Часть YII-2. Интеллектуальный
анализ данных (Data Mining)
Большинство организаций
накапливают за время своей деятельности огромные объемы данных, но единственное
что они хотят от них получить – это информация. Интеллектуальный анализ
данных (Data Mining – добыча знаний) – это процесс поддержки принятия
решений, основанный на поиске в данных скрытых знаний, которые ранее не были
известны, нетривиальны, практически полезны, доступны для интерпретации
человеком (Г.Пиатецкий-Шапиро). Синонимами Data Mining являются слова
"обнаружение знаний в базах данных" (knowledge discovery in
databases) и "интеллектуальный анализ данных". При этом накопленные
сведения автоматически обобщаются до информации, которая может быть
охарактеризована как знания.
1. Модели Data Mining
Существует да вида моделей:
предсказательные и описательные.
Предсказательные (predictive) модели строятся на основании набора данных с
известными результатами и используются для предсказания результатов на
основании других наборов данных. При этом, естественно, требуется, чтобы модель
работала максимально точно, была статистически значима и т.д.
К ним относятся:
-
Модели
классификация – описывают правила или набор правил, в соответствии с которыми
можно отнести описание любого нового объекта к одному из классов. Такие правила
строятся на основании информации о существующих объектах путем разбиения их на
классы.
-
Модели последовательностей – описывает функции, позволяющие
прогнозировать изменение непрерывных числовых параметров. Они строятся на
основании данных об изменении некоторого параметра за прошедший период времени.
Описательные
модели уделяют внимание сути зависимостей в наборе данных, взаимному влиянию
различных факторов.
К ним относятся
следующие виды моделей:
-
Регрессионные
модели – описывают функциональные зависимости
между зависимыми и независимыми показателями и переменными в понятной человеку
форме. Необходимо заметить, что такие модели описывают функциональную
зависимость не только между непрерывными числовыми параметрами, но и между
категориальными.
-
Модели
кластеризации – описывают группы (кластеры), на которые
можно разделить объекты, данные о которых подвергаются анализу. Группируются
объекты (наблюдения, события) на основе данных (свойств), описывающих сущность
объектов. Объекты внутри кластера должны быть "похожими" друг на
друга и отличаться от объектов, вошедших в другие кластеры. Чем больше похожи
объекты внутри кластера и чем больше отличий между кластерами, тем точнее
кластеризация
-
Модели ассоциации – выявление закономерностей между
связанными событиями. Примером такой закономерности служит правило,
указывающее, что из события X следует событие Y. Такие
правила называются ассоциативными.
2. Практическое применение Data Mining
2.1. Интернет-технологии
В системах
электронного бизнеса, где особую важность имеют вопросы привлечения и удержания
клиентов, технологии Data Mining часто применяются для построения
рекомендательных систем интернет-магазинов и для решения проблемы
персонализации посетителей Web-сайтов. Рекомендации товаров и услуг, построенные на основе
закономерностей в покупках клиентов, обладают огромной убеждающей силой. Статистика
показывает, что почти каждый посетитель магазина Amazon не упускает возможности посмотреть на то,
что же купили "Customers who bought this book also bought...". Персонализация клиентов,
другими словами, автоматическое распознание принадлежности клиента к
определенной целевой аудитории позволяет компании проводить более гибкую
маркетинговую политику.
Поскольку в
электронной коммерции деньги и платежные системы также электронные, то важной
задачей становится обеспечение безопасности при операциях с пластиковыми карточками.
Data Mining позволяет обнаруживать случаи
мошенничества (fraud detection). В области электронной коммерции также остаются справедливыми
все методологии Data Mining,
разработанные для обычного маркетинга.
С другой
стороны, эта область тесно связана с понятием Web Mining. Специфика Web Mining заключается в применении традиционных
технологий Data Mining
для анализа крайне неоднородной, распределенной и значительной по объему
информации, содержащейся на Web-узлах. Здесь можно выделить два направления. Это Web Content Mining и Web Usage Mining.
В первом случае
речь идет об автоматическом поиске и извлечении качественной информации из
перегруженных "информационным шумом" источников Интернет, а также о
всевозможных средствах автоматической классификации и аннотировании
документов. Данное направление также называют Text Mining.
Web Usage Mining
направлен на обнаружение закономерностей в поведении пользователей конкретного Web-узла (группы узлов), в частности на то,
какие страницы и в какой временной последовательности запрашиваются
пользователями и какими группами пользователей.
2.2. Торговля
Для успешного
продвижения товаров всегда важно знать, что и как продается, а также, кто
является потребителем. Исчерпывающий ответ на первый вопрос дают такие
средства Data Mining,
как анализ рыночных корзин и сиквенциальный анализ. Зная связи между покупками
и временные закономерности, можно оптимальным образом регулировать
предложение. С другой стороны, маркетинг имеет возможность непосредственно
управлять спросом, но для этого необходимо знать как можно больше о
потребителях – целевой аудитории маркетинга. Data Mining позволяет решать задачи выделения групп
потребителей со схожими стереотипами поведения, т.е. сегментировать рынок. Для этого можно применять такие
технологии Data Mining,
как кластеризацию и классификацию.
Сиквенциальный
анализ помогает торговым предприятиям принимать решения о создании товарных
запасов. Он дает ответы на вопросы типа "Если сегодня покупатель приобрел
видеокамеру, то через какое время он вероятнее всего купит новые батарейки и
пленку?"
2.3. Телекоммуникации
Телекоммуникационный
бизнес является одной из наиболее динамически развивающихся областей
современной экономики. Поэтому традиционные проблемы, с которыми сталкивается
в своей деятельности любая компания, здесь ощущаются особо остро. Телекоммуникационные
компании работают в условиях жесткой конкуренции, что проявляется в ежегодном
оттоке около 25 % клиентов. При этом известно, что удержать клиента в 4-5 раз
дешевле, чем привлечь нового, а вот вернуть ушедшего клиента будет стоить уже
в 50-100 раз больше, чем его удержать. Далее, как и в целом в экономике,
справедливо правило – только 20 % клиентов приносят компании основной доход.
Помимо этого, существует ряд клиентов, наносящих компании прямой вред. По
разного рода оценкам порядка 10% всего дохода телекоммуникационной индустрии в
год теряется из-за случаев мошенничества (несколько млрдю $). Таким образом,
использование технологий Data Mining, направленных как на анализ доходности и
риска клиентов (churn prevention), так и на защиту от мошенничества (fraud detection), сэкономит компании огромные средства.
Еще один из
распространенных способов использования методов Data Mining – это анализ записей о подробных
характеристиках вызовов. Назначение такого анализа – выявление категорий
клиентов с похожими стереотипами пользования услугами и разработка
привлекательных наборов цен и услуг.
2.4. Промышленное
производство
Промышленное
производство создает идеальные условия для применения технологий Data Mining. Причина – в самой природе
технологического процесса, который должен быть воспроизводимым и
контролируемым. Все отклонения в течение процесса, влияющие на качество
выходного результата, также находятся в заранее известных пределах. Таким
образом, создается статистическая стабильность.
Естественно, что
в таких условиях использование Data Mining способно дать лучшие результаты, чем, к
примеру, при прогнозировании ухода клиентов телекоммуникационных компаний. В
последнем случае причинами ухода могут стать не предрасположенности к смене
мест, присущие целым группам абонентов, а внешние, совершенно случайные, и
поэтому не образующие никаких закономерностей обстоятельства (например, удачно
проведенная конкурентами рекламная кампания, экономические кризисы и т.д).
Примером использования
Data Mining в промышленности может быть
прогнозирование качества изделия в зависимости от замеряемых параметров
технологического процесса.
Другим
направлением использования технологий Data Mining является развитие
экспертно-диагностических систем для управления технологическими процессами и
контроля качества. Промышленные экспертные системы, построенные главным образом
на основе правил и прецедентов, служат для непрерывного мониторинга технологической
ситуации, отслеживания состояния оборудования, предупреждения и развития
аварийных ситуаций, своевременного оповещения персонала о появлении отклонений,
предоставления рекомендаций для их устранения, регистрации плановых и внеплановых
остановов и обнаружение внезапных изменений технологических параметров.
2.5. Медицина
В медицинских и
биологических исследованиях, равно как и в практической медицине, спектр
решаемых задач настолько широк, что возможно использование любых методологий Data Mining. Примером может служить построение
диагностических систем или исследование эффективности хирургического
вмешательства.
Известно много
экспертных систем для постановки медицинских диагнозов. Они построены главным
образом на основе правил, описывающих сочетания различных симптомов отдельных
заболеваний. С помощью таких правил узнают не только, чем болен пациент, но и
как нужно его лечить. Правила помогают выбирать средства медикаментозного
воздействия, определять показания/противопоказания, ориентироваться в лечебных
процедурах, создавать условия наиболее эффективного лечения, предсказывать
исходы назначенного курса лечения и т. п. Технологии Data Mining позволяют обнаруживать в медицинских
данных шаблоны, составляющие основу указанных правил.
Одним из
наиболее передовых направлений медицины является биоинформатика – область
науки, занимающаяся анализом и систематизацией генетической информации структур
и функций макромолекул с целью последующего объяснения различных биологических
явлений и создания новых лекарственных препаратов (Drug Design). Абстрагируясь от конкретного
содержания информации, исследуемой биоинформатикой, ее можно рассматривать как
набор генетических текстов о последовательностях ДНК и первичной структуре
белков, состоящих из протяженных символьных последовательностей. Выявление
структурных закономерностей в таких последовательностях входит в число задач,
эффективно решаемых средствами Data Mining, например, с помощью сиквенциального и
ассоциативного анализа.
2.6. Банковское дело
Классическим
примером использования Data Mining на практике является решение проблемы о
возможной некредитоспособности клиентов банка. Этот вопрос, тревожащий любого
сотрудника кредитного отдела банка, можно разрешить и интуитивно. Если образ клиента
в сознании банковского служащего соответствует его представлению о
кредитоспособном клиенте, то кредит выдавать можно, иначе – отказать. По
схожей схеме, но более продуктивно и объективно, работают установленные в
банках системы поддержки принятия решений со встроенной функциональностью Data Mining. Лишенные субъективной предвзятости, они
опираются в своей работе только на историческую базу данных банка, где
записывается детальная информация о каждом клиенте и в конечном итоге факт его
кредитоспособности. Классификационные алгоритмы Data Mining обрабатывают эти данные, и полученные
результаты используются далее для принятия решений.
Анализ
кредитного риска заключается, прежде всего, в оценке кредитоспособности
заемщика. Эта задача решается на основе анализа накопленной информации, т. е.
кредитной истории "прошлых" клиентов. С помощью инструментов Data Mining (деревья решений, кластерный анализ,
нейронные сети и др.) банк может получить профили добросовестных и
неблагонадежных заемщиков. Кроме того, возможно классифицировать заемщика по
группам риска, а значит, не только решить вопрос о возможности кредитования, но
и установить лимит кредита, проценты по нему и срок возврата.
Другой проблемой
банков является мошенничество с кредитными карточками, убытки от которого
измеряются миллионами долларов ежегодно, а рост количества мошеннических
операций составляет, по оценкам экспертов, от 15 до 25 % ежегодно.
В борьбе с
мошенничеством технология Data Mining использует стереотипы подозрительных
операций, созданные в результате анализа огромного количества транзакций – как
законных, так и неправомерных. Исследуется не только отдельно взятая операция,
но и совокупность последовательных во времени транзакций. Кроме того, алгоритмы
и модели (например, нейронные сети), имеющиеся в составе продуктов Data Mining, способны тестироваться и самообучаться.
При попытке совершения подозрительной операции средства Data Mining оперативно выдают предупреждение об этом,
что позволяет банку предотвратить незаконные действия, а не устранять их
последствия.
2.7. Страховой бизнес
В страховании,
так же как в банковском деле и маркетинге, возникает задача обработки больших
объемов информации для определения типичных групп (профилей) клиентов. Эта
информация используется для того, чтобы предлагать определенные услуги
страхования с наименьшим для компании риском и, возможно, с пользой для
клиента. Также с помощью технологий Data Mining решается такая часто встречающаяся в
страховании задача, как определение случаев мошенничества (fraud detection).
3. Методы
анализа данных
I. Базовые методы
-
алгоритмы,
основанные на переборе (О (2N) операций, где N – количество
объектов); использование разного вида эвристик, приводящих к сокращению
перебора;
-
подходы,
использующие элементы теории статистики (классический корреляционный,
регрессионный и другие виды статистического анализа).
II. Специальные методы
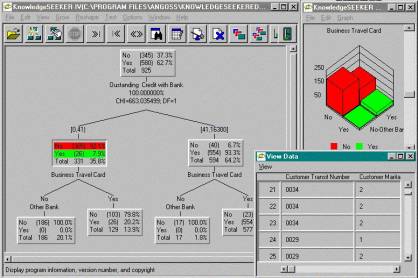
3.1. Деревья решений (decision trees)
Деревья
решения являются одним из наиболее популярных подходов к решению
задач Data Mining. Метод используется прежде всего для решения задач
классификации, но не только.
В результате применения этого метода к
обучающей выборке данных создается иерархическая структура классифицирующих
правил типа «ЕСЛИ... ТО...», имеющая вид дерева (это похоже на определитель
видов из ботаники или зоологии). Для принятия решения, к какому классу отнести
некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах
этого дерева, начиная с его корня.
Вопросы могут иметь вид «значение параметра A больше x?» для случая
измеряемых переменных или вида «значение переменной В принадлежит подмножеству
признаков С». Если ответ положительный, мы переходим к правому узлу следующего
уровня, если отрицательный – то к левому узлу; затем снова отвечаем на вопрос,
связанный с соответствующим узлом. Таким образом мы, в конце концов, доходим до
одного из оконечных узлов – листьев, где стоит указание, к какому классу
(сочетанию признаков) надо отнести рассматриваемый объект. Этот метод хорош
тем, что такое представление правил наглядно и его легко понять.
3.2. Нейронные
сети
Нейронные
сети относятся к классу нелинейных адаптивных систем, основанных на
биологической аналогии с мозгом человека с архитектурой, условно имитирующей
нервную ткань из нейронов. Математическая модель нейрона представляет собой
некоторый универсальный нелинейный элемент с возможностью широкого изменения и
настройки его характеристик. В одной из наиболее распространенных нейросетевых
архитектур – многослойном персептроне с обратным распространением ошибки –
эмулируется работа нейронов в составе иерархической сети, где каждый нейрон
более высокого уровня соединен своими входами с выходами нейронов нижележащего
слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на
основе которых производятся вычисления, необходимые для принятия решений,
прогнозирования развития ситуации и т.д. Эти значения рассматриваются как
сигналы, передающиеся в вышележащий слой, ослабляясь или усиливаясь в
зависимости от числовых значений (весов), приписываемых межнейронным связям. В
результате этого на выходе нейрона самого верхнего слоя вырабатывается
некоторое значение, которое рассматривается как ответ, реакция всей сети на
введенные значения входных параметров.
Типы нейросетей
Искусственный
нейрон задается совокупностью своих входов, весами входов, функцией состояния s
и функцией активации f. Функция состояния определяет состояние нейрона в зависимости
от значений его входов, весов входов и, возможно, предыдущих состояний.
Наиболее часто используются функции состояния, не зависящие от предыдущего
состояния, вычисляемые либо как сумма произведений значений входов на веса
соответствующих входов по всем входам, либо как расстояние между вектором
входов и вектором весов входов, измеряемое в какой-либо метрике.
Одноместная функция активации у = f(s) определяет выходной сигнал
нейрона как функцию его состояния s. Наиболее распространенными
функциями активации являются ступенчатая пороговая, линейная пороговая,
сигмоидная, я также линейная и гауссиана, приведенные в таблице.
|
Название |
Определение |
|
Ступенчатая пороговая |
y=0 при s<a, y=1 при s>=a |
|
Линейная пороговая |
y=0 при s<a1, y=ks+b
при a1<=s<a2, y=1 при s>=a2 |
|
Сигмоидальная |
y=(1+ek(s-a))-1 |
|
Линейная |
y=ks+b |
|
Гауссиана |
y=ek(s-a)2 |
Линейные
нейронные сети используют нейроны с линейной функцией активации. Нелинейные
применяют нелинейную функцию активации, например, пороговую или сигмоидную.
Нейронная сеть образуется путем объединения ориентированными
взвешенными ребрами выходов нейронов с входами. При этом граф межнейронных
соединений может быть ациклическим либо произвольным циклическим. Вид графа
служит одним из классификационных признаков типа нейронной сети, разделяющим
сети на сети без циклов и циклические. Примеры нейронных сетей обоих типов
приведены ниже.
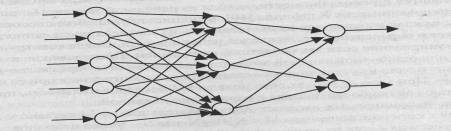
Пример нейронной сети без циклов
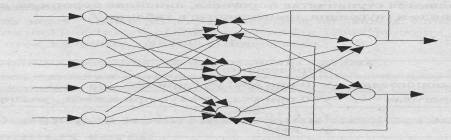
Пример циклической нейронной сети
Приняв некоторое
соглашение о тактировании сети (времени срабатывания нейронов), можно получить
аппарат для задания алгоритмов посредством нейронных сетей. Разнообразие этих
алгоритмов ничем не ограничено, так как можно использовать нейроны с
различными функциями активации, различными функциями состояния, двоичными,
целочисленными, вещественными и другими значениями весов и входов. Поэтому в
терминах нейронных сетей можно описывать решение как хорошо формализованных
задач, например, задач математической физики, так и плохо формализуемых задач
распознавания, классификации, обобщения и ассоциативного запоминания.
Сети могут быть
конструируемыми или обучаемыми. В конструируемой сети число и тип нейронов,
граф межнейронных связей, веса входов нейронов определяются при создании сети,
исходя из решаемой задачи. Например, при конструировании сети Хопфилда,
функционирующей как ассоциативная память, каждая входная последовательность из
заранее определенного набора участвует в определении весов входов нейронов
сети. После конструирования функционирование сети заключается в следующем. При
подаче на входы входной последовательности сеть через какое-то время переходит
в одно из устойчивых состояний, предусмотренных при ее конструировании. При
этом на входах сети появляется последовательность, признаваемая сетью как
наиболее близкая к изначально поданной.
В обучаемых сетях их
графы межнейронных связей и веса входов изменяются при выполнении алгоритма обучения.
Процесс обучения состоит в подборе весов межнейронных связей, обеспечивающих
наибольшую близость ответов сети к известным правильным ответам. Для каждого сочетания обучающих данных на входе выходные значения
сравниваются с известным результатом. Если они различаются, то вычисляется
корректирующее воздействие, учитываемое при обработке в узлах сети. Указанные
шаги повторяются, пока не выполнится условие останова, например необходимая
коррекция не будет превышать заданной величины. После обучения на имеющихся
данных сеть готова к работе и может использоваться для построения прогнозов.
Одно из
главных преимуществ нейронных сетей состоит в том, что они, по крайней мере
теоретически, могут аппроксимировать любую непрерывную функцию, и поэтому
исследователю нет необходимости заранее принимать какие-либо гипотезы
относительно модели и даже, в ряде случаев, о том, какие переменные
действительно важны.
Нейронные
сети представляют собой типичный пример модели "черного ящика", когда
основное внимание сосредотачивается исключительно на практическом результате,
в данном случае на точности прогнозов, а не на сути механизмов, лежащих в
основе явления или соответствии полученных результатов какой-либо имеющейся
теории.
Недостатками
нейронных сетей являются
-
то обстоятельство,
что окончательное решение зависит от начальных установок сети;
-
необходимость
иметь очень большой объем обучающей выборки;
-
даже
натренированная нейронная сеть представляет собой черный ящик со всеми
вытекающими отсюда последствиями.
3.3. Нечеткая
логика
Нечеткая
логика (fuzzy logic) – это надмножество
классической булевой логики. Она расширяет возможности классической логики,
позволяя применять концепцию неопределенности в логических выводах. Аппарат
нечеткой логики столь же строг и точен, как и классический, но вместе со
значениями "ложь" и "истина" он позволяет оперировать
значениями в промежутке между ними. Нечеткая логика применяется в тех случаях,
когда необходимо манипулировать степенью «может быть» в дополнении к «да» и
«нет».
Часто для
иллюстрации связи нечеткой логики с естественными представлениями человека об
окружающем мире приводят пример о пустыне. Определим понятие
"пустыня" как "бесплодная территория, покрытая песком". Теперь
рассмотрим простейшее высказывание: "Сахара – это пустыня". Нельзя не
согласиться с ним, принимая во внимание данное выше определение. Предположим,
что с поверхности Сахары удалена одна песчинка. Осталась ли Сахара пустыней?
Скорее всего, да. Продолжая удалять песчинки одну за другой, всякий раз оцениваем
справедливость приведенного ранее высказывания. По прошествии определенного
промежутка времени песка в Сахаре не останется и высказывание станет ложным. Но
после какой именно песчинки его истинность меняется? В реальной жизни с
удалением одной песчинки пустыня не исчезает. Пример показывает, что
традиционная логика не всегда согласуется с представлениями человека. Для
оценки степени истинности высказываний естественный язык имеет специальные
средства (некоторые наречия и обороты, например: "в некоторой
степени", "очень" и др.).
Одно из базовых
понятий традиционной логики – понятие подмножества. Подобно этому в основе
нечеткой логики лежит теория нечетких подмножеств (нечетких множеств). Эта
теория занимается рассмотрением множеств, определяемых небинарными отношениями
вхождения. Это означает, что принимается во внимание не просто то, входит
элемент во множество или не входит, но и степень его вхождения, которая может
изменяться от 0 до 1.
Пусть S – множество с конечным числом элементов, S={s1,s2,..., sn), где п – число элементов (мощность) множества S. В классической теории множеств подмножество U множества S может быть определено как отображение
элементов S на множество В = {0,1}:
U: S => B.
Это отображение
может быть представлено множеством упорядоченных пар:
{si, mUшi},
i Î
[1, n],
где si –
i-й элемент множества S; n –
мощность множества S; mUi. – элемент множества В =
{0, 1}. Если mUi = 1, то si является элементом подмножества U. Элемент "0" множества В используется для обозначения того, что si не входит в подмножество U. Проверка истинности предиката "sk Î U"
осуществляется путем нахождения пары, в которой sk – первый элемент. Если для этой пары mUk = 1, то значением предиката будет
"истина", в противном случае – "ложь".
Если U – подмножество S, то U может быть
представлено n-мерным
вектором (mU1, mU2,..., mUn), где i-й элемент вектора равен "1",
если соответствующий элемент множества S входит и в U, и "0" в противном случае. Таким образом, U может быть однозначно представлено точкой в n-мерном бинарном гиперкубе Вn, В
= {0, 1}.
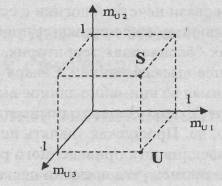
Графическое представление традиционного
множества.
Нечеткое подмножество F может быть
представлено как отображение элементов множества S на интервал I=[0,1]. Это
отображение определяется множеством упорядоченных пар:
{ si , mF(si)},
i Î
[1, n],
где si – i-й элемент множества S; n – мощность множества S; mF(si) Î
[0, 1] – степень
вхождения элемента si в множество F. Значение mF(si), равное 1, означает полное вхождение, mF(si)=0 указывает на то, что элемент si не принадлежит множеству F. Часто
отображение задается функцией mF(x) принадлежности х нечеткому
множеству F. В силу этого термины "нечеткое
подмножество" и "функция принадлежности" употребляются как
синонимы. Степень истинности предиката "sk Î F" определяется путем нахождения парного элементу sk значения mF(sk), определяющего степень вхождения sk в F.
Обобщая
геометрическую интерпретацию традиционного подмножества на нечеткий случай,
получаем представление F точкой в гиперкубе In, I = [0,1]. В отличие от традиционных подмножеств точки,
изображающие нечеткие подмножества, могут находиться не только на вершинах
гиперкуба, но и внутри него.
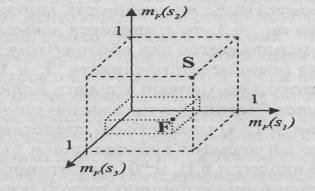
Графическое представление
нечеткого множества.
Рассмотрим
пример определения нечеткого подмножества. Имеется множество всех людей S. Определим нечеткое подмножество Т всех высоких людей
этого множества. Введем для каждого человека степень его принадлежности
подмножеству Т. Для этого зададим функцию принадлежности mT(h), определяющую, в
какой степени можно считать высоким человека ростом h сантиметров.
![]()
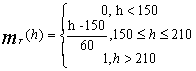
где h – рост конкретного человека в
сантиметрах.
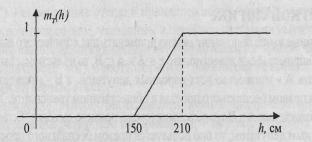
График функции принадлежности
Пусть рост
Михаила – 163 см, тогда истинность высказывания "Михаил высок" будет
равна 0.21. Использованная в данном случае функция принадлежности тривиальна.
При решении большинства реальных задач подобные функции имеют более сложный
вид, кроме того, число их аргументов может быть большим.
Методы
построения функций принадлежности для нечетких подмножеств довольно
разнообразны. В большинстве случаев они отражают субъективные представления
экспертов о предметной области. Так, например, кому-то человек ростом 180 см
может показаться высоким, а кому-то – нет. Однако часто такая субъективность помогает
снизить степень неопределенности при решении слабо формализованных задач. Как
правило, для задания функций принадлежности используются типовые зависимости,
параметры которых определяются путем обработки мнений экспертов.
Необходимо
осознавать разницу между нечеткой логикой и теорией вероятностей. Заключается
она в различии понятий вероятности и степени принадлежности. Вероятность определяет,
насколько возможен один из нескольких взаимоисключающих исходов или одно из
множества значений. Например, может определяться вероятность того, что
утверждение истинно. Утверждение может быть либо истинным, либо ложным. Степень
принадлежности показывает, насколько то или иное значение принадлежит
определенному классу (подмножеству). Например, при определении истинности
утверждения ее возможные значения не ограничены "ложью" и
"истиной", а могут попадать и в промежуток между ними. Еще одно
различие выражено в математических свойствах этих понятий. В отличие от
вероятности для степени принадлежности не требуется выполнение аксиомы
аддитивности.
3.4. Генетические
алгоритмы
Эволюционные вычисления и традиционные
методы оптимизации
Принятие
решения в большинстве случаев заключается в генерации всех возможных
альтернатив решений, их оценке и выборе лучшей среди них. Принять
"правильное" решение – значит выбрать такой вариант из числа возможных,
в котором с учетом всех разнообразных факторов и противоречивых требований
будет оптимизирована некая общая ценность, то есть решение будет в максимальной
степени способствовать достижению поставленной цели.
С появлением и
развитием вычислительной техники указанные процессы генерации и выбора
альтернатив решений стали реализовываться на компьютерах. В связи с этим
появились новые задачи формализации и алгоритмизации процесса принятия
решений, которые сейчас составляют отдельную большую область исследований.
Формализация
той или иной поставленной задачи, как правило, предполагает описание всех
важных факторов, влияющих на достижение цели, их взаимодействия, ограничительных
условий и критерия оценки качества принимаемого решения, на основе которого
можно осуществлять выбор между альтернативами. Обычно в качестве критерия
оценки выступает некая целевая функция, аргументами которой являются
количественные характеристики, описывающие состояние факторов, влияющих на
достижение цели в решаемой задаче. При этом решению, приводящему к наилучшему
результату, как правило, соответствует экстремальное значение целевой функции,
то есть точка ее максимума или минимума.
Еще задолго до
появления вычислительной техники были созданы формальные методы поиска
оптимальных решений, в основе которых лежали математические вычисления,
позволяющие находить экстремум целевой функции.
На сегодняшний
день можно выделить три основных типа методов поиска оптимальных решений:
-
методы,
основанные на математических вычислениях;
-
перечислительные
методы;
-
методы,
использующие элемент случайности.
Методы,
основанные на математических вычислениях, изучены наиболее полно.
К недостаткам
этих методов можно отнести очень жесткие условия, накладываемые на целевую
функцию. Она должна быть дифференцируема на всем пространстве поиска. При
формализации современных задач это условие, как правило, соблюсти не удается.
Кроме того, данные методы находят лишь локальные экстремумы целевой функции,
тогда как оптимальному решению соответствует только глобальный экстремум.
Перечислительные
методы также изучены достаточно подробно и имеют множество видов и форм. Их
основная идея состоит в том, что пространство поиска любой задачи можно
представить в виде совокупности дискретных точек. В этом случае поиск решения
будет сводиться к перебору всех точек пространства поиска и вычислению в них
целевой функции, в одной из которых она, несомненно, примет экстремальное
значение.
Недостаток этих
методов очевиден. При увеличении размерности пространства поиска (числа
аргументов целевой функции) количество точек пространства значительно
увеличивается.
В основе
методов, использующих элементы случайности, лежит случайный поиск в пространстве
задачи с сохранением наилучшего полученного результата. Очевидно, что
применение такого метода не гарантирует получения оптимального решения.
Вместе с тем
следует заметить, что сейчас при решении очень сложных задач основной целью
является поиск уже не оптимального, а более "хорошего” решения по
сравнению с полученным ранее или заданным в качестве начального. Здесь методы,
использующие элемент случайности, получают определенное преимущество перед
остальными. Однако даже с такими допущениями непосредственный случайный поиск
является малоэффективным. Исследования показали, что внесение в такие методы
элементов детерминированности дает значительное улучшение показателей. Одним
из типов таких "частично" случайных методов являются эволюционные
вычисления.
Эволюционные
вычисления – термин, обычно используемый для общего описания алгоритмов поиска,
оптимизации или обучения, основанных на некоторых формализованных принципах
естественного эволюционного процесса. Основное преимущество эволюционных вычислений
в этой области заключается в возможности решения многомодальных (имеющих
несколько локальных экстремумов) задач с большой размерностью за счет сочетания
элементов случайности и детерминированности точно так, как это происходит в
природной среде.
Детерминированность
этих методов заключается в моделировании природных процессов отбора,
размножения и наследования, происходящих по строго определенным правилам.
Основным правилом при этом является закон эволюции: "выживает
сильнейший", который обеспечивает улучшение находимого решения. Другим
важным фактором эффективности эволюционных вычислений является моделирование
размножения и наследования. Рассматриваемые варианты решений могут по
определенному правилу порождать новые решения, которые будут наследовать
лучшие черты своих "предков".
В качестве
случайного элемента в методах эволюционных вычислений может использоваться,
например, моделирование процесса мутации. В этом случае характеристики того
или иного решения могут быть случайно изменены, что приведет к новому
направлению в процессе эволюции решений и может ускорить процесс выработки
лучшего решения.
Среди этих
моделей эволюционных вычислений можно выделить три основные парадигмы:
-
генетические
алгоритмы;
-
эволюционные
стратегии;
-
эволюционное
программирование.
Основное
отличие генетических алгоритмов заключается в представлении любой альтернативы
решения в виде битовой строки фиксированной длины, манипуляции с которой
производятся в отсутствие всякой связи с ее смысловой интерпретацией. То есть в
данном случае применяется единое универсальное представление любой задачи.
Эволюционные
стратегии, напротив, оперируют объектами, тесно связанными с решаемой задачей.
Каждая из альтернатив решения представляется единым массивом численных
параметров, за каждым из которых скрывается, по сути, аргумент целевой функции.
Воздействие на данные массивы осуществляется, в отличие от генетических
алгоритмов, с учетом их смыслового содержания и направлено на улучшение
значений входящих в них параметров.
В основе направления
эволюционного программирования лежит идея представления альтернатив в виде
универсальных конечных автоматов, способных реагировать на стимулы, поступающие
из окружающей среды. Соответствующим образом разрабатывались и операторы
воздействия на них.
Отрицательной
чертой эволюционных вычислений является то, что они представляют собой, скорее,
подход к решению задач оптимизации, чем алгоритм. И вследствие этого требуют
адаптации к каждому конкретному классу задач путем выбора определенных
характеристик и параметров, речь о которых применительно к генетическим
алгоритмам пойдет ниже.
Основы теории генетических
алгоритмов
Генетические
алгоритмы, являясь одной из парадигм эволюционных вычислений, представляют
собой алгоритмы поиска, построенные на принципах, сходных с принципами
естественного отбора и генетики. Дополнительным свойством этих алгоритмов
является невмешательство человека в развивающийся процесс поиска. Человек может
влиять на него лишь опосредованно, задавая определенные параметры.
Будучи
разновидностью методов поиска с элементами случайности, генетические алгоритмы
имеют целью нахождение лучшего, а не оптимального решения задачи. Это связано с
тем, что для сложной системы часто требуется найти хоть какое-нибудь
удовлетворительное решение, а проблема достижения оптимума отходит на второй
план. При этом другие методы, ориентированные на поиск именно оптимального
решения, вследствие чрезвычайной сложности задачи становятся вообще
неприменимыми.
Генетические
алгоритмы имеют четыре основных отличия от традиционных методов.
1. Генетические
алгоритмы работают с кодами, в которых представлен набор параметров, напрямую
зависящих от аргументов целевой функции. Причем интерпретация этих кодов
происходит только перед началом работы алгоритма и после завершения его работы
для получения результата. В процессе работы манипуляции с кодами происходят
совершенно независимо от их интерпретации, код рассматривается просто как
битовая строка.
2. Для поиска
генетический алгоритм использует несколько точек поискового пространства
одновременно, а не переходит от точки к точке, как это делается в традиционных
методах. Это позволяет преодолеть один из их недостатков - опасность попадания
в локальный экстремум целевой функции.
3. Генетические
алгоритмы в процессе работы не используют никакой дополнительной информации,
что повышает скорость работы. Единственной используемой информацией может быть
область допустимых значений параметров и целевой функции в произвольной точке.
4. Генетический
алгоритм использует как вероятностные правила для порождения новых точек
анализа, так и детерминированные правила для перехода от одних точек к другим..
Прежде чем
рассматривать непосредственно работу генетического алгоритма, введем ряд
терминов, которые широко используются в данной области.
Выше было
показано, что генетический алгоритм работает с кодами безотносительно их
смысловой интерпретации. Поэтому сам код и его структура описываются понятием
генотип, а его интерпретация, с точки зрения решаемой задачи, понятием фенотип.
Каждый код представляет, по сути, точку пространства поиска. С целью
максимально приблизиться к биологическим терминам, экземпляр кода называют
хромосомой, особью или индивидуумом. Далее для обозначения строки кода мы будем
в основном использовать термин "особь".
На каждом шаге
работы генетический алгоритм использует несколько точек поиска одновременно.
Совокупность этих точек является набором особей, который называется популяцией.
Количество особей в популяции называют размером популяции. На каждом шаге
работы генетический алгоритм обновляет популяцию путем создания новых особей и
уничтожения старых. Чтобы отличать популяции на каждом из шагов и сами эти
шаги, их называют поколениями и обычно идентифицируют по номеру. Например,
популяция, полученная из исходной популяции после первого шага работы
алгоритма, будет первым поколением, после следующего шага – вторым, и т.д.
В процессе
работы алгоритма генерация новых особей происходит на основе моделирования
процесса размножения. При этом, естественно, порождающие особи называются
родителями, а порожденные – потомками. Родительская пара, как правило,
порождает пару потомков. Непосредственная генерация новых кодовых строк из двух
выбранных происходит за счет работы оператора скрещивания, который также называют
кроссинговером (от англ. crossover). При порождении новой популяции оператор скрещивания
может применяться не ко всем парам родителей. Часть этих пар может переходить в
популяцию следующего поколения непосредственно. Насколько часто будет возникать
такая ситуация, зависит от значения вероятности применения оператора скрещивания,
которая является одним из параметров генетического алгоритма.
Моделирование
процесса мутации новых особей осуществляется за счет работы оператора мутации.
Основным параметром оператора мутации также является вероятность мутации.
Поскольку
размер популяции фиксирован, то порождение потомков должно сопровождаться
уничтожением других особей. Выбор пар родителей из популяции для порождения
потомков производит оператор отбора, а выбор особей для уничтожения – оператор
редукции. Основным параметром их работы является, как правило, качество особи,
которое определяется значением целевой функции в точке пространства поиска,
описываемой этой особью.
Ниже
перечислены основные понятия и термины, используемые в области генетических
алгоритмов:
-
генотип и
фенотип;
-
генотип и
фенотип;
-
особь и
качество особи;
-
популяция и
размер популяции;
-
поколение;
-
родители и
потомки.
К
характеристикам генетического алгоритма относятся:
-
размер
популяции;
-
оператор
скрещивания и вероятность его использования;
-
оператор
мутации и вероятность мутации;
-
оператор
отбора;
-
оператор
редукции;
-
критерий
останова.
Операторы
отбора, скрещивания, мутации и редукции называют еще генетическими операторами.
Критерием
останова работы генетического алгоритма может быть одно из трех событий:
-
сформировано
заданное пользователем число поколений;
-
популяция
достигла заданного пользователем качества (например, значение качества всех
особей превысило заданный порог);
-
достигнут
некоторый уровень сходимости, то есть особи в популяции стали настолько
подобными, что дальнейшее их улучшение происходит чрезвычайно медленно.
Формирование
исходной популяции происходит, как правило, с использованием какого-либо
случайного закона, на основе которого выбирается нужное количество точек
поискового пространства. Исходная популяция может также быть результатом работы
какого-либо другого алгоритма оптимизации. Общая схема работы генетического
алгоритма представлена ниже.
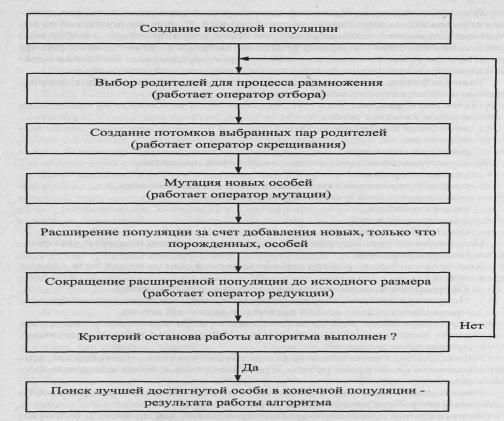
В основе
оператора отбора, который служит для выбора родительских пар и уничтожения
особей, лежит принцип "выживает сильнейший". В качестве примера можно
привести следующий оператор. Выбор особи для размножения производится случайно.
Вероятность участия особи в процессе размножения вычисляется по формуле:
![]()
где n – размер популяции, i – номер особи, Рi – вероятность участия особи в процессе
размножения, fj - значение целевой функции для i-й особи. Очевидно, что одна особь может быть задействована в
нескольких родительских парах.
Аналогично
может быть решен вопрос уничтожения особей. Вероятность уничтожения,
соответственно, должна быть обратно пропорциональна качеству особей. Однако
обычно происходит просто уничтожение особей с наихудшим качеством. Таким образом,
выбирая для размножения наиболее качественные особи и уничтожая наиболее
слабые, генетический алгоритм постоянно улучшает популяцию, ведя к нахождению
все лучших решений.
Ниже описан
простейший оператор скрещивания. Он выполняется в два этапа. Пусть особь
представляет собой строку из n элементов. На первом этапе равновероятно
выбирается натуральное число к от 1 до п-1. Это число называется точкой разбиения. В соответствии с ним
обе исходные строки разбиваются на две подстроки. На втором этапе строки обмениваются
своими подстроками, лежащими после точки разбиения, то есть элементами с k+1-го по n-й. В результате
получаются две новые строки, которые наследовали частично свойства обоих
родителей. Этот процесс проиллюстрирован ниже.
строка1 Х1Х2 ...
XkXk+1 ...
Xn à X1X2 ... XkYk+1 ... Yn
строка2 Y1Y2 ... YkYk+1 ... Yn à Y1Y2 ... YkXk+1 ... Xn
Вероятность
применения оператора скрещивания обычно выбирается достаточно большой, в пределах
от 0,9 до 1, чтобы обеспечить постоянное появление новых особей, расширяющих
пространство поиска. При значении вероятности меньше 1 часто используют
элитизм. Это особая стратегия, которая предполагает переход в популяцию
следующего поколения элиты, то есть лучших особей текущей популяции, без всяких
изменений. Применение элитизма способствует сохранению общего качества
популяции на высоком уровне. При этом элитные особи участвуют еще и в процессе
отбора родителей для последующего скрещивания. Количество элитных особей
определяется обычно по формуле:
K = (1-P)*N,
где К – количество элитных особей, Р – вероятность применения оператора
скрещивания, N – размер популяции.
В случае
использования элитизма все выбранные родительские пары подвергаются скрещиванию,
несмотря на то, что вероятность применения оператора скрещивания меньше 1. Это
позволяет сохранять размер популяции постоянным.
Оператор
мутации служит для моделирования природного процесса мутации. Его применение в
генетических алгоритмах обусловлено следующими соображениями. Исходная
популяция, какой бы большой она ни была, охватывает ограниченную область
пространства поиска. Оператор скрещивания, безусловно, расширяет эту область,
но все же до определенной степени, поскольку использует ограниченный набор
значений, заданный исходной популяцией. Внесение случайных изменений в особи
позволяет преодолеть это ограничение и иногда значительно сократить время
поиска или улучшить качество результата.
Как правило,
вероятность мутации, в отличие от вероятности скрещивания, выбирается
достаточно малой. Сам процесс мутации заключается в замене одного из элементов
строки на другое значение. Это может быть перестановка двух элементов в
строке, замена элемента строки значением элемента из другой строки, в случае
битовой строки может применяться инверсия одного из битов и т.д.
В процессе
работы алгоритма все указанные выше операторы применяются многократно и ведут
к постепенному изменению исходной популяции. Поскольку операторы отбора,
скрещивания, мутации и редукции по своей сути направлены на улучшение каждой
отдельной особи, то результатом их работы является постепенное улучшение
популяции. В этом и заключается основной смысл работы генетического алгоритма –
улучшить популяцию решений по сравнению с исходной.
После
завершения работы генетического алгоритма из конечной популяции выбирается та
особь, которая дает максимальное (или минимальное) значение целевой функции и
является, таким образом, результатом работы генетического алгоритма. За счет
того, что конечная популяция лучше исходной, полученный результат представляет
собой улучшенное решение.
Примеры решения задач
Описав смысл
терминов, понятий и характеристик генетического алгоритма, а также процесс его
работы, рассмотрим примеры решения некоторых оптимизационных задач с
использованием генетических алгоритмов, чтобы проиллюстрировать рассмотренные
положения (см. Генетические алгоритмы).