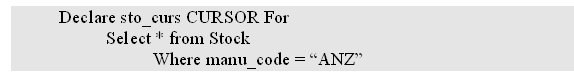
Язык программирования баз данных Informix-4GL
5. Организация параллельной работы в СУБД Informix
5. Организация параллельной работы в СУБД Informix
Необходимость организации параллельной работы с базами данных обусловлена необходимостью разделять одну базу данных несколькими пользователями одновременно. Поэтому, как в любой системе управления параллельной деятельностью, необходимы механизмы упорядочения доступа к ограниченному разделяемому ресурсу со стороны множества параллельных процессов. В процессе организации параллельной работы решаются задачи по достижению двух целей:
Рассмотрим простейшую ситуацию параллельного выполнения двух программ.
Программа I выбирает строки таблицы базы данных через курсор.
Программа II выполняет обновление тех же строк таблицы.

Возможны следующие четыре варианта последствий, известные как эффекты параллелизма.
Если первые две ситуации вполне безобидные, то две последние (особенно четвертая) не оправданы ни с позиции логики, ни с позиции здравого смысла.
Выделяют два класса параллельности. Первый класс применим в отношении доступа к базе данных на чтение (Select) и называется уровнем изоляции. Второй класс параллельности распространим на операции, модифицирующие базу данных (Inser
t, Delete, Update).Уровень изоляции представляет собой степень изолированности программы от параллельных действий со стороны других программ. Informix-Online предоставляет четыре уровня изоляции:
Уровень изоляции Dirty Read
Простейший уровень изоляции Dirty Read (грязное чтение)
Set isolation to dirty read
фактически означает отсутствие какой-либо изоляции. Когда программа выбирает строку, она не устанавливает никаких блокировок и просто копирует строки из базы данных, не обращая внимания на то, что делают другие программы.
Если программа, использующая уровень изоляции Dirty Read, считает обновленные строки до того, как обновляющая программа завершит свою транзакцию, а обновляющая программа впоследствии аннулирует ее, то это будет означать, что читающая программа обработала данные, которые никогда не существовали (четвертый эффект параллелизма).
Уровень грязного чтения может быть полезен:
Уровень изоляции Committed Read
При использовании уровня изоляции Committed Read (подтвержденное чтение)
Set isolation to committed read
Informix-Online гарантирует, что никогда не вернет строку, не зафиксированную в базе данных. Это предотвращает ситуацию, соответствующую четвертому эффекту параллелизма. Перед выборкой строки сервер проверяет, установил ли обновляющий процесс блокировку этой строки. Поскольку уровень изоляции Committed Read сам не устанавливает блокировки выбранной строки, он почти столь же эффективен, как и уровень Dirty Read. Уровень изоляции Committed Read подходит для использования в тех случаях, когда каждая строка обрабатывается как независимая единица данных без ссылок на другие строки в той же самой или других таблицах и может использоваться:
Уровень изоляции Cursor Stability
При уровне изоляции стабильное чтение (чтение по установленному курсору)
Set isolation to
сursor stabilityустанавливается разделяемый замок на каждую строку, когда она выбирается курсором для чтения. Такой замок стоит до тех пор, пока не будет обращения к следующей строке. Если данные выбираются с использованием курсора, то разделяемый курсор сохраняется до выполнения следующего оператора Fetch. На данном уровне изоляции можно не только просматривать подтвержденные строки, но также гарантируется существование строки в то время, когда она просматривается. Никакой процесс не может изменить такую строку (по Update или Delete), пока выполняется ее просмотр. Предложения Select, использующие уровень стабильного чтения, могут быть полезны:
Рассмотрим поведение двух параллельно выполняющихся программ при использовании различных уровней изоляции.
Программа А вставляет новое наименование товара (таблица Stoсk) для некоторого производителя Hero (таблица Manufact). Таблицы связаны между собой по коду производителя. Программа Б намерена удалить производителя Hero и перечень всех товаров, связанных с ним.
|
Уровень Сursor Stability |
Уровень ниже Сursor Stability |
|
1. Программа А находит по курсору из таблицы Manufact строку, соответствующую Hero, выбирая код производителя и устанавливая совместную блокировку этой строки |
1. Программа А находит по курсору из таблицы Manufact строку, соответствующую Hero, выбирая код производителя и не устанавливая никакой блокировки |
|
2. Программа Б пытается выполнить оператор Delete для удаления этой строки. Поскольку для этой строки установлена блокировка, сервер баз данных вынуждает программу Б ожидать |
2. Программа Б выполняет оператор Delete для удаления этой строки. Оператор успешно выполняется |
|
3. Программа А вставляет новую строку с товаром в таблицу Stoсk, используя код производителя, полученный из таблицы Manufact |
3. Программа Б удаляет все строки из таблицы товаров Stoсk, используя код производителя, полученный из таблицы Manufact |
|
4. Программа А закрывает свой курсор на таблице Manufact, снимая ее блокировку |
4. Программа Б завершает свое выполнение |
|
5. Программа Б, заканчивая ожидание, завершает удаление этой строки и приступает к удалению строк из таблицы с товарами Stock, которые имеют код производителя Hero, включая строку, только что вставленную программой А |
5. Программа А, которая не знает, что ее копия строки Hero теперь незаконна, вставляет новую строку в таблицу товаров Stock, используя код удаленного производителя Hero |
|
6. Программа А завершает свое выполнение |
Уровень изоляции Repeatable Read
Уровень изоляции Repeatable Read
Set isolation to repeatable read
заставляет сервер баз данных устанавливать блокировку каждой строки, которую выбирает программа в рамках транзакции. Данный уровень изоляции позволяет программам использовать скроллирующий курсор для многократного чтения выбранных строк с гарантией того, что в промежутках времени между чтениями эти строки не будут обновлены или удалены, до тех пор пока не будет сделано подтверждение об окончании транзакции.
Структурные единицы, которые можно блокировать (ставить замки), отличаются размером блокируемых объектов:
Блокировка на уровне базы данных открывает базу данных в режиме исключающего доступа, предотвращает доступ к ней других пользователей и выполняется посредством оператора Database с опцией Exclusive. Это может быть полезным:
Блокировку на уровне таблиц можно использовать с тем, чтобы предотвратить доступ пользователей для модификации таблицы. Такой уровень логично использовать:
В каждый момент времени на таблицу можно поставить только один замок, и если какой-либо пользователь блокирует таблицу, то другие пользователи не могут блокировать ту же таблицу, пока первый пользователь не разблокирут ее.
Если таблица блокирована в разделяемом режиме оператором Lock table с опцией In Share mode, то остальные пользователи будут иметь доступ на чтение в отношение таблицы (выполнять операторы Select), но не смогут выполнять операторы Delete и Update в отношении строк таблицы или Alter в отношении таблицы
.При необходимости предотвратить любую форму доступа к таблице со стороны других пользователей необходимо выполнить блокировку таблицы в режиме исключающего доступа (Lock table с опцией In Exclusive mode).
Informix-Online хранит данные в единицах памяти, называемых дисковыми страницами. Дисковая страница содержит одну или несколько строк.
При создании таблицы производится выбор уровня блокировки, который используется при доступе к любой строке данных. На уровне блокировки страниц (Create table . . . lock mode page) будет блокирована вся страница независимо от того, сколько необходимо реально блокировать строк в ее составе. На уровне блокировки строк (Create table . . . lock mode row) будет блокирована только требуемая строка.
Блокировка на уровне страниц полезна, когда в транзакции выполняется обработка строк в соответствии с индексами таблицы или в соответствии с физическим расположением строк в таблице. Блокировка на уровне строк полезна, когда порядок обработки строк непредсказуем. На уровне блокировки страниц требуется меньше ресурсов, но при этом сужается уровень параллелизма. Если замок ставится на страницу, которая содержит много строк, а другим процессам необходимы данные из той же таблицы, доступ к ним делается невозможным.