Параллельные системы баз данных
Возвращаемся к архитектуре MPP. На элементарном уровне идея обработки данных в MPP иcключительно проста: декомпозиция вычислительных задач на большое число параллельно выполняющихся операций.
В простейшем варианте - это мнопроцессорный компьютер (может быть и сложнее). В принципе архитектура MPP масштабируема до тысяч процессоров.
Вспомнить определение СУРБД (условие(2): узлы - независимые компьютеры со своими ОС, связанные сетью). Если снять это ограничение, получаем параллельную систему баз данных можно определить как реализацию СУБД для процессоров, составляющих многопроцессорную конфигурацию (многопроцессорного компьютера).
Замечание. Речь идет не просто о больших, а о очень больших базах данных, для поддержки которых разрабатываются специальные архитектуры и железо.
Предпосылка: реляционные запросы состоят из однородных операций над однородным потоком данных. Это делает возможным конвейерный параллелизм, при котором один оператор вычисляется параллельно с другим, и разнесенный параллелизм, при котором операторы дублируются для каждого источника данных и дубли выполняются параллельно. А MPP это позволяет реализовать.
1. Цели и параметры параллелизма: ускорение и расширяемость
Идеальная параллельная система обладает двумя главными свойствами:
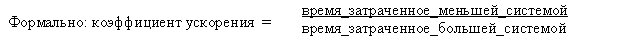
Ускорение называется линейным, если в N раз большая или более дорогая система обладает в N раз большим быстродействием.
Ускорение позволяет определить эффективность наращивания системы на сопоставимых задачах. Расширяемость позволяет измерять эффективность наращивания системы на больших задачах. Расширяемость определяется, как способность в N раз большей системы выполнять в N раз большую работу за то же время, что и исходная система. Коэффициент расширяемости измеряется, как

Если коэффициент расширяемости = 1, то расширяемость называется линейной.
Существуют два различных вида расширяемости: пакетная и транзакционная. Если суть работы состоит в выполнении большого количества небольших независимых запросов от многих пользователей к базе данных коллективного пользования, то свойство расширяемости состоит в удовлетворении в N раз большего числа запросов от большего в N раз числа клиентов к большей в N раз базе данных. Такая расширяемость характерна для систем транзакционной обработки запросов и систем с разделением времени и называется транзакционной.
Второй вид расширяемости, называемый пакетной расширяемостью, возникает, когда задача состоит в выполнении одной большой работы. Она характерна для запросов к базам данных, а также для задач математического моделирования. В этих случаях расширяемость состоит в использовании в N раз большего компьютера для решения в N раз большей задачи. Три барьера общего характера для линейного ускорения и линейного расширения ставятся тремя факторами:
Достижения линейного ускорения и линейной расширяется ограничивается тремя факторами:
Запуск: время, необходимое для запуска параллельной операции. Если нужно запустить тысячи процессоров, то реальное время вычислений может оказаться значительно меньше времени, требуемого для их запуска.
Помехи: появление каждого нового процесса ведет к замедлению всех остальных процессов, использующих те же ресурсы.
Перекос: с увеличением числа параллельных шагов средняя продолжительность выполнения каждого шага уменьшается, но отклонение от среднего значения может значительно превзойти само среднее значение. Время выполнения работы - это время выполнения наиболее медленного шага работы. Когда отклонение от средней продолжительности превосходит ее саму, то параллелизм позволяет только слегка убыстрить выполнение работы.
2. Аппаратная архитектура
Для построения расширяемых многопроцессорных систем в принципиальном плане возможны 3 архитектурных решения:
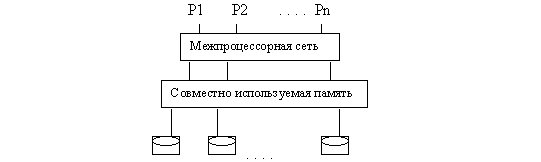
Мультипроцессор с разделением памяти соединяет все процессоры с глобальной совместно используемой памятью, причем все процессоры имеют доступ как к общей ОП, так и ко всем дискам. Типичными примерами машин с разделением памяти являются многопроцессорные компьютеры IBM/370, VAX и Sequent.
Системы с разделением дисков отводят каждому собственную память, но все процессоры могут непосредственно обращаться к любому диску. Примерами являются VAXcluster компании Digital и Sysplex компании IBM.

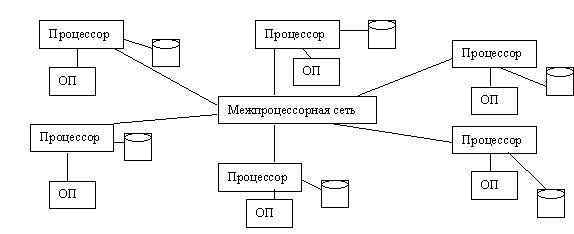
В системе без совместного использования ресурсов (первая схема) каждый процессор имеет свою собственную память и один или более дисков. Процессоры поддерживают связь через высокоскоростную соединительную сеть (Teradata, Tandem, nCUBE, VAXcluster).
Необходимой предпосылкой для достижения параллелизма является фрагментация данных. Разделение идет от централизованных систем, которые вынуждены разделять файлы, поскольку файл слишком велик для одного диска и потому что невозможно обеспечить приемлемую скорость доступа к фалу на одном диске. Обобщенная модель фрагментации для параллельных систем баз данных
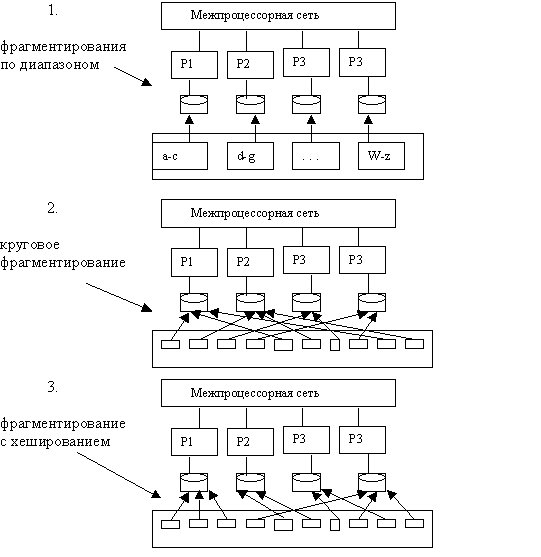
Выделяют схемы фрагментирования по диапазоном, круговое фрагментирование и фрагментирование с хешированием.
3. Параллелизм внутри реляционных операторов
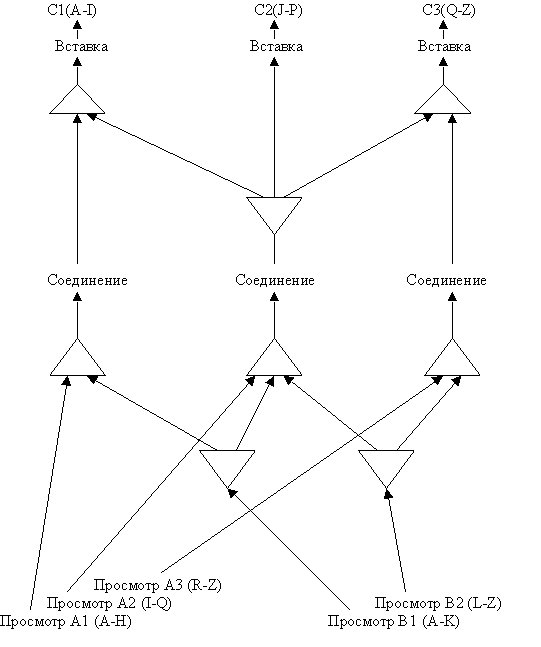
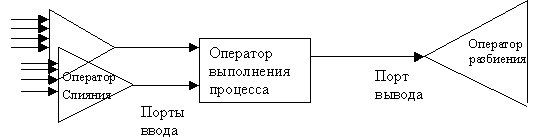
Основная идея состоит в использовании параллельных потоков данных вместо написания параллельных операторов (программ). Этот подход позволяет использовать без переделок существующие последовательные программы для параллельного выполнения реляционных операторов. Каждый реляционный оператор имеет набор портов ввода, на которые поступают входные кортежи, и порт вывода, на который посылается выходной поток оператора. Параллельный поток данных разделяется и сливается в потоки данных через последовательные порты. Такой подход позволяет параллельно выполнять существующие последовательные операторы.
Оператор слияния собирает данные в одном месте. Если требуется параллельно выполнить параллельную многофазную операцию, то единый поток данных должен быть расщеплен на несколько независимых потоков. Оператор расщепления используется для разделения или тиражирования потока кортежей, производимого реляционным оператором. Оператор расщепления определяет отображение одного или более значений атрибутов выходных кортежей на набор назначенных процессов.
Пример. Предполагается, что 3 процессора используются для выполнения оператора соединения; 5 процессоров - для выполнения оператора просмотра (2 - для просмотра кортежей отношения А, 2 - для просмотра кортежей отношения В); 3 процесса выполняют вставку. Предполагается разделение данных на основе диапазона значений.

Решение на основе разделения внутри реляционных операторов.