Язык SQL
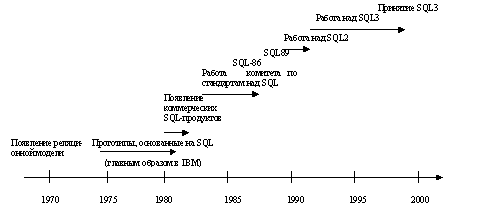
Ниже тезисно приведены основные вехи истории развития SQL.
Работа была начата сразу после появления статью Э.Кодда в 1970г. в лабораториях компании IBM для проверки возможностей реляционной модели.
СУБД System R - экспериментальная исследовательская система с языком SEQUEL (позже SQL), созданная IBM:
SQL в коммерческих реализациях:
1979 - Oracle (Relation Software Inc.- Oracle corp.;
1981-1982 - DB2 (IBM), Ingres - CA-OpenIngres (Relation Technology Inc. - Computer Associates)
1984 - Informix (Informix Sofrware);
1986 - Sybase (Sybase Corp.)
Стандартизация SQL:
Международный стандарт 1989 г.
Международный стандарт 1992 г.(SQL2)
В 1995 г. стандарт был дополнен спецификацией интерфейса уровня вызова (Call-Level Interface - SQL/CLI). SQL/CLI представляет собой набор спецификаций интерфейсов процедур, вызовы которых позволяют выполнять динамически задаваемые операторы SQL. По сути дела, SQL/CLI представляет собой альтернативу динамическому SQL и послужил основой для создания повсеместно распространенных сегодня интерфейсов ODBC (Open Database Connectivity) и JDBC (Java Database Connectivity).
В 1996 г. к стандарту SQL/92 был добавлен еще один компонент - SQL/PSM (Persistent Stored Modules). Основная цель этой спецификации состоит в том, чтобы стандартизировать способы определения и использования хранимых процедур, т. е. специальным образом оформленных программ, включающих операторы SQL, которые сохраняются в базе данных, могут вызываться приложениями и выполняются внутри СУБД.
Стандарт SQL:1999 (SQL3)
Незадолго до завершения работ по определению стандарта SQL2 была начата разработка стандарта SQL3. Реально работу над новым стандартом удалось частично завершить только в 1999 г., и по этой причине (а также в связи с проблемой 2000 года) стандарт получил название SQL:1999.
1999 г. были приняты пять первых частей стандарта SQL:1999. Первая часть (SQL/Framework) посвящена описанию концептуальной структуры стандарта: приводится развернутая аннотация следующих четырех частей.
Вторая часть SQL:1999 (SQL/Foundation) образует базис стандарта. Вводится система типов языка, формулируются правила определения функциональных зависимостей и возможных ключей, определяются синтаксис и семантика основных операторов SQL:
Третью часть занимает уточненная по сравнению с SQL/92 спецификация SQL/CLI. В четвертой части специфицируется SQL/PSM - синтаксис и семантика языка определения хранимых процедур (стандарт синтаксиса триггеров и процедур). Наконец, в пятой части - SQL/Bindings - определяются правила связывания SQL для стандартных версий языков программирования FORTRAN, COBOL, PL/1, Pascal, Ada, C и MUMPS.
В стандарт SQL:1999 не вошли и существуют в виде отдельных стандартов:
В конце 2003 г. был принят и опубликован новый вариант международного стандарта SQL:2003.
2. Некоторые правила использования языка SQL
1. Хорошо знайте свои данные и бизнес-приложение
2. Тестируйте свои запросы на реалистических данных.
3. Внимательно относитесь к использованию индексов на таблицах.
Постарайтесь создать все необходимые индексы. Создание индекса:
Создание индекса сводится к созданию набора данных, в котором указанные поля таблицы сортируются в соответствии с физическим расположением записи (rowid), что позволяет в последствии при поиске использовать бинарные и другие методы поиска.
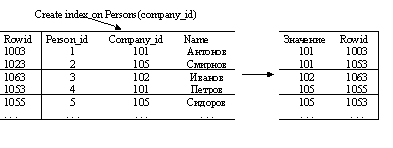
Запрос
потребует незначительного времени, поскольку значения индексов в наборе данных будут искаться как минимум двоичным поиском.
Однако слишком большое число индексов может привести к снижению эффективности. Основные правила:
4. Для фильтрации записей используйте WHERE, а не HAVING.
При использовании having вместе с group by на индексированных столбцах индекс не используется. Фильтруйте строки с помощью раздела where. Если для таблицы EMP существует индекс на столбце DEPTID, при выполнении следующего запроса этот индекс использоваться не будет:
HAVING DEPTID = 100;
Однако этот запрос можно переписать так, чтобы индекс применялся:
OUP BY DEPTID;
5. Минимизируйте число просмотров таблиц
Запросы с меньшим числом просмотров таблиц - более быстрые запросы. Вот пример. Таблица STUDENT содержит четыре столбца с именами NAME, STATUS, PARENT_INCOME и SELF_INCOME. Имя является первичным ключом. Значение статус равно 0 для обучающихся по бюджету студентов и 1 - для контрактников. Форма запроса предполагает два просмотра таблицы STUDENT:
UNION
SELECT NAME, SELF_INCOME
Тот же самый результат будет получен при выполнении запроса с одним просмотром таблицы:
6. Используйте специальные столбцы.
Помните, что доступ к строке по ROWID является самым быстрым. Вот пример оператора UPDATE, в котором используется сканирование по ROWID:
UPDATE EMPLOYEE
Значение ROWID в базе данных не является константой, поэтому не задавайте явных значений ROWID в операторах SQL и приложениях.
7. Избыточность полезна.
Помещайте в раздел WHERE как можно больше информации. Например, если указан раздел
оптимизатор сможет вывести, что COL2 = 10.
Но при задании раздела в форме
оптимизатор не будет считать, что COL1 = COL3.
8. Где возможно, избегайте использования соединений
Пример. Найти всех сотрудников некоторой организации
And Company.name="Sony"
При условии: Persons - N (1000) строк, Companies -M (100) строк портребуется проверка N*M строк (1 000 000)
потребует проверки N+M строк (1100).
9. Если это неизбежно, соединяйте таблицы в правильном порядке.
Порядок соединения таблиц в запросах с соединениями нескольких таблиц имеет критическое значение. Всегда следует выполнять сначала максимально ограничивающий поиск, чтобы отфильтровать как можно большее число строк на ранних фазах выполнения запроса с соединениями. Тогда на следующих фазах соединения оптимизатору придется иметь дело с меньшим числом строк, что повысит эффективность. Следует убедиться, что главная таблица (просматриваемая во внешнем цикле соединения на основе вложенных циклов) содержит наименьшее число строк.
10. Поскольку не всегда можно заменить запрос с соединением на более простой, как в п.7 зачастую выгоднее разбить сложный запрос на несколько простых с использованием, возможно, временных таблиц.
11. Старайтесь писать как можно более простые и тупые операторы SQL.
Оптимизатор может не справиться со слишком сложными операторами SQL; иногда написание нескольких более простых операторов позволяет добиться лучшей эффективности, чем задание одного сложного оператора. Основанный на оценках на оценках оптимизатор СУБД не является абсолютно устойчивым.
3. Достоинства и недостатки SQL
Достоинства:
Недостатки: