Модели оптимального размещения таблиц РБД в узлах сети с произвольной топологией
Рассмотрим метод построения модели оптимального размещения файлов в вычислительной сети с произвольной топологией. В качестве критерия оптимальности возьмем средний объем пересылаемых по линиям связи данных при выполнении запроса.
Рассмотрим вычислительную сеть, каждый узел которой состоит из ЭВМ, терминального устройства и аппаратуры передачи данных. Пусть топология вычислительной сети является произвольной. Это означает, что, во-первых, существует доступ из каждого узла сети к информации любого другого узла, во-вторых, на линии связи между узлами сети не накладываются никакие ограничения.
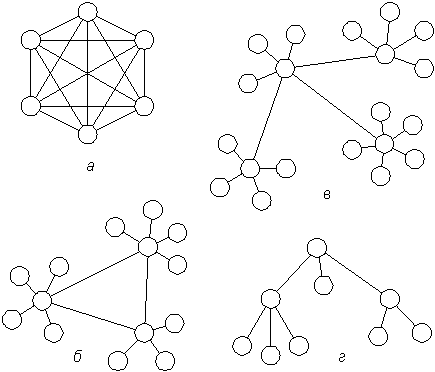
1. Вычислительные сети с произвольной топологией:
а - сеть с попарно связанными узлами; б - объединение локальных сетей со звездообразной топологией в глобальную кольцевую сеть; в - объединение локальных сетей со звездообразной топологией в глобальную сеть с той же топологией; г - сеть с топологией в виде дерева.
Предположим, что запрос, поступающий на терминальное устройство любого узла, предполагает доступ к определенному файлу РБД, и все запросы к одному и тому же файлу имеют одинаковую длину и требуют для ответа одинаковый объем данных. Будем считать, что схема обработки запросов состоит в следующем.
Запрос, инициированный на терминале, поступает во входную очередь соответствующего узла. Процессор ЭВМ обрабатывает запросы в порядке их поступления. Если нужный файл содержится в локальной базе данных узла, на терминал которого поступил запрос, то запрос обрабатывается и результат выводится на данный терминал. Если нужный файл содержится в другом узле, то запрос пересылается в этот узел, там обрабатывается и результат пересылается в первоначальный узел. Порядок обслуживания запросов в узлах не влияет на объем пересылаемых данных по каналам связи. Поэтому он может быть принят таким же, как и в случае модели для звездообразной топологии.
Из описанной схемы обработки запросов в системе следует, что в процессе обслуживания в течение каждой единицы времени по каналам связи пересылается некоторый объем данных. Общее значение этого объема зависит от распределения файлов по локальным базам данных. Чем меньше средний объем пересылаемых данных по каналам сети за единицу времени, тем выше скорость обработки запросов.
Пусть
п - число узлов сети;
т - число независимых файлов РБД;
Kj - j-ый узел сети;
Fi - i-ый
файл РБД;
Li - объем i-го файла;
bj - объем памяти узла Kj, предназначенной для размещения файлов;
lij - интенсивность запросов к файлу Fi, инициированных в узле Kj;
ai - объем
запроса к файлу Fi;
bi - объем запрашиваемых данных при выполнении запроса к файлу Fi;
Тогда объем данных,
поступающих на терминал узла, содержащего i-й файл, при
выполнении запроса к файлу Fi, равен ai+bi. При этом если xij (i = 1,2,...,т; j = 1,2,...,п) -
величины, определяемые по формуле
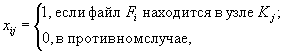
то объем пересылаемых данных при выполнении запроса к файлу Fi, инициированного в узле Kj, равен (ai + bi)(1 - xij).
Поскольку lij -
интенсивность запросов файлу Fi, инициированных в узле Kj,
то она порождает объем данных lij(ai+bi)(1-xij),
нуждающихся в пересылке. Поэтому общий объем данных, которые требуется
переслать по каналам связи между узлами вследствие функционирования системы в течении
единицы времени, определяется формулой
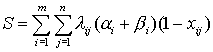 .
.
Если положить
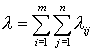 ,
,
то средний объем данных, необходимых для пересылки по
линиям связи при выполнении запроса в системе, равен
|
|
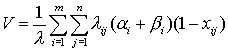
Очевидно, чем меньше значение для V, тем выше скорость обслуживания запросов в системе.
Поскольку каждый файл Fi (i = 1,2,:,m) должен находится в одном из узлов вычислительной сети, то
|
|
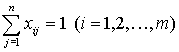
Кроме того, объем локальной
базы данных каждого узла Kj (j = 1,2,:,п) не должен превышать объем памяти
этого узла, предназначенный для размещения файлов. Поэтому
Таким образом, задача оптимального распределения файлов по узлам вычислительной сети состоит в том, чтобы определить значения переменных хij, где
![]()
которые удовлетворяют условиям (26), (27) и дают минимум линейной функции (25). Полученная математическая модель является задачей целочисленного линейного программирования с булевыми переменными.
Запросы к одному и тому же
файлу Fi, поступающие на терминалы разных узлов, могут быть
различных типов. В этом случае объем запроса и объем запрашиваемых данных
зависит от узла, на который поступил запрос.
Пусть aij - объем запроса к файлу Fi, инициированного на терминале узла Kj; bij - объем запрашиваемых данных при выполнении запроса к
файлу Fi, поступившего на
терминал узла Kj. Тогда
целевая функция задачи оптимального распределения файлов по узлам
вычислительной сети может быть записана в виде
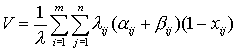 .
.
Запишем целевую функцию задачи оптимального распределения файлов по узлам вычислительной сети в случае, когда запросы из фиксированного узла к одному и тому же файлу могут быть различного типа.
Пусть
s - число типов запросов;
lkij - интенсивность запросов k-го типа к файлу Fi, инициированных в узле Kj;
akij - объем запроса k-го типа к файлу
Fi, инициированного на терминале узла Kj;
bkij - объем запрашиваемых данных при выполнении запроса k-го типа к файлу Fi, поступившего на терминал узла Kj;
Тогда объем пересылаемых данных при выполнении запроса k-го типа к файлу Fi, инициированного в узле Kj, равен (akij+bkij)(1-xij). Поскольку интенсивность lkij порождает объем данных lkij(akij+bkij)(1-xij), нуждающихся в пересылке, то общий объем данных, которые требуется переслать по каналам связи между узлами вследствие функционирования распределенной системы в течение единицы времени, определяется формулой
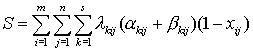 .
.
Если положить
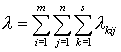 ,
,
то целевая функция задачи оптимального распределения файлов по узлам вычислительной сети примет вид
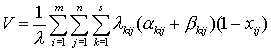 .
.
Все сообщения, поступающие во входные очереди узлов, разделим на два типа: тип 1 - сообщения, составляющие запросы, для обработки которых необходимые файлы не содержатся в базе данных узла, и ответы на эти запросы; тип 2 - сообщения, составляющие запросы, для обслуживания которых нужные файлы содержатся в базе данных соответствующего узла. При этом будем считать, что запрос типа 1, прибывший для своего обслуживания в отдаленный узел, превращается в запрос типа 2.
Введем величины:
Wsk - среднее время обработки сообщения k-го (k = 1,2) типа в узле Ks;
Usk - интенсивность поступления сообщений k-го (k = 1,2) типа во входную очередь узла Ks.
Тогда, аналогично вместо ограничения (27) в математической модели можно использовать следующее ограничение
![]() ,
,
где
![]() ;
;
![]() ;
;
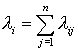 .
.
Рассмотрим построение модели оптимального распределения файлов по узлам вычислительной сети в случае, когда в качестве критерия оптимальности принимается общая стоимость трафика, порожденного функционированием вычислительной системы в течение единицы времени. Предположим, что топология вычислительной сети и схема обработки запросов те же, что и в разделе 1.
Пусть
п - число узлов сети;
т - число независимых файлов РБД;
Kj - j-ый узел сети;
Fi - i-ый
файл РБД;
Li - объем i-го файла;
bj - объем памяти узла Kj, предназначенной для размещения файлов;
lij - интенсивность запросов к файлу Fi, инициированных в узле Kj;
aij - объем запроса к файлу Fi,
инициированного на терминале узла Kj;
bij - объем
запрашиваемых данных при выполнении запроса к файлу Fi, поступившего на терминал узла Kj;
rsj - стоимость передачи единицы информации из узла Ks в узел Kj. (rss = 0, s = l,2,:,n);
Если xij (i = 1,2,...,т; j = 1,2,...,п) -
величины, определяемые по формуле
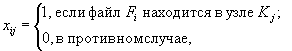
тогда объем пересылаемых данных при выполнении запроса к
файлу Fi, инициированного в узле Kj, равен (aij+bij)(1-xij). Поскольку интенсивность lij
порождает объем данных lij(aij+bij)(1-xij), нуждающихся в пересылке, то стоимость пересылки этих
данных равна
![]() ,
,
а общая стоимость данных, которые следует переслать по линиям связи между узлами вследствие функционирования системы в течение единицы времени, определяется формулой
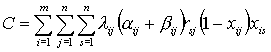 .
.
Таким образом, задача состоит
в том, чтобы найти минимум функции стоимости С при ограничениях (26), (27).