Автометрия. 2001. - № 2. - С. 88-102.
УДК 519.2
ПРИМЕНЕНИЕ НЕПАРАМЕТРИЧЕСКИХ КРИТЕРИЕВ СОГЛАСИЯ ПРИ ПРОВЕРКЕ СЛОЖНЫХ ГИПОТЕЗ
Лемешко Б.Ю., Постовалов С.Н.
1. Введение
Одной из наиболее распространенных задач статистического
анализа при обработке результатов экспериментальных наблюдений является
проверка согласия полученного опытного распределения с теоретическим. Применяя
критерии согласия, различают проверку простых и сложных гипотез. Простая проверяемая
гипотеза имеет вид ![]() :
: ![]() , где
, где ![]() –
функция распределения вероятностей, с которой проверяется согласие
наблюдаемой выборки, а
–
функция распределения вероятностей, с которой проверяется согласие
наблюдаемой выборки, а ![]() – известное значение параметра
(скалярного или векторного). При проверке сложной гипотезы проверяемая гипотеза
имеет вид
– известное значение параметра
(скалярного или векторного). При проверке сложной гипотезы проверяемая гипотеза
имеет вид ![]() :
: ![]() . В этом случае оценка
параметра распределения
. В этом случае оценка
параметра распределения ![]() вычисляется по той же самой выборке,
по которой проверяется согласие.
вычисляется по той же самой выборке,
по которой проверяется согласие.
В процессе проверки согласия по выборке вычисляется
значение ![]() статистики используемого критерия.
Затем для того, чтобы сделать вывод о том, принять или отклонить гипотезу
статистики используемого критерия.
Затем для того, чтобы сделать вывод о том, принять или отклонить гипотезу ![]() ,
необходимо знать условное распределение
,
необходимо знать условное распределение ![]() статистики
статистики ![]() при
справедливости
при
справедливости ![]() . И если вероятность
. И если вероятность
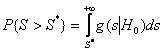
достаточно большая, по крайней мере ![]() , где
, где
![]() –
условная плотность, а
–
условная плотность, а ![]() – задаваемый уровень значимости
(вероятность ошибки первого рода – отклонить справедливую гипотезу
– задаваемый уровень значимости
(вероятность ошибки первого рода – отклонить справедливую гипотезу ![]() ), то
принято считать, что нет оснований для отклонения гипотезы
), то
принято считать, что нет оснований для отклонения гипотезы ![]() .
.
К наиболее используемым
критериям согласия относятся непараметрические критерии типа Колмогорова,
типа ![]() и
и ![]() Мизеса. В критерии
Колмогорова в качестве расстояния между эмпирическим и теоретическим законом
используется величина
Мизеса. В критерии
Колмогорова в качестве расстояния между эмпирическим и теоретическим законом
используется величина
![]() ,
,
где
![]() –
эмпирическая функция распределения,
–
эмпирическая функция распределения, ![]() – теоретическая
функция распределения,
– теоретическая
функция распределения, ![]() – объём выборки. При проверке
гипотез обычно используется статистика вида [1]
– объём выборки. При проверке
гипотез обычно используется статистика вида [1]
![]() ,
,
где
![]() ,
, ![]() ,
, ![]() ,
,
![]() - объем выборки,
- объем выборки, ![]() - упорядоченные по
возрастанию выборочные значения,
- упорядоченные по
возрастанию выборочные значения, ![]() - функция закона
распределения, согласие с которым проверяется. Распределение величины
- функция закона
распределения, согласие с которым проверяется. Распределение величины ![]() при
простой гипотезе в пределе подчиняется закону Колмогорова
при
простой гипотезе в пределе подчиняется закону Колмогорова ![]() [1].
[1].
В критериях типа ![]() расстояние между гипотетическим и
истинным распределениями рассматривается в квадратичной метрике
расстояние между гипотетическим и
истинным распределениями рассматривается в квадратичной метрике
![]() ,
,
где
![]() -
оператор математического ожидания.
-
оператор математического ожидания.
При выборе ![]() в критериях типа
в критериях типа ![]() Мизеса
пользуются статистикой (статистика Крамера-Мизеса-Смирнова) вида
Мизеса
пользуются статистикой (статистика Крамера-Мизеса-Смирнова) вида
![]() ,
,
которая
при простой гипотезе подчиняется распределению ![]() [1].
[1].
При выборе ![]() в критериях типа
в критериях типа ![]() Мизеса
статистика (статистика Андерсона-Дарлинга) имеет вид
Мизеса
статистика (статистика Андерсона-Дарлинга) имеет вид
![]() .
.
В пределе
эта статистика подчиняется распределению ![]() [1].
[1].
В случае простых гипотез предельные распределения статистик непараметрических
критериев типа Колмогорова, ![]() и
и ![]() Мизеса давно известны
и не зависят от вида наблюдаемого закона распределения и от его параметров.
Говорят, что эти критерии являются “свободными от распределения”. Это достоинство
предопределяет широкое использование данных критериев в приложениях.
Мизеса давно известны
и не зависят от вида наблюдаемого закона распределения и от его параметров.
Говорят, что эти критерии являются “свободными от распределения”. Это достоинство
предопределяет широкое использование данных критериев в приложениях.
2. Потеря “свободы от распределения” при проверке сложных гипотез
При проверке сложных
гипотез, когда по той же самой выборке оцениваются параметры наблюдаемого
закона ![]() , непараметрические критерии согласия
теряют свойство “свободы от распределения”. Однако, мощность непараметрических
критериев при проверке сложных гипотез при тех же объемах выборок
, непараметрические критерии согласия
теряют свойство “свободы от распределения”. Однако, мощность непараметрических
критериев при проверке сложных гипотез при тех же объемах выборок ![]() всегда
существенно выше, чем при проверке простых. И если при проверке простых гипотез
непараметрические критерии типа Колмогорова,
всегда
существенно выше, чем при проверке простых. И если при проверке простых гипотез
непараметрические критерии типа Колмогорова, ![]() и
и ![]() Мизеса
уступают по мощности критериям типа
Мизеса
уступают по мощности критериям типа ![]() , при условии, что
в последних используется асимптотически оптимальное группирование [2-5], то
при проверке сложных гипотез непараметрические критерии оказываются более
мощными. Для того чтобы воспользоваться их преимуществами, надо только знать
распределение
, при условии, что
в последних используется асимптотически оптимальное группирование [2-5], то
при проверке сложных гипотез непараметрические критерии оказываются более
мощными. Для того чтобы воспользоваться их преимуществами, надо только знать
распределение ![]() при проверяемой сложной гипотезе.
при проверяемой сложной гипотезе.
Различия в предельных распределениях тех же самых статистик при проверке простых и сложных гипотез настолько существенны, что пренебрегать этим абсолютно недопустимо. Поэтому предостережения против неаккуратного применения критериев согласия при проверке сложных гипотез неоднократно поднимались на страницах печати [6-8].
Начало исследованиям
предельных распределений статистик непараметрических критериев согласия при
сложных гипотезах, было положено работой [9]. В литературных источниках
изложен ряд подходов к использованию непараметрических критериев согласия в
случае проверки сложных гипотез. При достаточно большом объеме выборки ее можно
разбить на две части и по одной из них оценивать параметры, а по другой
проверять согласие [10]. В некоторых частных случаях предельные распределения
статистик исследовались аналитическими методами [11], процентные точки
распределений строились методами статистического моделирования [12-15]. Для
приближенного вычисления вероятностей “согласия” вида ![]() (достигаемого
уровня значимости) строились формулы, дающие достаточно хорошие приближения
при малых значениях соответствующих вероятностей [16-20]. В наших работах
[21-24] исследование распределений статистик непараметрических критериев
согласия и построение моделей этих распределений осуществлялось с
использованием методики компьютерного анализа статистических закономерностей.
(достигаемого
уровня значимости) строились формулы, дающие достаточно хорошие приближения
при малых значениях соответствующих вероятностей [16-20]. В наших работах
[21-24] исследование распределений статистик непараметрических критериев
согласия и построение моделей этих распределений осуществлялось с
использованием методики компьютерного анализа статистических закономерностей.
Как выяснилось, при
проверке сложных гипотез на условный закон распределения статистики ![]() влияет
целый ряд факторов, определяющих “сложность” гипотезы: вид наблюдаемого закона
влияет
целый ряд факторов, определяющих “сложность” гипотезы: вид наблюдаемого закона
![]() ,
соответствующего истинной гипотезе
,
соответствующего истинной гипотезе ![]() ; тип оцениваемого параметра
и количество оцениваемых параметров; в некоторых ситуациях конкретное значение
параметра (например, в случае гамма-распределения); используемый метод
оценивания параметров.
; тип оцениваемого параметра
и количество оцениваемых параметров; в некоторых ситуациях конкретное значение
параметра (например, в случае гамма-распределения); используемый метод
оценивания параметров.
Например, рис. 1
иллюстрирует зависимость ![]() от вида наблюдаемого закона
от вида наблюдаемого закона ![]() ,
соответствующего гипотезе
,
соответствующего гипотезе ![]() , для критерия типа Колмогорова. На рис.
2 показаны распределения статистики
, для критерия типа Колмогорова. На рис.
2 показаны распределения статистики ![]() Мизеса при проверке
согласия с распределением Вейбулла и использовании различных методов
оценивания: оценок максимального правдоподобия (ОМП) и MD-оценок,
получаемых при минимизации значения статистики, используемой в критерии.
Мизеса при проверке
согласия с распределением Вейбулла и использовании различных методов
оценивания: оценок максимального правдоподобия (ОМП) и MD-оценок,
получаемых при минимизации значения статистики, используемой в критерии.
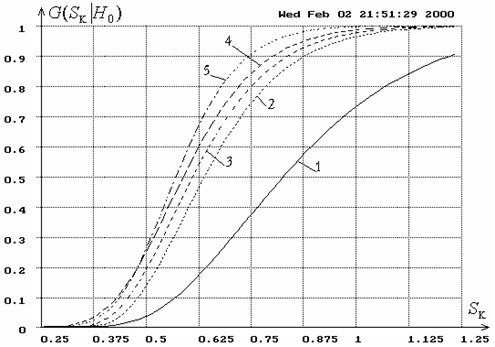
Рис.1. Функции
распределения ![]() статистики
статистики ![]() критерия Колмогорова: 1
– при проверке простой гипотезы; 2 – при вычислении ОМП двух параметров
распределения Лапласа; 3 – при вычислении ОМП двух параметров нормального
распределения; 4 – при вычислении ОМП двух параметров распределения Коши; 5 –
при вычислении ОМП двух параметров логистического распределения.
критерия Колмогорова: 1
– при проверке простой гипотезы; 2 – при вычислении ОМП двух параметров
распределения Лапласа; 3 – при вычислении ОМП двух параметров нормального
распределения; 4 – при вычислении ОМП двух параметров распределения Коши; 5 –
при вычислении ОМП двух параметров логистического распределения.
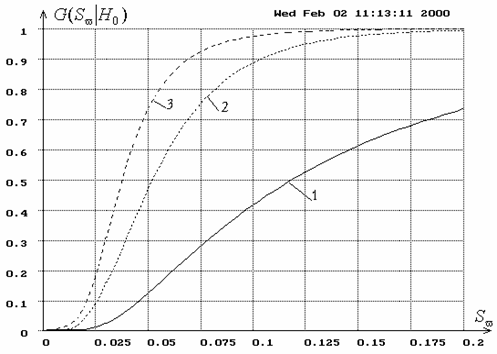
Рис.2. Функции
распределения ![]() статистики
статистики ![]() Мизеса при
проверке согласия с распределением Вейбулла: 1 – при проверке простой гипотезы;
2 – при вычислении ОМП двух параметров распределения;
Мизеса при
проверке согласия с распределением Вейбулла: 1 – при проверке простой гипотезы;
2 – при вычислении ОМП двух параметров распределения;
3 – при вычислении MD-оценок двух параметров.
Распределения статистик критериев
согласия существенно зависят от метода оценивания параметров. Строго говоря,
каждому типу оценок при конкретной сложной проверяемой гипотезе соответствует
своё предельное распределение ![]() статистики. Применяя
непараметрические критерии согласия, следует непременно учитывать используемый
метод оценивания. В случае метода максимального правдоподобия распределения
статистик
статистики. Применяя
непараметрические критерии согласия, следует непременно учитывать используемый
метод оценивания. В случае метода максимального правдоподобия распределения
статистик ![]() очень сильно зависят от закона,
соответствующего гипотезе
очень сильно зависят от закона,
соответствующего гипотезе ![]() . Разброс распределений
. Разброс распределений ![]() при
использовании MD-оценок, минимизирующих статистику критерия, зависит от
закона
при
использовании MD-оценок, минимизирующих статистику критерия, зависит от
закона ![]() , соответствующего гипотезе
, соответствующего гипотезе ![]() , в
существенно меньшей степени.
, в
существенно меньшей степени.
При использовании MD-оценок, минимизирующих статистику критерия, эмпирические
распределения ![]() , соответствующие различным гипотезам
, соответствующие различным гипотезам ![]() ,
имеют минимальный разброс, что позволяет говорить об определенной “свободе от
распределения” для рассматриваемых критериев. Если опираться только на этот
факт, то, казалось бы, что только такие методы оценивания и следует применять
при проверке сложных гипотез. Однако исследование мощности рассматриваемых
критериев при различных методах оценивания показало, что наибольшую мощность
данные критерии при близких альтернативах имеют в случае использования ОМП.
,
имеют минимальный разброс, что позволяет говорить об определенной “свободе от
распределения” для рассматриваемых критериев. Если опираться только на этот
факт, то, казалось бы, что только такие методы оценивания и следует применять
при проверке сложных гипотез. Однако исследование мощности рассматриваемых
критериев при различных методах оценивания показало, что наибольшую мощность
данные критерии при близких альтернативах имеют в случае использования ОМП.
При малых объемах
выборки ![]() распределения
распределения ![]() зависят
от
зависят
от ![]() .
Однако, существенная зависимость распределения статистик от
.
Однако, существенная зависимость распределения статистик от ![]() наблюдается
только при небольших объемах выборки. Как показали исследования, при
наблюдается
только при небольших объемах выборки. Как показали исследования, при ![]() распределения
распределения
![]() достаточно
близки к предельным
достаточно
близки к предельным ![]() и зависимостью от
и зависимостью от ![]() можно
пренебречь.
можно
пренебречь.
3. Построение приближений для предельных распределений статистик
Построенные на настоящий момент таблицы процентных точек и предельные распределения статистик непараметрических критериев ограничены относительно узким кругом сложных гипотез.
Бесконечное множество случайных величин, с которым мы можем столкнуться на практике, не может быть описано ограниченным подмножеством моделей законов распределений, наиболее часто используемых для описания реальных наблюдений в приложениях. Любой исследователь для конкретной наблюдаемой величины может предложить (построить) свою параметрическую модель закона, наиболее адекватно, с его точки зрения, описывающего эту случайную величину. После оценки по данной выборке параметров модели возникает необходимость проверки гипотезы об адекватности выборочных наблюдений и построенного закона с использованием критериев согласия. Далее вопрос упирается в знание предельного распределения статистики, соответствующего данной сложной гипотезе.
Построение предельного распределения аналитическими методами выливается в чрезвычайно непростую задачу. Наиболее целесообразно воспользоваться методикой компьютерного анализа статистических закономерностей, хорошо зарекомендовавшей себя при моделировании распределений статистик критериев [21-24].
Для этого следует в соответствии с законом ![]() смоделировать
смоделировать
![]() выборок
того же объема
выборок
того же объема ![]() , что и выборка, для которой необходимо
проверить гипотезу
, что и выборка, для которой необходимо
проверить гипотезу ![]() :
: ![]() . Далее для каждой из
. Далее для каждой из ![]() выборок
вычислить оценки тех же параметров закона, а затем значение статистики
выборок
вычислить оценки тех же параметров закона, а затем значение статистики ![]() соответствующего
критерия согласия. В результате будет получена выборка значений статистики
соответствующего
критерия согласия. В результате будет получена выборка значений статистики
![]() с
законом распределения
с
законом распределения ![]() для проверяемой гипотезы
для проверяемой гипотезы ![]() . По
этой выборке при значительных
. По
этой выборке при значительных ![]() можно построить достаточно гладкую
эмпирическую функцию распределения
можно построить достаточно гладкую
эмпирическую функцию распределения ![]() , которой можно
непосредственно воспользоваться для вывода о том, следует ли принимать гипотезу
, которой можно
непосредственно воспользоваться для вывода о том, следует ли принимать гипотезу
![]() .
При необходимости можно по
.
При необходимости можно по ![]() построить приближенную аналитическую
модель, аппроксимирующую
построить приближенную аналитическую
модель, аппроксимирующую ![]() , и тогда уже, опираясь на эту модель,
принимать решение относительно проверяемой гипотезы.
, и тогда уже, опираясь на эту модель,
принимать решение относительно проверяемой гипотезы.
Как показали исследования, хорошей аналитической
моделью для ![]() часто оказывается один из следующих
четырех законов: логарифмически нормальный, гамма-распредление, распределение Su-Джонсона
или распределение Sl-Джонсона [23-24]. В крайнем случае, всегда можно,
опираясь на ограниченное множество законов распределения, построить модель в
виде смеси законов.
часто оказывается один из следующих
четырех законов: логарифмически нормальный, гамма-распредление, распределение Su-Джонсона
или распределение Sl-Джонсона [23-24]. В крайнем случае, всегда можно,
опираясь на ограниченное множество законов распределения, построить модель в
виде смеси законов.
Реализация такой процедуры компьютерного анализа распределений статистики в настоящий момент не содержит ни принципиальных, ни практических трудностей. Уровень вычислительной техники позволяет очень быстро получить результаты моделирования, а реализация алгоритма под силу инженеру, владеющему навыками программирования. В данной работе построены модели, аппроксимирующие предельные распределения статистик для ряда сложных гипотез при использовании ОМП и MD-оценок.
В табл. 1 приведен список распределений, относительно которых могут проверяться сложные гипотезы о согласии с использованием построенных приближений предельных законов статистик. Модели распределений статистик, построенные в результате применения методики, представлены в таблицах 2-7.
Таблица 1
|
№ п/п |
Распределение случайной величины |
Функция плотности |
|
1 |
Экспоненциальное |
|
|
2 |
Полунормальное |
|
|
3 |
Рэлея |
|
|
4 |
Максвелла |
|
|
5 |
Лапласа |
|
|
6 |
Нормальное |
|
|
7 |
Логнормальное |
|
|
8 |
Коши |
|
|
9 |
Логистическое |
|
|
10 |
Наибольшего значения |
|
|
11 |
Наименьшего значения |
|
|
12 |
Вейбулла |
|
|
13 |
Гамма-распределение |
|
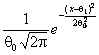
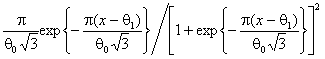
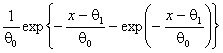
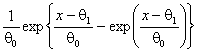
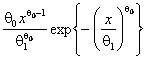
В таблицах 2-7, содержащих рекомендуемые для использования
при проверке сложных гипотез распределения ![]() , через
, через ![]() обозначено
логарифмически нормальное распределение с функцией плотности
обозначено
логарифмически нормальное распределение с функцией плотности
![]() ,
,
через
![]() -
гамма-распределение с функцией плотности
-
гамма-распределение с функцией плотности
![]() ,
,
через
![]() -
распределение Sl-Джонсона с плотностью
-
распределение Sl-Джонсона с плотностью
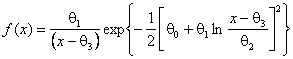 ,
,
через ![]() -
распределение Su-Джонсона с плотностью
-
распределение Su-Джонсона с плотностью
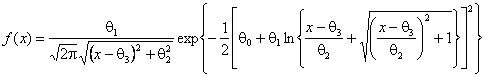 .
.
В качестве примера покажем, насколько сильно меняется вероятность ![]() при
одном и том же значении статистики в случае простой и сложной гипотез.
Продемонстрируем это на критерии типа
при
одном и том же значении статистики в случае простой и сложной гипотез.
Продемонстрируем это на критерии типа ![]() Мизеса.
Мизеса.
Таблица 2
|
Аппроксимация предельных распределений статистики Колмогорова при использовании метода максимального правдоподобия |
||||
|
№ п/п |
Распределение случайной величины |
При оценивании только масштабного параметра |
При оценивании только параметра сдвига |
При оценивании двух параметров |
|
1 |
Экспоненциальное |
lnN(-0.3422,0.2545) |
|
|
|
2 |
Полунормальное |
g(4.1332,0.1076,0.3205) |
|
|
|
3 |
Рэлея |
lnN(-0.3388,0.2621) |
|
|
|
4 |
Максвелла |
lnN(-0.3461,0.2579) |
|
|
|
5 |
Лапласа |
g(3.7580,0.1365,0.3163) |
g(4.6474,0.0870,0.3091) lnN(-0.3690,0.2499) |
g(4.4525,0.0761,0.3252) lnN(-0.4358,0.2276) |
|
6 |
Нормальное |
g(3.7460,0.1385,0.3142) |
lnN(-0.4172,0.2272) |
g(4.9014,0.0691,0.2951) lnN(-0.4825,0.2296) |
|
7 |
Логнормальное |
g(3.0622,0.1577,0.3547) |
Su(-2.0328, 2.3642, 0.2622, 0.4072) |
Su(-1.8093, 1.9041, 0.1861, 0.4174) |
|
8 |
Коши |
Su(-3.3278, 2.2529, 0.2185, 0.2858) |
g(4.8247,0.0874,0.2935) |
lnN(-0.5302,0.2427) |
|
9 |
Логистическое |
g(3.2167,0.1476,0.3538) |
Su(-2.8534, 3.0657, 0.2872, 0.3199) |
lnN(-0.5611,0.2082) |
|
10 |
Наибольшего значения |
g(3.3841,0.1439,0.3509) |
g(4.1008,0.0997,0.3269) |
g(4.9738,0.0660,0.3049) |
|
11 |
Наименьшего значения |
g(3.3841,0.1439,0.3509) |
g(4.1008,0.0997,0.3269) |
g(4.9738,0.0660,0.3049) |
|
12 |
Вейбулла |
g(3.3841,0.1439,0.3509) ** |
g(4.1008,0.0997,0.3269) * |
g(4.9738,0.0660,0.3049) |
** - оценивался параметр формы распределения Вейбулла;
* - оценивался параметр масштаба распределения Вейбулла.
Таблица 3
|
Аппроксимация предельных распределений минимума статистики Колмогорова (при использовании MD-оценок, минимизирующих статистику |
||||
|
№ п/п |
Распределение случайной величины |
При оценивании только масштабного параметра |
При оценивании только параметра сдвига |
При оценивании двух параметров |
|
1 |
Экспоненциальное |
g(4.4983,0.0621,0.2891) |
|
|
|
2 |
Полунормальное |
g(4.2884,0.0705,0.3072) |
|
|
|
3 |
Рэлея |
g(4.8579,0.0639,0.2900) |
|
|
|
4 |
Максвелла |
g(5.3106,0.0581,0.2865) |
|
|
|
5 |
Лапласа |
g(3.0431,0.1355,0.3182) |
g(5.0103,0.0602,0.2968) lnN(-0.5358,0.2122) |
Su(-2.1079, 2.4629, 0.1661, 0.3340) lnN(-0.6970,0.1952) |
|
6 |
Нормальное |
g(3.2458,0.1343,0.3072) |
lnN(-0.5469,0.2152) |
lnN(-0.7236,0.1837) |
|
7 |
Логнормальное |
g(3.2458,0.1343,0.3072) |
lnN(-0.5469,0.2152) |
lnN(-0.7236,0.1837) |
|
8 |
Коши |
g(3.4398,0.1255,0.3022) |
lnN(-0.5182,0.2268) |
Su(-1.6929, 2.5234, 0.1892, 0.3607) lnN(-0.6946,0.1938) |
|
9 |
Логистическое |
Su(-2.6522,1.8288, 0.1738, 0.3384) g(3.6342,0.1284,0.2772) |
Su(-3.8497, 3.2770, 0.2136, 0.2607) lnN(-0.5511,0.2045) |
lnN(-0.7389,0.1771) Su(-2.5093, 3.1277, 0.1932, 0.3041) |
|
10 |
Наибольшего значения |
g(3.5424,0.1203,0.2975) |
Su(-1.9028, 2.3972, 0.2227, 0.389) |
Su(-1.3144, 2.2480, 0.1616,0.3858) lnN(-0.7174, 0.1841) |
|
11 |
Наименьшего значения |
g(3.5424, 0.1203,0.2975) |
Su(-1.9028, 2.3972, 0.2227, 0.389) |
Su(-1.3144, 2.2480, 0.1616,0.3858) lnN(-0.7174, 0.1841) |
|
12 |
Вейбулла |
g(3.5424, 0.1203, 0.2975) ** |
Su(-1.9028, 2.3972, 0.2227, 0.389) * |
Su(-1.3144, 2.2480, 0.1616,0.3858) lnN(-0.7174, 0.1841) |
** - оценивался параметр формы распределения Вейбулла;
* - оценивался параметр масштаба распределения Вейбулла.
Таблица 4
|
Аппроксимация предельных распределений статистики при использовании метода максимального правдоподобия |
||||
|
№ п/п |
Распределение случайной величины |
При оценивании только масштабного параметра |
При оценивании только параметра сдвига |
При оценивании двух параметров |
|
1 |
Экспоненциальное |
Su(-1.8734,1.2118, 0.0223, 0.0240) |
|
|
|
2 |
Полунормальное |
Sl(0.9735,1.1966, 0.1531, 0.0116) |
|
|
|
3 |
Рэлея |
Su(-1.5302,1.0371, 0.0202, 0.0299) |
|
|
|
4 |
Максвелла |
Su(-2.0089,1.2557, 0.0213, 0.0213) |
|
|
|
5 |
Лапласа |
Sl(0.9719,0.9805,0.2347, 0.0139) |
Su(-2.0821,1.2979, 0.0196, 0.0200) |
Su(-1.6085,1.2139, 0.0171, 0.0247) |
|
6 |
Нормальное |
Su(-2.2550,0.9569, 0.0152, 0.0212) |
lnN(-2.7536,0.5610) |
lnN(-2.9794,0.5330) |
|
7 |
Логнормальное |
Sl(1.0669,1.0010, 0.2537, 0.0144) |
lnN(-2.7271,0.6092) |
Su(-1.6292, 1.1541, 0.0144, 0.0234) |
|
8 |
Коши |
Sl(1.0086,1.0539, 0.2282, 0.0064) |
Sl(1.1230,1.2964, 0.1383, 0.0105) |
Sl(1.2420,1.2833, 0.1135, 0.0064) |
|
9 |
Логистическое |
Sl(0.9982,1.0287, 0.2303, 0.0126) |
Sl(1.3982,1.3804, 0.1205, 0.0102) |
lnN(-3.1416,0.4989) |
|
10 |
Наибольшего значения |
Sl(1.0056, 1.0452, 0.2296, 0.0137) |
lnN(-2.5818,0.6410) |
lnN(-2.9541,0.5379) |
|
11 |
Наименьшего значения |
Sl(1.0056, 1.0452, 0.2296, 0.0137) |
lnN(-2.5818,0.6410) |
lnN(-2.9541,0.5379) |
|
12 |
Вейбулла |
Sl(1.0056, 1.0452, 0.2296, 0.0137) ** |
lnN(-2.5818,0.6410) * |
lnN(-2.9541,0.5379) |
** - оценивался параметр формы распределения Вейбулла;
* - оценивался параметр масштаба распределения Вейбулла.
Таблица 5
|
Аппроксимация предельных распределений минимума
статистики (при использовании MD-оценок, минимизирующих статистику |
||||
|
№ п/п |
Распределение случайной величины |
При оценивании только масштабного параметра |
При оценивании только параметра сдвига |
При оценивании двух параметров |
|
1 |
Экспоненциальное |
Su(-1.9324,1.1610, 0.0134, 0.0203) |
|
|
|
2 |
Полунормальное |
Su(-1.5024,1.0991, 0.0173, 0.0256) |
|
|
|
3 |
Рэлея |
Su(-1.4705,1.1006, 0.0164, 0.0259) |
|
|
|
4 |
Максвелла |
Su(-1.7706,1.2978, 0.0188, 0.0220) |
|
|
|
5 |
Лапласа |
Sl(1.0117, 0.9485, 0.2162, 0.0137) |
lnN(-2.8601,0.5471) |
lnN(-3.2853,0.4666) |
|
6 |
Нормальное |
Sl(1.0477, 0.9883, 0.2356, 0.0112) |
lnN(-2.8649,0.5668) |
lnN(-3.2715,0.4645) |
|
7 |
Логнормальное |
Sl(1.0477, 0.9883, 0.2356, 0.0112) |
lnN(-2.8649,0.5668) |
lnN(-3.2715,0.4645) |
|
8 |
Коши |
Sl(1.2759, 1.0437, 0.2825, 0.0089) |
lnN(-2.8577,0.5739) |
lnN(-3.2603,0.4874) |
|
9 |
Логистическое |
Sl(1.0898,1.0225, 0.2399, 0.0096) |
lnN(-2.8831,0.5367) |
lnN(-3.2915,0.4592) |
|
10 |
Наибольшего значения |
Sl(1.0771, 1.0388, 0.2065, 0.0109) |
Su(-1.5348,1.1226, 0.0166, 0.0252) |
Su(-1.5326, 1.4446, 0.0147, 0.0188) lnN(-3.2627,0.4680) |
|
11 |
Наименьшего значения |
Sl(1.0771, 1.0388, 0.2065, 0.0109) |
Su(-1.5348,1.1226, 0.0166, 0.0252) |
Su(-1.5326, 1.4446, 0.0147, 0.0188) lnN(-3.2627,0.4680) |
|
12 |
Вейбулла |
Sl(1.0771, 1.0388, 0.2065, 0.0109) ** |
Su(-1.5348,1.1226, 0.0166, 0.0252) * |
Su(-1.5326, 1.4446, 0.0147, 0.0188) lnN(-3.2627,0.4680) |
** - оценивался параметр формы распределения Вейбулла;
* - оценивался параметр масштаба распределения Вейбулла.
Таблица 6
|
Аппроксимация предельных распределений статистики при использовании метода максимального правдоподобия |
||||
|
№ п/п |
Распределение случайной величины |
При оценивании только масштабного параметра |
При оценивании только параметра сдвига |
При оценивании двух параметров |
|
1 |
Экспоненциальное |
Su(-2.8653,1.4220, 0.1050,0.1128) |
|
|
|
2 |
Полунормальное |
Su(-2.5603,1.3116, 0.1147,0.1330) |
|
|
|
3 |
Рэлея |
Su(-2.5610,1.4003, 0.1174,0.1337) |
|
|
|
4 |
Максвелла |
Su(-2.6064,1.4426, 0.1190,0.1285) |
|
|
|
5 |
Лапласа |
Sl(0.3148, 1.0999, 0.6901, 0.1093) |
Su(-2.5528,1.4006, 0.1216,0.1358) |
Su(-2.8942,1.4897, 0.0846,0.1131) |
|
6 |
Нормальное |
Su(-2.3507,1.0531, 0.1012,0.1595) |
Su(-3.1202,1.5233, 0.0874,0.1087) |
Su(-2.7057,1.7154, 0.1043,0.0925) |
|
7 |
Логнормальное |
Su(-2.4168, 1.1296, 0.1151, 0.1560) |
lnN(-0.8052, 0.5123) |
Su(-2.3966, 1.5967, 0.1012, 0.1179) |
|
8 |
Коши |
Su(-2.4935, 1.0789, 0.0923, 0.1458) |
Su(-2.8420,1.3528, 0.1010,0.1221) |
Su(-2.3195,1.1812, 0.0769,0.1217) |
|
9 |
Логистическое |
Sl(0.3065, 1.1628, 0.7002, 0.0930) |
Su(-3.5408,1.6041, 0.0773,0.0829) |
lnN(-1.1452,0.4426) |
|
10 |
Наибольшего значения |
Su(-2.5427, 1.1057, 0.0960, 0.1569) |
Su(-2.5550, 1.3714, 0.1152, 0.1289) |
Su(-2.4622, 1.6473, 0.1075, 0.1149) |
|
11 |
Наименьшего значения |
Su(-2.5427, 1.1057, 0.0960, 0.1569) |
Su(-2.5550, 1.3714, 0.1152, 0.1289) |
Su(-2.4622, 1.6473, 0.1075, 0.1149) |
|
12 |
Вейбулла |
Su(-2.5427, 1.1057, 0.0960, 0.1569) ** |
Su(-2.5550, 1.3714, 0.1152, 0.1289) * |
Su(-2.4622, 1.6473, 0.1075, 0.1149) |
** - оценивался параметр формы распределения Вейбулла;
* - оценивался параметр масштаба распределения Вейбулла.
Таблица 7
|
Аппроксимация предельных распределений минимума
статистики (при использовании MD-оценок, минимизирующих статистику |
||||
|
№ п/п |
Распределение случайной величины |
При оценивании только масштабного параметра |
При оценивании только параметра сдвига |
При оценивании двух параметров |
|
1 |
Экспоненциальное |
Su(-2.6741,1.4068, 0.0958,0.1230) |
|
|
|
2 |
Полунормальное |
Su(-2.6752,1.3763, 0.0952,0.1280) |
|
|
|
3 |
Рэлея |
Su(-2.2734,1.3473, 0.1101,0.1496) |
|
|
|
4 |
Максвелла |
Su(-2.2759,1.3988, 0.1171,0.1514) |
|
|
|
5 |
Лапласа |
Su(-2.3884,1.0811, 0.0948, 0.1548) |
Su(-2.7267,1.4972, 0.1044,0.1239) |
Su(-2.4334,1.6104, 0.0902,0.1123) |
|
6 |
Нормальное |
Su(-2.4180, 1.0702, 0.0957, 0.1464) |
Su(-2.7639, 1.5393, 0.1102, 0.1115) |
Su(-2.5746, 1.7505, 0.0979, 0.1043) lnN(-1.1651,0.4271) |
|
7 |
Логнормальное |
Su(-2.4180, 1.0702, 0.0957, 0.1464) |
Su(-2.7639, 1.5393, 0.1102, 0.1115) |
Su(-2.5746, 1.7505, 0.0979, 0.1043) llnN(-1.1651,0.4271) |
|
8 |
Коши |
Su(-2.5043,1.1355, 0.1035,0.1384) |
Su(-2.7029,1.5179, 0.1188,0.1100) |
Su(-2.1046,1.4364, 0.0929,0.1301) lnN(-1.1043,0.4692) |
|
9 |
Логистическое |
Sl(0.3223,1.1159,0.6836, 0.0953) Su(-2.3007,1.0135, 0.0906,0.1593) |
Su(-2.6212,1.4318, 0.0932,0.1370) |
Su(-3.0152,1.7751, 0.0800,0.0898) |
|
10 |
Наибольшего значения |
Su(-2.4454, 1.1083, 0.0968, 0.1459) |
Su(-2.6557, 1.4282, 0.1024, 0.1254) |
Su(-2.1580, 1.5446, 0.0941, 0.1279) |
|
11 |
Наименьшего значения |
Su(-2.4454, 1.1083, 0.0968, 0.1459) |
Su(-2.6557, 1.4282, 0.1024, 0.1254) |
Su(-2.1580, 1.5446, 0.0941, 0.1279) |
|
12 |
Вейбулла |
Su(-2.4454, 1.1083, 0.0968, 0.1459) ** |
Su(-2.6557, 1.4282, 0.1024, 0.1254) * |
Su(-2.1580, 1.5446, 0.0941, 0.1279) |
** - при оценивании параметра формы распределения Вейбулла;
* - при оценивании параметра масштаба распределения Вейбулла.
Пример. Пусть проверяется гипотеза о согласии с
распределением Вейбулла и вычисленное значение статистики ![]() . Тогда в
случае простой гипотезы на основании распределения
. Тогда в
случае простой гипотезы на основании распределения ![]() [1]
находим, что
[1]
находим, что ![]() . Если по выборке были вычислены ОМП двух
параметров распределения, то хорошей аппроксимацией предельного распределения
(табл. 4) является логарифмически нормальное lnN(-2.9541,0.5379), а соответствующая
вероятность
. Если по выборке были вычислены ОМП двух
параметров распределения, то хорошей аппроксимацией предельного распределения
(табл. 4) является логарифмически нормальное lnN(-2.9541,0.5379), а соответствующая
вероятность ![]() . При использовании MD-оценок в
аналогичной ситуации наиболее подходящей моделью (табл. 5) является
распределение Su-Джонсона Su(-1.5326, 1.4446, 0.0147, 0.0188), в соответствии с которым
. При использовании MD-оценок в
аналогичной ситуации наиболее подходящей моделью (табл. 5) является
распределение Su-Джонсона Su(-1.5326, 1.4446, 0.0147, 0.0188), в соответствии с которым ![]() .
.
4. Выводы
При проверке сложных
гипотез и выборе (или построении) распределений статистик ![]() критериев
согласия необходимо учитывать все факторы, влияющие на закон распределения
статистики: вид наблюдаемого закона; тип оцениваемого параметра и количество
оцениваемых параметров; в некоторых ситуациях конкретное значение параметра;
используемый метод оценивания параметров.
критериев
согласия необходимо учитывать все факторы, влияющие на закон распределения
статистики: вид наблюдаемого закона; тип оцениваемого параметра и количество
оцениваемых параметров; в некоторых ситуациях конкретное значение параметра;
используемый метод оценивания параметров.
Построенные аппроксимации предельных распределений статистик непараметрических критериев согласия расширяют область корректного применения этих критериев и могут быть рекомендованы широкому кругу исследователей. Апробированная методика моделирования распределений статистик может быть рекомендована для построения статистических закономерностей в ситуации, когда аналитическими методами не удается решить задачу.
Литература
1. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. – М.: Наука, 1983. – 416 с.
2. Денисов В.И., Лемешко Б.Ю., Цой Е.Б. Оптимальное группирование, оценка параметров и планирование регрессионных экспериментов: В 2 ч. / Новосиб. гос. техн. ун–т. – Новосибирск, 1993. – 346 с.
3. Лемешко Б.Ю. Асимптотически оптимальное группирование наблюдений – это обеспечение максимальной мощности критериев // Надежность и контроль качества. – 1997. – № 8. – С. 3–14.
4. Лемешко Б.Ю. Асимптотически оптимальное группирование наблюдений в критериях согласия // Заводская лаборатория. – 1998. – Т. 64. – №1. – С. 56-64.
5.
Денисов
В.И., Лемешко Б.Ю., Постовалов С.Н. Прикладная статистика. Правила проверки
согласия опытного распределения с теоретическим: Методические рекомендации.
Часть I. Критерии типа ![]() . – Новосибирск: Изд–во НГТУ, 1998. – С.
126.
. – Новосибирск: Изд–во НГТУ, 1998. – С.
126.
6. Орлов А.И. Распространенная ошибка при использовании критериев Колмогорова и омега–квадрат // Заводская лаборатория. – 1985. – Т. 51. – №1. – С. 60-62.
7. Бондарев Б.В. О проверке сложных статистических гипотез // Заводская лаборатория. – 1986. – Т. 52. – № 10. – С. 62-63.
8. Кулинская Е.В., Саввушкина Н.Е. О некоторых ошибках в реализации и применении непараметрических методов в пакете для IBM PC // Заводская лаборатория. – 1990. – Т. 56. – № 5. – С. 96-99.
9.
Kac M., Kiefer J., Wolfowitz J. On tests of normality and other tests of goodness of fit based on
distance methods // Ann. Math. Stat. – 1955. – V.26. – P.189-211.
10. Durbin J. Kolmogoriv–Smirnov test when parameters are estimated // Lect. Notes Math. – 1976. – V. 566. – P. 33–44.
11. Мартынов Г.В. Критерии омега–квадрат. – М.: Наука, 1978. – 80 с.
12. Pearson E.S., Hartley H.O. Biometrica
tables for Statistics. V.2. –
13. Stephens M.A. Use of
Kolmogorov–Smirnov, Cramer – von Mises and related statistics – vithout
extensive table // J. R. Stat. Soc. – 1970. – B. 32. – P. 115-122.
14. Stephens M.A. EDF statistics for
goodness of fit and some comparisons // J. Am. Statist. Assoc. – 1974. – V.69.
– P. 730-737.
15. Chandra M.,
16. Тюрин Ю.Н. О предельном распределении статистик Колмогорова–Смирнова для сложной гипотезы // Изв. АН СССР. Сер. Матем. – 1984. – Т. 48. – № 6. – C. 1314-1343.
17. Тюрин Ю.Н., Саввушкина Н.Е. Критерии согласия для распределения Вейбулла–Гнеденко. // Изв. АН СССР. Сер. Техн. Кибернетика. – 1984. – № 3. – C. 109-112.
18. Тюрин Ю.Н. Исследования по непараметрической статистике (непараметрические методы и линейная модель): Автореф. дисс. … д–ра физ.–мат. наук. – М., 1985. – 33 с. – (МГУ).
19. Саввушкина Н.Е. Критерий Колмогорова–Смирнова для логистического и гамма–распределения // Сб. тр. ВНИИ систем. исслед. – 1990, № 8.
20. Тюрин Ю.Н., Макаров А.А. Анализ данных на компьютере. // М.: ИНФРА–М, Финансы и статистика, 1995. – 384 с.
21. Лемешко Б.Ю., Постовалов С.Н. Прикладные аспекты использования критериев согласия в случае проверки сложных гипотез // Надежность и контроль качества. – 1997. – № 11. – С. 3-17.
22. Лемешко Б.Ю., Постовалов С.Н. Исследование допредельных распределений статистик критериев согласия при проверке сложных гипотез // Тр. IV международной конференции “Актуальные проблемы электронного приборостроения”. – Новосибирск. – 1998. – Т. 3. – С. 12-16.
23. Лемешко Б.Ю., Постовалов С.Н. О распределениях статистик непараметрических критериев согласия при оценивании по выборкам параметров наблюдаемых законов // Заводская лаборатория. – 1998. – Т. 64. – № 3. – С. 61-72.
24. Лемешко Б.Ю., Постовалов
С.Н. Прикладная
статистика. Правила проверки согласия опытного распределения с теоретическим.
Методические рекомендации. Часть II. Непараметрические критерии. –
Новосибирск: Изд-во НГТУ. – 1999. – 86 с.