Open Database Connectivity (ODBC) - стандарт прикладного программного интерфейса API (Application Programming Interface), который позволяет программам, работающим в различных средах, взаимодействовать с произвольными СУБД, как персональными, так и многопользовательскими, функционирующими в различных операционных системах. Основная цель ODBC - сделать взаимодействие приложения и СУБД прозрачным, не зависящим от класса и особенностей используемой СУБД.
2.1. СТАНДАРТИЗАЦИЯ АРХИТЕКТУРЫ ДОСТУПА К БАЗЕ ДАННЫХ
Работа с СУБД в локальной сети требует ряда компонентов, каждый из которых независим от вышележащего слоя и поддерживает определенный интерфейс программирования [10].
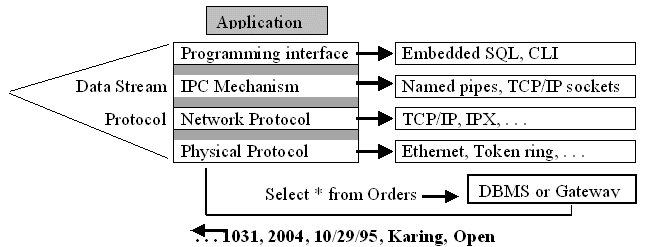
Интерфейс программирования содержит обращения, сделанные прикладной программой посредством вложенного SQL или интерфейса CLI.
Протокол передачи данных - это логический протокол, описывающий поток данных, перемещаемых между СУБД и пользователем и независящий от протоколов, используемых сетью. Например, протокол мог бы требовать, чтобы первый байт описывал то, что содержится в остальной части потока: выполняемый оператор SQL, возвращаемое значение ошибки или данные. Формат остаточной части данных в потоке зависел бы от этого флажка. Ошибка, в свою очередь, могла бы кодироваться целочисленным кодом ошибки и битами, определяющими целочисленную длину сообщения в ошибке, и т.д.
Коммуникации между процессами обеспечиваются механизмом IPC (Inter Process Communication). Например, могут использоваться именованные каналы, сокеты TCP/IP или сокеты DECnet. Выбор механизма IPC зависит от типа используемой сети и операционной системы.
Транспортный протокол используется для транспортировки данных по сети. К транспортным протоколам относятся TCP/IP, DECnet, SPX/IPX, и они являются специфическими для каждой сети.
Наконец, физический (канальный) протокол реализуется средствами аппаратного обеспечения и никак не связан с программным обеспечением.
Если внимательно посмотреть на описанные выше компоненты, то можно отметить, что два из них - программный интерфейс и потоковый протокол - являются хорошими кандидатами на стандартизацию. Три других компонента - механизм IPC, транспортный и физический протоколы - слишком зависят от сети и операционной системы и находятся на недопустимо низком уровне в 7-уровневой сетевой модели. Именно программный интерфейс был выбран в качестве основы для стандартизации.
Поскольку интерфейс CLI может быть реализован через библиотеки или драйверы базы данных, а современные операционные системы могут загружать такие библиотеки и вызывать из них необходимые функции во время выполнения, прикладная программа может не только обращаться к данным из различных СУБД без перетрансляции, но может также обращаться к данным из многих баз данных одновременно.
2.2. АРХИТЕКТУРА И УРОВНИ СООТВЕТСТВИЯ ODBC
Ниже на рисунке показана общая схема архитектуры ODBC. Приложение имеет пять логических слоев: прикладной слой, интерфейс ODBC, диспетчер драйверов, драйвер и источник данных.
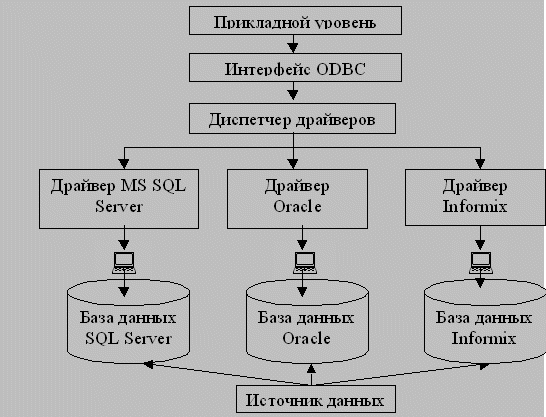
Прикладной слой реализует GUI и бизнес-логику. Он написан на языке программирования, таком как C++, Java или Visual Basic. Приложение использует функции из интерфейса ODBC для взаимодействия с базами данных.
Диспетчер драйверов является частью ODBC Microsoft. Как следует из названия, он управляет различными драйверами, имеющимися в системе, выполняя загрузку, направление вызовов на нужный драйвер и предоставление прикладной программе информации о драйвере, когда это необходимо. Поскольку одна прикладная программа может быть связана с несколькими базами данных, диспетчер драйверов гарантирует, что соответствующая система управления базой данных получит все запросы, направляемые к ней, и что все данные из источника данных будут переданы прикладной программе.
Драйвер - это та часть архитектуры, которая все знает о какой-либо базе данных. Обычно драйвер связан с конкретной базой данных, например, драйверы Access, Oracle, SQL Server, Informix, DB2, Sybase, PostgreSQL. Интерфейс ODBC имеет набор функций, таких как операторы SQL, управление соединением, информация о базе данных и т.д. В обязанности драйвера входит их реализация. Это означает, что в некоторых базах данных драйвер должен эмулировать функции интерфейса ODBC, не поддерживаемые системой управления базой данных. Он выполняет работу по посылке запросов в базу данных, получению ответов и направлению их прикладной программе. Для баз данных, действующих в локальных сетях или в Internet, драйвер поддерживает сетевую связь.
Источник данных в контексте ODBC может быть системой управления базой данных или просто набором файлов на жестком диске.
Драйвер является основной частью системы ODBC, располагающий информацией о системе управления базой данных и связанный с этой системой. ODBC не требует, чтобы драйверы поддерживали все функции этого интерфейса. Вместо этого для драйверов определяются уровни соответствия API и грамматики SQL. Единственное требование: если драйвер удовлетворяет неко-торому уровню, то он должен поддерживать все функции ODBC, определенные на этом уровне, независимо от того, поддерживает ли их база данных. Как уже отмечалось, в обязанности драйвера входит эмуляция функций ODBC, не под-держиваемых системой управления базой данных, что обеспечивает независимость интерфейса ODBC от реализации базы данных.
| Тип | Уровень соответствия | Описание |
| Уровни соответствия API | Ядро | Включает функции
|
| . | Уровень 1 | Включает возможности уровня ядра, дополненные функциями
|
| . | Уровень 2 | Включает возможности уровня 1, дополненные функциями
|
| Уровни соответствия грамматики SQL | Минимальная грамматика | Включает функции
|
| . | Грамматика ядра | Включает возможности минимальной грамматики, дополненные
|
| . | Расширенная грамматика | Включает возможности грамматики ядра, дополненные
|
2.3. ФУНКЦИИ ODBC И СТРУКТУРА КОМАНД
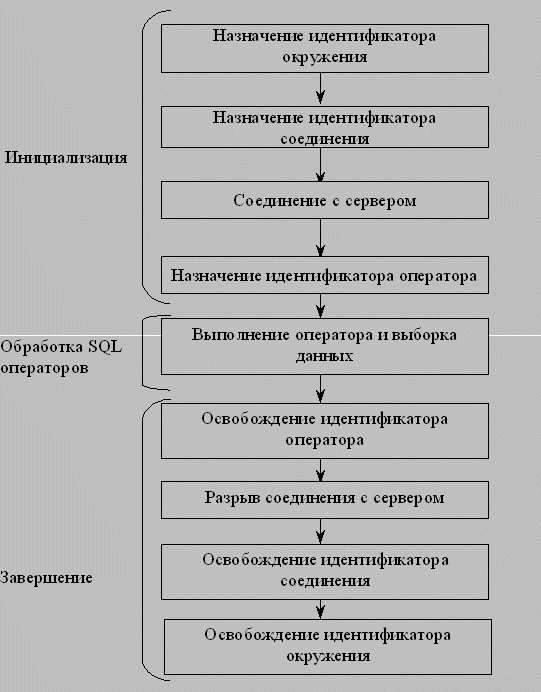
Основной алгоритм создания ODBC-программ для наглядности можно представить в виде следующей блок-схемы:
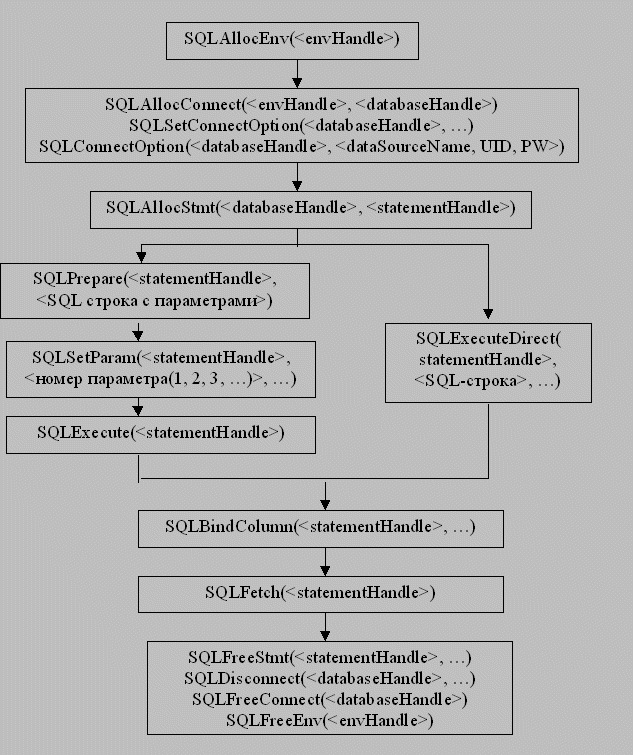
ODBC имеет богатый выбор функций: от простых операторов соединения до процедур, выдающих целый набор результатов. Все функции ODBC имеют префикс SQL и один или несколько параметров, которые могут быть входными (информация для драйвера) или выходными (информация от драйвера). Ниже приведена последовательность команд ODBC для связи с базой данных, выполнения оператора SQL, обработки данных, полученных в результате, и закрытия связи.
2.4. ПОДГОТОВИТЕЛЬНЫЕ ОПЕРАЦИИ В ODBC-ПРОГРАММЕ
Назначение идентификатора окружения
Прежде чем прикладная программа сможет вызвать какую-либо функцию ODBC, необходимо выполнить инициализацию ODBC и установить окружение. Поскольку в рамках одного окружения можно установить произвольное число соединений, для каждой прикладной программы достаточно установить только одно окружение. Функция ODBC SQLAllocEnv(), выполняющая такое назначение окружения, распределяет память для идентификатора окружения и инициализирует интерфейс ODBC на уровне вызовов для использования прикладной программой. Эту функцию необходимо вызывать прежде, чем любую другую из функций ODBC.

Освобождение идентификатора окружения
Когда прикладная программа заканчивает использование ODBC, необходимо, чтобы было освобождено связанное с ней окружение. Функция SQLFreeEnv(), параметром которой является идентификатор окружения, освобождает ресурсы, зарезервированные для данной прикладной программы:

Назначение идентификатора соединения
Идентификатор соединения представляет собой соединение между прикладной программой и источником данных, с которым прикладная программа предполагает соединиться. При этом, если необходимо соединение с двумя источниками данных, то необходимо назначить два идентификатора соединения. Функция, распределяющая память для заданного идентификатора окружения, носит имя SQLAllocConnect():

Соединение с источником данных
Несмотря на то, что существует много функций ODBC для установки соединения, на базовом уровне API такая функция одна - это SQLConnect(), которая обеспечивает простой и эффективный способ соединения с источником данных. Поскольку все драйверы поддерживают SQLConnect(), то доступ с помощью этой функции осуществляется наилучшим образом. SQLConnect() загружает драйвер базы данных и устанавливает соединение с источником данных. Идентификатор соединения ссылается на местоположение области хранения всей информации о соединении, включая ее статус, состояние транзакции и информацию об ошибке.

Замечание: значение SQL_NTS является константой ODBC, которая используется вместо длины параметра в случае, если параметр содержит строку с нулевым окончанием.
Разъединение с источником данных
Как только прикладная программа заканчивает использование доступа к источнику данных, она должна отсоединиться от него, чтобы дать другим пользователям войти в систему. Этой операцией управляет функция SQLDisconnect(), которая закрывает соединение с источником данных с помощью специального идентификатора соединения:

Освобождение идентификатора соединения
Если прикладная программа не планирует относительно долгое время использовать идентификатор соединения, она должна освободить этот идентификатор, чтобы возвратить любые назначенные с ним ресурсы. Данную операцию выполняет функцию SQLFreeConnect():

Назначение идентификатора оператора
Любая функция SQL, которая имеет отношение к обработке или передаче SQL-операторов, требует в качестве параметра идентификатор оператора. Идентификатор оператора аналогичен идентификатору окружения или соединения за исключением того, что он ссылается на SQL-оператор или на другие функции ODBC, которые возвращают результаты. Следует заметить, что идентификатор соединения может быть связан с несколькими идентификаторами операторов, но каждый идентификатор оператора связан только со своим идентификатором соединения. Для того, чтобы назначить идентификатор оператора, прикладной программе нужно вызвать функцию SQLAllocStmt(), которая выделит память для SQL-операторов, это необходимо сделать до использования операторов:

Освобождение идентификатора оператора
Для освобождения идентификатора оператора используется функция SQLFreeStmt(), которая выполняет следующие действия:
- останавливает любые SQL-операторы, которые в данный момент обрабатываются и связаны с заданным идентификатором оператора;
- закрывает любые открытые курсоры, которые имеют отношение к определенному идентификатору оператора;
- отбрасывает ожидаемые результаты;
- освобождает все ресурсы, связанные с определенным идентификатором оператора

Опции функции SQLFreeStmt() имеют следующие значения:
- SQL_CLOSE - закрывает курсор, связанный с hstmt, (если он был определен) и отбрасывает все ожидаемые результаты. Прикладная программа может вновь открыть этот курсор позднее, вновь выполнить оператор SELECT с теми же самыми или другими значениями параметров. Если курсор не открыт, то эта опция не повлияет на программу.
- SQL_DROP - освобождает hstmt, освобождает все ресурсы, связанные с ним, закрывает курсор, если он открыт и отбрасывает все ожидаемые строки. Эта опция завершает все обращения к hstmt. Hstmt обязательно должен быть переназначен для повторного использования. Эта опция освобождает все ресурсы, которые были определены с помощью функции SQLFreeStmt().
- SQL_UNBIND - освобождает все буферы столбцов, которые повторно используются функцией SQLBindCol() для данного идентификатора оператора.
- SQL_RESET_PARAMS - освобождает все буферы параметров, которые были установлены функцией SQLBindCol() для данного идентификатора оператора.
Пример простой ODBC программы:

Сделаем некоторые промежуточные выводы: в каждой ODBC-программе необходимо строго придерживаться определенной последовательности описания функций, отвечающих за окружение, соединение и назначения операторов. Эта последовательность имеет вид:
- назначение идентификатора окружения;
- назначение идентификатора соединения;
- осуществление соединения с сервером;
- назначение идентификатора оператора;
- выполнение оператора и выборка данных;
- освобождение идентификатора оператора;
- разрыв соединение с сервером;
- освобождение идентификатора соединения;
- освобождение идентификатора окружения.
2.5. ОБРАБОТКА ОШИБОК В ODBC-ПРОГРАММЕ
Важной частью любого API, является его способность возвращать коды и состояния ошибок. Отлаженная система сообщений об ошибках позволяет прикладному программному обеспечению определить ее причину при выполнении какой-либо функции, а затем эту ошибку скорректировать.
Коды возврата
Все функции ODBC возвращают коды, чтобы показать в каком состоянии выполнения находится интересующая функция. В случае ошибки код возврата не указывает точной причины ее возникновения, а указывает лишь на то, что ошибка имела место вообще.
Ниже приведены основные значения кодов возврата RETCODE, которые могут возвращаться ODBC-функциями:
- SQL_SUCCESS - ошибка отсутствует.
- SQL_SUCCESS_WITH_INFO - функция обработки завершена, но при вызове вспомогательной функции SQLError() идентифицируется ошибка. В большинстве случаев это возникает, когда значение, которое должно быть возвращено, большего размера, чем это предусмотрено буфером прикладной программы.
- SQL_ERROR - функция не была завершена из-за возникшей ошибки. При вызове функции SQLError() можно будет получить больше информации о сложившейся ситуации.
- SQL_INVALID_HANDLE - неправильно определен идентификатор окружения, соединения или оператора. Ситуация часто имеет место, когда идентификатор используется после того, как он был освобожден или если был определен нулевой указатель.
- SQL_NO_DATA_FOUND - невозможно выбрать данные. Ситуация фактически не является ошибочной и чаще всего возникает при использовании курсора, когда больше нет строк для его продвижения.
- SQL_NEED_DATA - необходимы данные для параметра.
Обработка ошибок
В случае, если прикладная программа передает неверные значения в драйвер ODBC, в СУБД возникают проблемы. Хорошо написанная программа может восстанавливаться из ошибочного состояния, если она знает место возникновения ошибки. В ODBC имеются расширенные средства для исправления ошибки с использованием функции SQLError(). Следует отметить, что SQLError() возвращает дополнительную информацию лишь в том случае, если кодом возврата функции обработки является SQL_ERROR или SQL_SUCCESS_WITH_INFO.

Фрагмент программы обработки ошибок с использованием функции SQLError() приведен ниже:

Таким образом, чтобы прикладная программа могла восстановиться из любого ошибочного состояния, важно знать место возникновения ошибки. Для этого используют коды возврата RETCODE и одна из базовых функций API - SQLError(), с помощью которой можно получить подробное описание произошедшей ошибки.
2.6. ВЫПОЛНЕНИЕ SQL-ОПЕРАТОРОВ
Существуют два метода, которые может использовать прикладная программа для выполнения SQL-операторов: непосредственное выполнение и подготавливаемое.
Непосредственное выполнение является самым быстрым и простым способом использования SQL-операторов, однако подготавливаемое выполнение обеспечивает большую гибкость, особенно при использовании SQL-операторов с параметрами.
Непосредственное выполнение
Непосредственное выполнение эффективнее использовать, если выполняются следующие два условия:
- SQL-операторы, которые должны быть выполнены, будут выполняться только один раз.
- Не требуется информации о результирующем множестве до выполнения оператора.
Если хотя бы одно из условий не соблюдается, подготавливаемое выполнение с помощью функций SQLPrepare() и SQLExecute() является более предпочтительным.
Непосредственное выполнение осуществляется с помощью функции SQLExecDirect(), которая выполняет SQL-оператор, подготовленный для использования драйвером.

В следующем примере демонстрируются различные способы использования функции SQLExecDirect().

Подготавливаемое выполнение
Подготавливаемое выполнение является более предпочтительным по сравнению с непосредственным, если требуется выполнить SQL-оператор более одного раза, или, если необходима информация о результирующем множестве до выполнения оператора.
Для подготавливаемого выполнения SQL-оператора необходимы две функции: SQLPrepare() и SQLExecute(). Прикладная программа сначала вызывает SQLPrepare() с параметром, являющимся SQL-оператором, для подготовки выполнения оператора:

а затем SQLExecute, чтобы этот оператор выполнить:

Использование параметров
Параметры могут использоваться как при непосредственном выполнении (SQLExecDirect()), так и при подготавливаемом (SQLPrepare(), SQLExecute()). Использование параметров в обоих случаях дает дополнительное преимущество, позволяя писать более гибкие прикладные программы. Маркеры параметров определяются в SQL-операторах с помощью знаков "?". Например,

Для того, чтобы связать буфер с маркерами параметров, прикладная программа должна вызвать функцию SQLBindParameter():

Ниже перечислены параметры функции SQLBindParameter():
| HSTMT hsmt; | - идентификатор оператора, совпадающий со значением идентификатора, с которым этот оператор подготавливается и выполняется. |
| UWORD ipar; | - номер параметра для связи. В операторе SQL операторы нумеруются слева направо, начиная с единицы. Например, если для SQL-оператора используется три параметрических маркера:
insert into j (n_izd, name, town) values (?, ?, ?) то для связи этих параметров функция SQLBindParameter() вызывается три раза с параметром ipar, установленным в 1, 2 и 3 соответственно. |
| SWORD fParamType; |
SQL_PARAM_INPUT используется для процедур, использующих параметры ввода. QL_PARAM_INPUT_OUTPUT маркирует параметр ввода/вывода в процедуре. SQL_PARAM_OUTPUT маркирует значение возврата или параметр вывода в процедуре. |
| SWORD fCType; | - С-тип данных параметра, из которого необходимо конвертировать данные. |
| RD fSqlType; | - ODBC-тип данных параметра, в который конвертируются данные, и который должен совпадать с SQL-типом столбца, соответствующего этому параметрическому маркеру. |
| UDWORD сbColDef; | - точность столбца или выражения соответствующего маркера параметра. |
| SWORD ibScale; | - размер столбца или выражения соответствующего маркера параметра. |
| PTR rgbValue; | - указатель буфера для данных параметра, который при вызове SQLExecute() или SQLExecuteDirect() содержит действительные значения параметра. |
| SDWORD сbValueMax | - максимальная длина буфера rgbValue. |
| SDWORD pcbValue; | - указатель буфера для длины параметра. |
Ниже приведены основные значения С- и SQL-типов параметров.
| C-Тип | SQL-Тип |
| SQL_C_BINARY | SQL_BINARY |
| SQL_C_BIT | SQL_BIT |
| SQL_C_CHAR | SQL_CHAR |
| SQL_C_DATE | SQL_DATE |
| SQL_C_DOUBLE | SQL_DOUBLE |
| SQL_C_FLOAT | SQL_FLOAT |
| SQL_C_TIME | SQL_TIME |
| SQL_C_DEFAULT | SQL_DECIMAL |
| SQL_C_SLONG | SQL_INTEGER |
| SQL_C_SSHORT | SQL_REAL |
| . | SQL_SMALLINT |
| . | SQL_VARCHAR |
Использование метода подготавливаемого выполнения и использования параметров иллюстрируется ниже.

2.7. ВЫБОРКА РЕЗУЛЬТИРУЮЩИХ ДАННЫХ
cРезультатом выполнения SQL-оператора может быть результирующее множество (для оператора Select) или число строк, на которые воздействовал оператор (для операторов Update, Insert, Delete). Исходя из этого, рассмат-риваемые в данном разделе ODBC-функций можно разбить на три группы:
- информационные функции результирующих множеств;
- базовые функции выборки данных;
- расширенные функции выборки данных.
Под результирующим множеством понимается набор строк и столбцов, которые были определены SQL-оператором.
После того как был выполнен SQL-оператор и было создано результирующее множество, оно тем не менее располагается на сервере и должно быть извлечено и сохранено с помощью средств прикладной программы клиента.
Информационные функции результирующих множеств
Среди ODBC-функций данной группы отметим две: SQLRowCount() и SQLNumResultCol(). Первая из них возвращает число строк, на которые воздействовал SQL-оператор (-1 в случае, если число таких строк не определяется), вторая - возвращает число столбцов в результирующем множестве.

Замечание: хотя при использовании функции SQLRowCount() некоторые драйверы способны возвращать число строк, которые были возвращены оператором Select, этот способ в общем случае не является корректным, поскольку достаточно много источников данных не могут возвращать число строк до их извлечения.
Ниже демонстрируется использование функции SQLRowCount() после удаления строк из таблицы для выяснения того, на сколько строк воздействовал оператор удаления.

Базовые функции выборки данных
После генерации результирующие множества строки в нем имеют определенный порядок, этот порядок используется для продвижения по результирующему множеству. Например, конкретная строка должна быть первой, третьей, четвертой, седьмой и т.д. Чтобы выполнить такое продвижение в пределах результирующего множества программа должна использовать курсор.
Курсор автоматически генерируется для каждого результирующего множества. Непосредственно после создания результирующего множества курсор устанавливается перед первой строкой данных. Для продвижения курсора используются функции ODBC SQLFetch() или SQLExtendedFetch(). SQLFetch() продвигает курсор вперед на каждую строку до тех пор, пока не будет установлен за последней строкой результирующего множества. SQLExtendedFetch() по умолчанию делает то же самое, однако имеет опцию, которая позволяет продвинуть курсор в произвольном направлении.
В ODBC существуют две функции базового уровня для выборки результатов: SQLBindCol() и SQLFetch(). Функция SQLBindCol() определяет область хранения данных результирующего множества, а функция SQLFetch() осуществляет выборку в область хранения, при этом SQLBindCol() может быть вызвана в любой момент времени, даже до того, как оператор ожидает результирующее множество.
Каждый столбец, который требуется выбрать, связывается с помощью отдельного вызова функции SQLBindCol(). Функция SQLBindCol() назначает область хранения в памяти и тип данных для столбца результирующего множества. Она определяет:
- буфер хранения для получения содержимого столбца данных в результирующем множестве.
- длину указанного буфера хранения.
- область памяти для хранения длины столбца выборки.
- преобразование типа данных.
Алгоритм программы, использующей SQLFetch() и SQLBindCol() для возвращения данных из результирующего множества предполагает выполнения следующих шагов.
- Вызывается функция SQLBindCol() один раз для каждого столбца, который должен быть возвращен из результирующего множества.
- Вызывается функция SQLFetch() для перемещения курсора на следующую строку и возврата данных из связанных столбцов.
- Повторяется шаг 2 до тех пор, пока функция SQLFetch() не возвратит SQL_NO_DATA_FOUND. Это указывает на то, что был достигнут конец результирующего множества. Если результирующее множество является пустым, то SQL_NO_DATA_FOUND будет возвращен при первом вызове SQLFetch().

После того, как все требуемые столбцы связаны, посредством функции SQLFetch() выполняется выборка данных в определенную область хранения.

Использование функций SQLBindCol() и SQLFetch() иллюстрируется следующим примером:

Дополнительно к функциям SQLBindCol() и SQLFetch() для выборки данных из несвязанных столбцов прикладная программа может использовать функцию SQLGetData(). Эта функция позволяет выполнить выборку данных из столбцов, для которых область хранения не была заранее подготовлена с помощью функции SQLBindCol(). Функция SQLGetData() вызывается после SQLFetch() для выборки данных из текущей строки.
Алгоритм программы, использующей SQLFetch() и SQLGetData() для извлечения данных из каждой строки результирующего множества предполагает выполнения следующих шагов.
- Вызывается функция SQLFetch() для продвижения на следующую строку.
- Вызывается функция SQLGetData() для каждого столбца, который должен быть возвращен из результирующего множества.
- Повторяется шаги 1 и 2 до тех пор, пока функция SQLFetch() не возвратит SQL_NO_DATA_FOUND. Это указывает на то, что был достигнут конец результирующего множества. Если результирующее множество является пустым, то SQL_NO_DATA_FOUND будет возвращен при первом вызове SQLFetch().

Прикладная программа может использовать SQLBindCol() для некоторых столбцов, а SQLGetData() - для других столбцов в пределах той же самой строки.
С использованием функции записанный выше фрагмент доступа к данным будет выглядеть следующим образом:

ODBC обеспечивает богатый набор функций расширенной выборки данных, которые позволяют выполнить дополнительные операции над результирующим множеством. Эти функции предусматривают использование блочных и перемещаемых курсоров. Блочные курсоры позволяют выбирать множество строк за один раз, перемещаемые курсоры предназначены для продвижения вперед и назад в пределах результирующего множества. Одна из таких функций - SQLExtendedFetch() предусматривает использование блочных, перемещаемых и блочных и перемещаемых курсоров одновременно. Эта функция расширяет функциональные возможности SQLFetch() по следующим направлениям:
- для каждого связанного столбца данная функция возвращает данные множества строк (одна или более) в виде массива;
- при установке типа перемещения, она позволяет перемещаться по результирующему множеству в произвольном направлении;
- функция SQLExtendedFetch() работает совместно с функцией SQLSetStmtOption().
При выборке одной строки данных за один раз в прямом направлении, достаточно воспользоваться функцией SQLFetch().

Функция SQLSetStmtOption() носит вспомогательный характер и имеет широкий спектр действий. Она служит, в частности, для
- установление размера строкового множества при использовании блочных курсоров;
- определения типа курсора при использовании перемещаемых курсоров;
- установления типа согласования;
- включения идентификатора записи и т.д.
Полное ее рассмотрение выходит за пределы пособия, и в дальнейшем мы ограничимся лишь примерами ее использования.
Строковые множества из более чем одной строки могут быть получены функцией SQLExtendedFetch(). Размер строкового множества устанавливается функцией SQLSetStmtOption() со значением fOption SQL_ROWSET_SIZE и опцией vParam.
Перемещаемые курсоры, создаваемые функцией SQLExtendedFetch(), являются более гибкими, чем курсоры, обеспечиваемые функцией SQLFetch(). Прежде чем использовать перемещаемые курсоры, необходимо выбрать тип курсора с помощью функции SQLSetStmtOption() со значением fOption SQL_CURSOR_TYPE. Тип курсора, предполагаемый по умолчанию, (SQL_CURSOR_FORWARD_ONLY), не позволит использовать никакие типы перемещения в функции SQLExtendedFetch(), кроме как SQL_FETCH_NEXT.
Типы курсоров, которые могут быть определены функцией SQLSetStmtOption(), следующие:
SQL_CURSOR_STATIC - статические курсоры, являются абсолютно нечувствительными к изменениям в таблицах, на основе которых было выбрано результирующее множество. Это означает, что как только создано результирующее множество, оно будет оставаться одним и тем же до тех пор, пока не будет закрыто.
SQL_CURSOR_DYNAMIC - динамические курсоры, являются полностью чувствительными к основным изменениям. Это означает, что данные результирующего множества будут постоянно изменяться, отражая вставки, обновления и удаления после того, как множество было создано.
SQL_CURSOR_KEYSET_DRIVEN - курсоры, управляемые ключами, занимают некоторое среднее положение между динамическими и статическими курсорами с точки зрения того, как они отражают основные изменения. Такое результирующее множество отражает обновленные и удаленные строки, за исключением новых строк. Курсоры данного типа являются наилучшим средством в тех случаях, когда необходимо использовать динамическое результирующее множество, но нет возможности использовать динамические курсоры.
Формат функции SQLSetStmtOption(), используемой для задания типа курсора, следующий:

Способность продвигать курсор на любое число строк является реальным преимуществом. Например, если курсор был установлен на первую строку результирующего множества и необходимо переместить его на последнюю строку, функция SQLExtendedFetch() позволит сделать это за одно обращение, в то время, как с использованием функции SQLFetch() могут потребоваться тысячи вызовов ее вызовов.
Замечание.
Так как функция SQLExtendedFetch() является функцией второго уровня, то ее поддерживают не все драйверы. Для того, чтобы это выяснить, необходимо вызвать функцию SQLGetFunctions() с параметром fFunction SQL_API_SQLEXTENDEDFETCH. Функция возвратит значения TRUE, либо FALSE, что даст ответ на вопрос о поддержании драйвером этой функции.
Движение курсора устанавливается с помощью параметров fFetchType и irow в функции SQLExtendedFetch(). fFetchType определяет тип выполняемой выборки, а irow (при его использовании) определяет число строк выборки.
| fFetchType | действие SQLExtendedFetch() |
| SQL_FETCH_NEXT | Извлекает следующее строковое множество. |
| SQL_FETCH_PRIOR | Извлекает предыдущее строковое множество. |
| SQL_FETCH_RELATIVE | Извлекает строковое множество, начиная с N-ой строки по отношению к текущей позиции курсора, где N определяется параметром irow. |
| SQL_FETCH_FIRST | Извлекает первое строковое множество результирующего множества. |
| SQL_FETCH_LAST | Извлекает последнее строковое множество результирующего множества. |
| SQL_FETCH_ABSOLUTE | Извлекает строковое множество, начиная с N-ой строки в результирующем множестве, где N определяется параметром irow. |
Подводя итог, сделаем следующие выводы относительно средств выборки данных ODBC.
Для выборки результирующих данных используется функция SQLFetch(), которая за один раз продвигает курсор только вперед и только на одну строку и действует до тех пор, пока не будет возвращено SQL_NO_DATA_FOUND. Недостатком такой выборки является то, что, например, при необходимости переместиться с первой строки результирующего множества на последнюю, функция SQLFetch() будет последовательно проходить по всем строкам выборки. Более эффективным в этом случае является использование функцией SQLExtendedFetch() перемещаемых курсоров, которые способны перемещаться в любом направлении и на любое количество строк. Однако эта функция является функцией второго уровня, и ее поддерживают не все драйверы.
Для использования средств ODBC на платформе Unix необходимо:
- отредактировать в домашней директории системный файл .odbc.ini, определив в нем источники данных пользователя;
- определить переменную окружения ODBCINI;
- обеспечить выполнение системных требований для работы с соответствующим сервером баз данных;
- подключить к программе необходимые заголовочные файлы;
- при компиляции исходной программы подключить необходимые библиотеки.
Системный файл .odbc.ini
Для настройки источника данных, необходимо проверить находится ли системный текстовый файл .odbc.ini в домашней директории пользователя и отредактировать его, настроив на требуемые источники данных.
В файле .odbc.ini должен быть под некоторым идентификатором описан требуемый источник данных, имя которого используется функцией SQLConnect(), и далее должен присутствовать раздел с данным именем, в котором содержатся атрибуты, описывающие источник данных. Например, если в качестве источника данных выступает база данных PostgreSQL, описание может быть следующим:
[MYDB]
Driver = PostgreSQL Trace = Yes TraceFile = sql.log Database = students Servername = localhost Password = Port = 5432 Protocol = 8.0 ReadOnly = No RowVersioning = No ShowSystemTables = No ShowOidColumn = No FakeOidIndex = No ConnSettings =
В приведенном фрагменте MYDB - имя источника данных, а параметр Driver содержит имя файла драйвера, обслуживающего источник данных PostgreSQL.
Полный список параметров описания источника данных в файле .odbc.ini приведен ниже.
В таблице даются полные и сокращенные названия каждого атрибута, а также их описание. В системном файле используются только полные названия атрибутов. Значения, перечисленные в таблице, заданы по умолчанию и используются в таком виде, если нет других значений заданных в строке соединения или в системном файле. Если изменить значение атрибута при настройке источника данных, то это значение будет использоваться по умолчанию.
Атрибуты строки соединения
| Атрибут | Описание |
| ApplicationUsing Threads (AUT) | ApplicationUsingThreads={0 | 1}. Обеспечивает работу драйверов с много потоковыми приложениями. |
| CancelDetectInterval (CDI) | Позволяет прерывать долго выполняющиеся запросы в потоковых приложениях. Выбирается значение, определяющее, как часто драйвер будет проверять, был ли запрос закрыт функцией SQLCancel(). Например, если CDI=5, тогда для каждого затянувшегося запроса, драйвер каждые 5с будет проверять: прервал ли пользователь выполнение запроса, используя SQLCancel(). Значение по умолчанию равное 0, означает, что запросы не будут прекращены до тех пор, пока не завершат свое выполнение. |
| CursorBehavior (CB) | CursorBehavior={0 | 1}. Этот атрибут определяет, будет ли курсор сохранен или закрыт по завершению каждой транзакции. Значение по умолчанию равно 0 (курсор закрывается). Значение атрибута равного 1 означает, что курсор будет сохранен на текущей позиции по завершению транзакции. Значение CursorBehavior=1 может влиять на выполнение операций вашей базы данных. |
| Database (DB) | Имя базы данных, к которой необходимо получить доступ. |
| DataSourceName (DSN) | Строка, которая определяет источник данных в системной информации. |
| EnableInsertCursors (EIC) | EnableInsertCursors={0 | 1}. Определяет, будет ли драйвер использовать вставку курсоров. Использование этой операции увеличивает быстродействие в течение многократных вставок, использующих аналогичные выражения. Эта опция позволяет буферизовать вставляемый данные в памяти прежде чем записать на диск. Когда установлено, что EnableInsertCursors=0, то драйвер не использует вставку курсоров. |
| EnableScrollable Cursors (ESC) | EnableScrollableCursors={0 | 1}. Этот атрибут определяет, обеспечивает ли драйвер вставку скроллирующих курсоров. Значение по умолчанию равно 0 (без использования скроллирующих курсоров). Драйвер в PostgreSQL может использовать скроллирующий курсор, только в случаях, когда не используются слишком длинные столбцы (SQL_LONGVARCHAR или SQLVARBINARY) в результирующем множестве. Если же все-таки установлена поддержка скроллирующих курсоров (EnableScrollableCursors=1), то в результирующем множестве не должны быть слишком длинные столбцы. |
| GetDBListFrom PostgreSQL (GDBLFI) | GetDBListFromPostgreSQL={0 | 1}. Этот атрибут определяет, будет ли драйвер запрашивать список базы данных от сервера PostgreSQL или от пользователя, который определил его при установке драйвера. Значение по умолчанию равно 1, т.е. драйвер запрашивает список от сервера. |
| HostName (HOST) | Имя машины, на которой установлен сервер PostgreSQL. |
| LogonID (UID) | Ваше имя, указанное на PostgreSQL сервере. |
| Password (PWD) | Пароль. |
| ServerName (SRVR) | Имя сервера, который обрабатывает базу данных. |
| Service (SERV) | Имя службы, которое установлено на главном компьютере. Такая служба устанавливается системным администратором. |
| UseDefaultLogin (UDL) | UseDefaultLogin={0 | 1}. Значение 1 позволяет считывать имя и пароль непосредственно из системного реестра PostgreSQL. Значение по умолчанию равно 0. |
Отметим, что в файле .odbc.ini может быть описано несколько источников данных (разные базы данных, разные СУБД) и пользовательская программа может одновременно работать с разными источниками данных.
Переменная окружения ODBCINI
При входе пользователя в систему необходимо сообщить операционной системе UNIX переменную окружения ODBCINI. В переменной окружения ODBCINI необходимо указать полное имя системного файла .odbc.ini из домашней директории. Сделать это можно, либо введя с консоли соответствующую команду, либо поместив эту команду в файл загрузки .login. Форма записи команды зависит от используемой программы Shell-интерпретатора. Например, при условии, что файл .odbc.ini находится в некоторой директории /home/students/pmxxyy в C-shell эту переменную можно установить следующим образом:

В Bourne или Korn-shell, установка переменной окружения ODBCINI будет выглядеть иначе:

Если файл .odbc.ini находится в домашней директории, переменную ODBCINI устанавливать не требуется.
Системные требования
Системные требования зависят от той СУБД, с которой работает пользователь. Например, при работе с СУБД Informix это обеспечивается переменными окружения, выставленными в файле .cshrc в домашней директории пользователя. В случае использования C-shell эти переменные могут иметь вид:

В приведенной записи onfpm - имя конкретного сервера баз данных, onconfig - имя сервиса.
При работе с PostgreSQL каких-либо установок на уровне системы делать не требуется.
За другими деталями работы с ODBC можно обратиться к руководству "http://fpm2.ami.nstu.ru/odbc/ProgrammerManual/Tutorial/".
Заголовочные файлы
Для получения доступа к ODBC-функциям в программе должен быть описан заголовочный файл sqlext.h и файл sqltypes.h, где находятся описание типов данных используемых в ODBC.
Компиляция исходной программы
Как и любой исходный файл, написанный на языке Си, файл с программой, вызывающей ODBC-функции, должен иметь расширение .с. При компиляции необходимо подключить необходимые библиотеки, используемые в вызываемых функциях. Поскольку в этом случае командная строка принимает достаточно сложный вид, целесообразно на уровне системного администратора оформить командный файл, в котором подключаются необходимые библиотеки.
Общий вид команды на трансляцию и подготовку исполняемого файла с программой, использующей средства ODBC, приведен ниже:
gcc -lodbc demoodbc.c -o demoodbc.exe