системе все задачи статистического анализа данных рассматриваются
с точки зрения наиболее общего представления экспериментальных наблюдений
в виде частично группированных выборок [4,5], частными случаями которых
являются негруппированные, группированные и
цензурированные выборки. Выборка является негруппированной,
если выборочные значения представляют собой индивидуальные значения наблюдений
из области определения случайной величины. Выборка является группированной,
если область определения случайной величины разбита на
![]() непересекающихся интервалов граничными точками
непересекающихся интервалов граничными точками
![]() ,
,
где
![]() - нижняя грань области определения случайной величины
X,
- нижняя грань области определения случайной величины
X, ![]() - верхняя грань области определения случайной
величины X, и зафиксированы количества наблюдений
- верхняя грань области определения случайной
величины X, и зафиксированы количества наблюдений ![]() , попавших в
, попавших в ![]() -й
интервал значений. Выборка является частично группированной, если имеющаяся
в нашем распоряжении информация связана с множеством непересекающихся интервалов,
которые делят область определения случайной величины так, что каждый интервал
принадлежит к одному из двух типов:
-й
интервал значений. Выборка является частично группированной, если имеющаяся
в нашем распоряжении информация связана с множеством непересекающихся интервалов,
которые делят область определения случайной величины так, что каждый интервал
принадлежит к одному из двух типов:
а) ![]() -й
интервал принадлежит к первому типу, если число
-й
интервал принадлежит к первому типу, если число ![]() известно, но индивидуальные значения
известно, но индивидуальные значения ![]() , неизвестны;
, неизвестны;
б) ![]() -й
интервал принадлежит ко второму типу, если известно не только число
-й
интервал принадлежит ко второму типу, если известно не только число ![]() , но и все индивидуальные значения
, но и все индивидуальные значения ![]() .
.
Область
определения случайной величины в этом случае можно представить в виде ![]() , где
, где ![]() -
множество интервалов первого типа, а
-
множество интервалов первого типа, а ![]() -
множество интервалов второго типа.
-
множество интервалов второго типа.
Совокупность решаемых задач позволяет идентифицировать закон распределения случайной величины. Идентификация закона распределения происходит по следующему алгоритму: ограничение множества “подходящих” распределений; определение для каждого закона распределения из данного множества оценок неизвестных параметров и проверка гипотез о согласии полученного закона распределения с исходными данными; выбор того закона распределения, согласие с которым наиболее хорошее.
Программная система охватывает класс, состоящий из 26 непрерывных законов
распределения случайных величин, наиболее часто используемых в приложениях:
экспоненциального, полунормального, Рэлея, Максвелла,
модуля многомерного нормального вектора, Парето, Эрланга, Лапласа, нормального,
логарифмически нормальных (ln и lg), Коши, Вейбулла, Накагами, распределения минимального значения, распределения
максимального значения, двойного показательного, гамма-распределения,
логистического, бета-распределения
1-го рода, стандартного бета-распределения 2-го
рода, бета-распределения 2-го рода, распределений ![]() -Джонсона,
-Джонсона, ![]() -Джонсона
и
-Джонсона
и ![]() -Джонсона, экспоненциального семейства распределений.
-Джонсона, экспоненциального семейства распределений.
Основным методом оценивания параметров распределений, заложенным в системе, является метод максимального правдоподобия. Оценки параметров распределений находятся в результате максимизации функции правдоподобия по частично группированной выборке, которая имеет вид:
![]() ,
,
где
![]() - функция плотности случайной величины,
- функция плотности случайной величины, 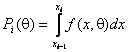 - вероятность попадания наблюдения в
- вероятность попадания наблюдения в ![]() -й
интервал значений, (1) и (2) означают, что умножение осуществляется по интервалам
с группированными и негруппированными данными
соответственно.
-й
интервал значений, (1) и (2) означают, что умножение осуществляется по интервалам
с группированными и негруппированными данными
соответственно.
Проверка гипотез о согласии осуществляется по ряду критериев: отношения
правдоподобия, ![]() Пирсона, Колмогорова, Смирнова,
Пирсона, Колмогорова, Смирнова, ![]() и
и ![]() Мизеса. Решение о степени соответствия выборки с законом
распределения принимается по их совокупности.
Мизеса. Решение о степени соответствия выборки с законом
распределения принимается по их совокупности.
При проверке гипотез о согласии проверяется гипотеза вида ![]()
![]() .
В принятой практике статистического анализа проверка
как правило осуществляется по следующей схеме. Для выбранного критерия
вычисляется значение
.
В принятой практике статистического анализа проверка
как правило осуществляется по следующей схеме. Для выбранного критерия
вычисляется значение ![]() статистики
статистики
![]() как некоторой функции от выборки и закона
распределения
как некоторой функции от выборки и закона
распределения ![]() . Для используемых на практике критериев обычно известны
асимптотические распределения
. Для используемых на практике критериев обычно известны
асимптотические распределения ![]() соответствующих
статистик при условии истинности гипотезы
соответствующих
статистик при условии истинности гипотезы ![]() .
Далее сравнивают полученное значение статистики
.
Далее сравнивают полученное значение статистики ![]() с критическим для
данного уровня значимости
с критическим для
данного уровня значимости ![]() и
нулевую гипотезу отвергают, если
и
нулевую гипотезу отвергают, если ![]() .
Критическое значение
.
Критическое значение ![]() ,
определяемое из уравнения
,
определяемое из уравнения
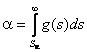 ,
,
где
![]() - задаваемый уровень значимости, обычно берётся
из соответствующей статистической таблицы.
- задаваемый уровень значимости, обычно берётся
из соответствующей статистической таблицы.
В такой ситуации остается за кадром величина вероятности превышения полученного значения статистики при истинности нулевой гипотезы, хотя именно она и позволяет судить о степени согласия, так как по существу представляет собой вероятность истинности нулевой гипотезы.
Для включенных в программное обеспечение критериев в обязательном порядке отображается соответствующая вероятность превышения полученного значения статистики при истинности нулевой гипотезы
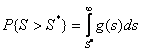 .
.
Гипотеза
о согласии не отвергается, если ![]() .
.
Статистика критерия согласия ![]() Пирсона при истинной гипотезе
Пирсона при истинной гипотезе ![]() в пределе подчиняется
в пределе подчиняется ![]() -распределению с числом степеней свободы
-распределению с числом степеней свободы ![]() , если по выборке не оценивались параметры, и с
, если по выборке не оценивались параметры, и с ![]() , если по ней оценивалось
, если по ней оценивалось ![]() параметров закона распределения. Вероятность
вида
параметров закона распределения. Вероятность
вида ![]() для распределения
для распределения ![]() вычисляется при числе степеней свободы
вычисляется при числе степеней свободы ![]() и
и ![]() .
Все вышесказанное справедливо и для критерия отношения правдоподобия [6].
.
Все вышесказанное справедливо и для критерия отношения правдоподобия [6].
Для непараметрических критериев Колмогорова, Смирнова, ![]() и
и ![]() Мизеса предельные распределения статистик известны только
для ситуации полностью определенных законов распределения
Мизеса предельные распределения статистик известны только
для ситуации полностью определенных законов распределения ![]() [7]. К сожалению, в случае оценивания
параметров по выборке и дальнейшей проверки согласия с соответствующим
законом действительные предельные распределения непараметрических критериев
существенно отличаются [8]. Использование же предельных распределений,
соответствующих гипотезе
[7]. К сожалению, в случае оценивания
параметров по выборке и дальнейшей проверки согласия с соответствующим
законом действительные предельные распределения непараметрических критериев
существенно отличаются [8]. Использование же предельных распределений,
соответствующих гипотезе ![]() с
известными параметрами, приводит к неоправдано
завышенным значениям вероятностей вида
с
известными параметрами, приводит к неоправдано
завышенным значениям вероятностей вида ![]() ,
что прослеживается и на приводимых ниже примерах.
,
что прослеживается и на приводимых ниже примерах.
В данной работе отметим два достоинства методов, реализованных в программной
системе. Во-первых, свойства получаемых оценок, использующих группирование
исходных выборочных данных. Очевидно, что они менее чувствительны к случайным
выбросам. Группирование выборки позволяет резко снизить влияние аномальных
наблюдений, а иногда и практически исключить влияние грубых ошибок измерений.
Во-вторых, использование асимптотически оптимального группирования в критериях
отношения правдоподобия и ![]() Пирсона
[5]. Мощности критериев отношения правдоподобия и
Пирсона
[5]. Мощности критериев отношения правдоподобия и ![]() Пирсона пропорциональны количеству информации
Фишера о параметрах распределения в группированной выборке. Асимптотически
оптимальное группирование минимизирует потери информации, связанные с
группированием и следовательно гарантирует максимальную
мощность различения близких альтернатив для этих критериев. Полученные
ранее таблицы асимптотически оптимального группирования [5] встроены в
программное обеспечение.
Пирсона пропорциональны количеству информации
Фишера о параметрах распределения в группированной выборке. Асимптотически
оптимальное группирование минимизирует потери информации, связанные с
группированием и следовательно гарантирует максимальную
мощность различения близких альтернатив для этих критериев. Полученные
ранее таблицы асимптотически оптимального группирования [5] встроены в
программное обеспечение.
В задаче отбраковки аномальных наблюдений на разных этапах её решения к статистическим процедурам оценивания и проверки гипотез предъявляются, вообще говоря, прямо противоположные требования. На этапе идентификации закона распределения и оценивании его параметров методы должны быть как можно менее чувствительны к наличию аномальных ошибок измерений. Наоборот, на последующем этапе исключения аномальных измерений критерий должен улавливать их наличие и позволять отсекать.
Таким образом, при идентификации (при оценивании параметров распределений) мы должны использовать робастные алгоритмы (устойчивые к наличию аномальных наблюдений), а на последующем этапе отбраковки желательна максимальная мощность критерия для различения близких альтернатив (чувствительность к грубым ошибкам). В этой связи мы рекомендуем на первом этапе использовать оценки по группированным данным, причем для большей устойчивости оценок осуществлять разбиение выборки на интервалы равной вероятности (равночастотные интервалы), а на втором этапе при проверке согласия - разбиение на асимптотически оптимальные интервалы.
Продемонстрируем сказанное на конкретном примере. Была смоделирована выборка объёмом 1000 наблюдений в соответствии с распределением Вейбулла с плотностью
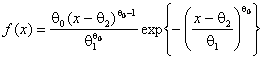 .
.
При
моделировании были заданы параметры: ![]() В
процессе регистрации 8 наблюдений “подверглись” сильным искажениям.
В
процессе регистрации 8 наблюдений “подверглись” сильным искажениям.
На рис.1-2 приведены результаты статистического анализа полученной выборки.
Здесь и в дальнейшем ![]() .
На рисунках отражаются результаты проверки гипотез о согласии: вычисленные
значения
.
На рисунках отражаются результаты проверки гипотез о согласии: вычисленные
значения ![]() соответствующих статистик
соответствующих статистик ![]() и вероятности превышения полученного значения
статистики при истинности нулевой гипотезы
и вероятности превышения полученного значения
статистики при истинности нулевой гипотезы ![]() .
Гипотеза о согласии не отвергается, если
.
Гипотеза о согласии не отвергается, если ![]() .
В данном случае получили закон распределения Вейбулла
с параметрами
.
В данном случае получили закон распределения Вейбулла
с параметрами ![]() Как
видим из рис.1, согласие по всем критериям отвергается: наличие аномальных
наблюдений сыграло свою роль. На рис.2 хорошо заметна разница между
эмпирической и теоретической функциями распределения.
Как
видим из рис.1, согласие по всем критериям отвергается: наличие аномальных
наблюдений сыграло свою роль. На рис.2 хорошо заметна разница между
эмпирической и теоретической функциями распределения.
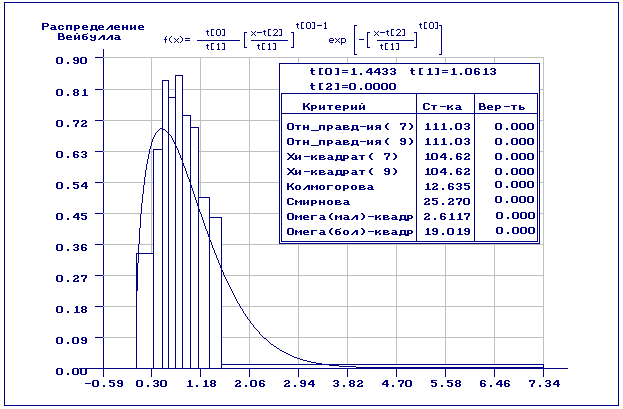
Рис.1. Результаты статистического анализа исходной выборки по негруппированным данным
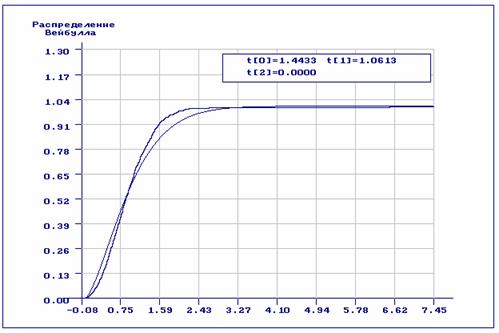
Рис.2. Теоретическая и эмпирическая функции распределения
На рис.3 приведены результаты статистического анализа, когда перед
оцениванием выборка была разбита на интервалы равной частоты, затем по
получившейся группированной выборке были найдены оценки параметров
распределения ![]() , после чего проверены гипотезы о согласии исходной
выборки с полученным законом распределения. При проверке гипотез о согласии исходная выборка
разбивалась на интервалы равной вероятности. Как видим, результаты проверки
гипотез о согласии по всем критериям очень хорошие.
, после чего проверены гипотезы о согласии исходной
выборки с полученным законом распределения. При проверке гипотез о согласии исходная выборка
разбивалась на интервалы равной вероятности. Как видим, результаты проверки
гипотез о согласии по всем критериям очень хорошие.
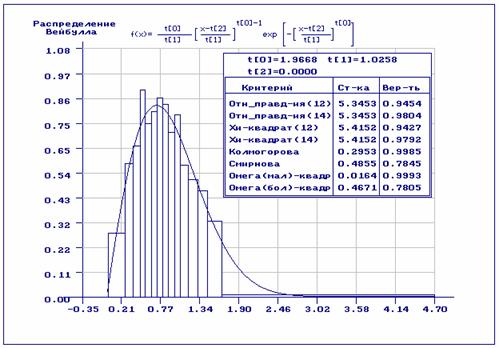
Рис.3. Оценивание с предварительным равночастотным группированием и проверкой гипотез о согласии с разбиением на равночастотные интервалы.
Отличие результатов на рис. 4 определяется тем, что при проверке гипотез о
согласии исходная выборка разбивалась на интервалы в соответствии с
асимптотически оптимальным группированием. В данном случае критерии отношения
правдоподобия и ![]() Пирсона оказываются более чувствительными, чем
остальные, улавливают наличие аномальных измерений. Гипотезы о согласии при
Пирсона оказываются более чувствительными, чем
остальные, улавливают наличие аномальных измерений. Гипотезы о согласии при ![]() по
этим критериям должны быть отвергнуты.
по
этим критериям должны быть отвергнуты.
Приведенные на рис.5-6 результаты анализа, аналогичны тем, что представлены на
рис.3-4, но перед оцениванием выборка была разбита на асимптотически
оптимальные интервалы. Получены оценки параметров ![]() . Если при проверке гипотез исходная выборка разбивалась
на интервалы равной вероятности (рис. 5), то гипотеза о согласии по всем
критериям принимается. При использовании асимптотически оптимального
группирования гипотеза о согласии по критериям отношения правдоподобия и
. Если при проверке гипотез исходная выборка разбивалась
на интервалы равной вероятности (рис. 5), то гипотеза о согласии по всем
критериям принимается. При использовании асимптотически оптимального
группирования гипотеза о согласии по критериям отношения правдоподобия и ![]() Пирсона должна быть отвергнута (рис.6). Если мы
сравним эти результаты, с результатами, представленными на рис. 3-4, то
увидим, что уровень согласия в данном случае ниже. То есть, полученные оценки
оказались хуже, а способ их определения более чувствителен к аномальным
наблюдениям.
Пирсона должна быть отвергнута (рис.6). Если мы
сравним эти результаты, с результатами, представленными на рис. 3-4, то
увидим, что уровень согласия в данном случае ниже. То есть, полученные оценки
оказались хуже, а способ их определения более чувствителен к аномальным
наблюдениям.
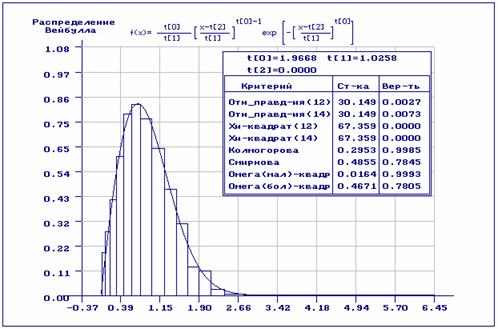
Рис.4. Оценивание с предварительным равночастотным группированием и проверкой гипотез о согласии с разбиением на асимптотически оптимальные интервалы
Для отбраковки аномальных наблюдений зададимся уровнем значимости ![]() и, опираясь на соотношение (1), при объёме
выборки
и, опираясь на соотношение (1), при объёме
выборки ![]() и векторе параметров
и векторе параметров ![]() распределения Вейбулла
найдем
распределения Вейбулла
найдем ![]() (в систему встроена возможность вычисления
различных вероятностей для законов распределения). Далее, мы должны исключить
те наблюдения, которые превышают величину
(в систему встроена возможность вычисления
различных вероятностей для законов распределения). Далее, мы должны исключить
те наблюдения, которые превышают величину ![]() .
Таких наблюдений оказалось 8.
.
Таких наблюдений оказалось 8.
На рис.7 отражены результаты статистического анализа выборки после исключения из неё аномальных наблюдений. При проверке согласия использовано разбиение области определения случайной величины на равновероятные интервалы. Как видим, согласие по всем критериям очень хорошее. На рис.8 представлены аналогичные результаты с использованием асимптотически оптимального группирования в критериях согласия.
В довершение картины на рис.9 приведены результаты проверки согласия найденного закона (после отбраковки грубых ошибок измерений) с исходной выборкой, содержащей ошибки измерений, с применением асимптотически оптимального группирования.
Нельзя не привести ещё один пример, подчеркивающий устойчивость оценок максимального правдоподобия по группированным данным. Он связан с использованием нормального закона распределения в ситуации, когда на самом деле выборка принадлежит распределению Коши.
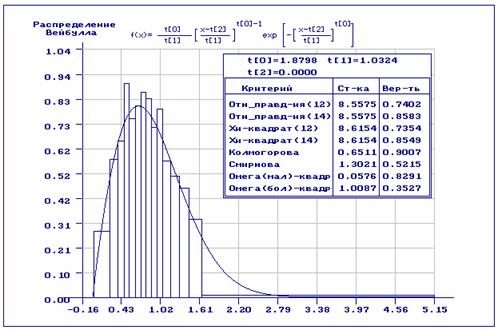
Рис.5. Оценивание с предварительным асимптотически оптимальным группированием. При проверке согласия использованы равночастотные интервалы.
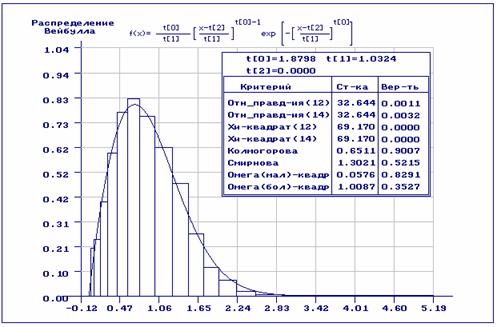
Рис.6. Оценивание с предварительным группированием с разбиением на асимптотически оптимальные интервалы. При проверке согласия также использовано асимптотически оптимальное группирование.
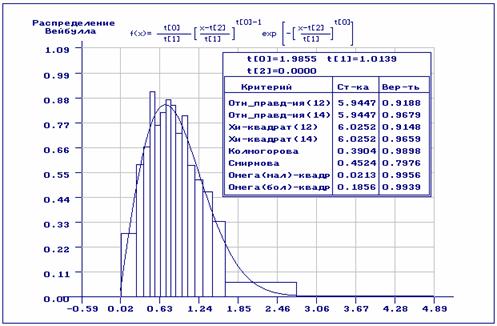
Рис.7. Результаты анализа после удаления аномальных наблюдений (при проверке согласия использовано равночастотное группирование)
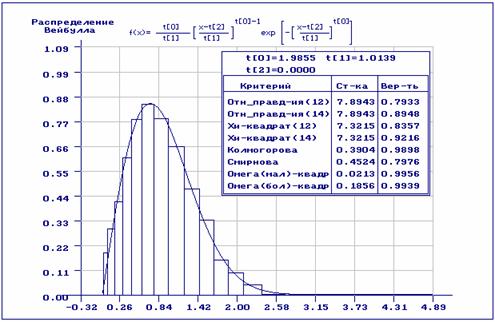
Рис.8. Результаты анализа после удаления аномальных наблюдений (при проверке согласия использовано асимптотически оптимальное группирование)
Распределение Коши это распределение с “тяжелыми” хвостами, а такое отклонение
от нормальности особенно сильно отражается на оценках параметров нормального
закона. На рис. 10-11 приведены эмпирическая и теоретические
функции нормального распределения при использовании обычных оценок максимального
правдоподобия (рис.10, оценки параметров нормального распределения: ![]() ) и оценок максимального правдоподобия по
группированным данным (рис.11, оценки:
) и оценок максимального правдоподобия по
группированным данным (рис.11, оценки: ![]() ,
, ![]() ). Качественная картина, хорошо прослеживаемая на
графиках, говорит сама за себя: во втором случае можно даже говорить об
определенной близости эмпирической и теоретической функций распределения.
Выборка объёмом 100 наблюдений моделировалась по закону Коши с функцией
плотности
). Качественная картина, хорошо прослеживаемая на
графиках, говорит сама за себя: во втором случае можно даже говорить об
определенной близости эмпирической и теоретической функций распределения.
Выборка объёмом 100 наблюдений моделировалась по закону Коши с функцией
плотности ![]() и параметрами
и параметрами ![]() ,
, ![]() .
.
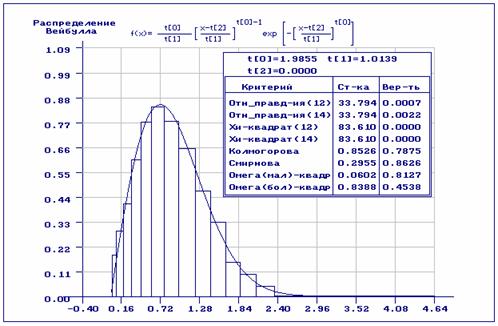
Рис. 9. Проверка согласия с исходной выборкой (при проверке согласия использовано асимптотически оптимальное группирование)
Выводы
1. При решении задачи отбраковки на этапе идентификации закона распределения (при оценивании параметров распределений) следует использовать робастные алгоритмы (устойчивые к наличию аномальных наблюдений). Высокую устойчивость к присутствию в выборке грубых искажений или принадлежности выборки к другому закону распределения проявляют оценки максимального правдоподобия по группированной выборке. Обычно наиболее устойчивы эти оценки при разбиении области определения случайной величины на интервалы равной вероятности (равночастотные интервалы). Однако достаточно часто устойчивее оказываются оценки, использующие асимптотически оптимальное группирование. Поэтому целесообразно рекомендовать на этом этапе оба способа группировки при вычислении оценок с последующим выбором тех, которые дают наилучшее согласие.
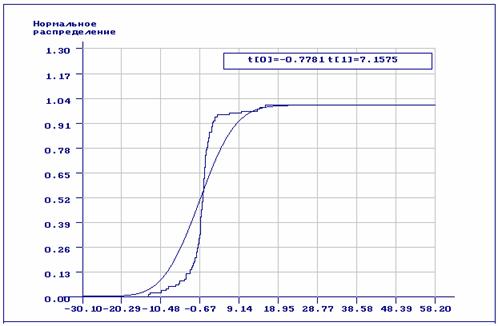
Рис.10. Эмпирическая функция распределения и нормальный закон распределения, найденный по выборке, принадлежащей распределению Коши.
2. В общем случае критерии согласия
являются недостаточно мощными, чтобы распознать близкие альтернативы (близкие
законы распределения). Этим определяется, что достаточно часто используемые
критерии не позволяют отклонить гипотезу о согласии с одним распределением, с
другим, с третьим ... Нельзя доверять выводам типа “с уровнем значимости
таким-то гипотеза о согласии с нормальным распределением не отвергается”, так
как наверняка с большим основанием не будет отвергаться гипотеза о согласии и
с другими распределениями. Если нас действительно интересует, насколько
сильно отличается выборка от предполагаемого распределения, следует применять
критерии отношения правдоподобия и ![]() Пирсона
с использованием асимптотически оптимального группирования, что гарантирует
их максимальную мощность при распознавании близких гипотез. В этом случае
непараметрические критерии Колмогорова, Смирнова,
Пирсона
с использованием асимптотически оптимального группирования, что гарантирует
их максимальную мощность при распознавании близких гипотез. В этом случае
непараметрические критерии Колмогорова, Смирнова, ![]() и
и ![]() Мизеса существенно уступают им, если не учитывается факт
оценивания по выборке параметров распределения.
Мизеса существенно уступают им, если не учитывается факт
оценивания по выборке параметров распределения.
3. С учетом вышесказанного параметрический метод отбраковки грубых ошибок измерений позволяет эффективно исключать аномальные наблюдений.
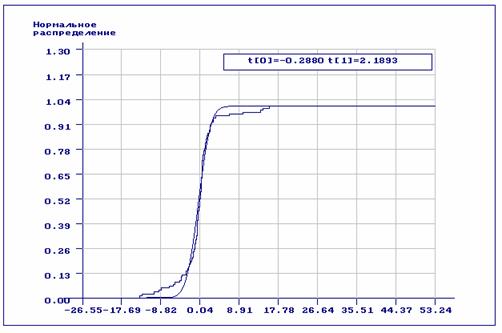
Рис.11. Эмпирическая функция распределения и теоретическая функция нормального закона распределения, найденная по сгруппированной выборке, принадлежащей распределению Коши.
1. Хьюбер П. Робастность в статистике. - М.: Мир, 1984. - 303 с.
2. Орлов А.И. Неустойчивость параметрических методов отбраковки резко выделяющихся наблюдений // Заводская лаборатория. 1992. Т. 58. № 7. С. 40-42.
3. Лемешко Б.Ю. Статистический анализ одномерных наблюдений случайных величин: Программная система / Новосиб. гос. техн. ун-т. - Новосибирск, 1995. 125 с.
4. Куллдорф Г. Введение в теорию оценивания по группированным и частично группированным выборкам. - М.: Наука, 1966. - 176 с.
5. Денисов В.И., Лемешко Б.Ю., Цой Е.Б. Оптимальное группирование, оценка параметров и планирование регрессионных экспериментов: В 2 ч. / Новосиб. гос. техн. ун-т. - Новосибирск, 1993. 346 с.
6. Кендалл М., Стьюарт А. Статистические выводы и связи. - М.: Наука, 1973. - 900 с.
7. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. - М.: Наука, 1983. - 416 с.
8.
Орлов А.И. Распространенная ошибка при
использовании критериев Колмогорова и омега-квадрат // Заводская лаборатория.
1985. Т. 51. № 1. С. 60-62.