См. также: Прикладная
математическая статистика (материалы к семинарам)
Метрология. 2004. № 7. – С. 8-17
519.25
О задаче идентификации закона распределения случайной составляющей погрешности измерений[1]
ЛЕМЕШКО Б.Ю.
Сравниваются подходы к задаче идентификации закона распределения. Показывается предпочтительность подхода, базирующегося на аппарате математической статистики. Отмечаются недостатки при решении задач идентификации на практике.
Ключевые слова: закон распределения, оценка параметров, критерии согласия, проверка сложных гипотез.
The approaches to the
distribution law identification have been compared. The approach based on
mathematical statistics methods has been shown to be preferable. Failings in
solving the identification problem in practice have been pointed out.
Key words: distribution laws,
estimation of parameters, goodness-of-fit tests, composite hypothesis testing.
Введение. Под задачей идентификации закона распределения наблюдаемой случайной величины (структурно-параметрической идентификации), как правило, понимают задачу выбора такой параметрической модели закона распределения вероятностей, которая наилучшим образом соответствует результатам экспериментальных наблюдений. Случайные ошибки средств измерений не так уж часто подчиняются нормальному закону [1], точнее, не так часто хорошо описываются моделью нормального закона. В основе измерительных приборов и систем лежат различные физические принципы, различные методы измерений и различные преобразования измерительных сигналов. Погрешности измерений как величины являются следствием влияния множества факторов, случайного и неслучайного характера, действующих постоянно или эпизодически. Поэтому понятно, что только при выполнении определенных предпосылок (теоретических и технических) погрешности измерений достаточно хорошо описываются моделью нормального закона.
Вообще говоря, следует понимать, что истинный закон распределения (если он, конечно, существует), описывающий погрешности конкретной измерительной системы, остается (останется) неизвестным, не смотря на все наши попытки его идентифицировать. На основании данных измерений и теоретических соображений мы можем только подобрать вероятностную модель, которая в некотором смысле наилучшим образом приближает этот истинный закон. Если построенная модель адекватна, то есть применяемые критерии не дают оснований для ее отклонения, то на основе данной модели можно вычислить все интересующие нас вероятностные характеристики случайной составляющей погрешности измерительного средства, которые будут отличаться от истинных значений только за счет неисключенной систематической (ненаблюдаемой или нерегистрируемой) составляющей погрешности измерений. Ее малость и характеризует правильность измерений.
Множество возможных законов распределения вероятностей, которые можно использовать для описания наблюдаемых случайных величин, неограничено. Бессмысленно ставить целью задачи идентификации нахождение истинного закона распределения наблюдаемой величины. Мы можем лишь решать задачу выбора наилучшей модели из некоторого множества. Например, из того множества параметрических законов и семейств распределений, которые используются в приложениях, и упоминание о которых можно найти в литературных источниках.
Классический подход к структурно-параметрической идентификации закона распределения. Под классическим подходом будем понимать алгоритм выбора закона распределения, целиком базирующийся на аппарате математической статистики. Такой подход к идентификации закона распределения заключается в последовательной реализации следующей двухэтапной процедуры для каждого вида параметрической модели из рассматриваемого множества законов. На первом этапе процедуры на основании выборочных данных строится модель закона определенного вида (из рассматриваемого множества моделей), оцениваются параметры этой модели. На втором этапе оценивается степень адекватности полученной модели экспериментальным наблюдениям, как правило, с применением различных критериев согласия.
Эти два этапа для ![]() -й модели из множества моделей
размерности
-й модели из множества моделей
размерности ![]() можно записать как задачу проверки сложной гипотезы с
использованием критерия согласия
можно записать как задачу проверки сложной гипотезы с
использованием критерия согласия
![]() :
: ![]() ,
(1)
,
(1)
где ![]() – функция распределения вероятностей
известного вида, но с неизвестным значением параметра
– функция распределения вероятностей
известного вида, но с неизвестным значением параметра ![]() , принадлежащим пространству параметров
, принадлежащим пространству параметров
![]() ,
, ![]() . Подчеркнем, что в ходе проверки
сложной гипотезы оценка параметра
. Подчеркнем, что в ходе проверки
сложной гипотезы оценка параметра ![]() вычисляется по этой же самой
выборке. В процессе проверки гипотезы
вычисляется по этой же самой
выборке. В процессе проверки гипотезы ![]() по выборке вычисляется значение
по выборке вычисляется значение
![]() статистики используемого
критерия согласия. На основании условного распределения
статистики используемого
критерия согласия. На основании условного распределения ![]() статистики
статистики ![]() критерия вычисляется вероятность
(достигнутый уровень значимости)
критерия вычисляется вероятность
(достигнутый уровень значимости)
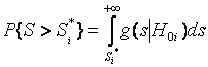 ,
(2)
,
(2)
где ![]() – условная плотность
распределения статистики критерия при справедливости гипотезы
– условная плотность
распределения статистики критерия при справедливости гипотезы ![]() .
.
В процессе идентификации
выбирается та модель ![]() закона распределения, на предпочтительность которой в
вероятностном смысле (по достигаемому уровню значимости
закона распределения, на предпочтительность которой в
вероятностном смысле (по достигаемому уровню значимости ![]() ) указывает используемый
статистический критерий:
) указывает используемый
статистический критерий:
![]() ,
(3)
,
(3)
где ![]() – задаваемый уровень значимости
(вероятность ошибки первого рода – отклонить справедливую гипотезу
– задаваемый уровень значимости
(вероятность ошибки первого рода – отклонить справедливую гипотезу ![]() ).
).
Успех данного подхода
зависит от двух условий: полноты рассматриваемого множества моделей и
корректности применения соответствующих статистических методов. Последнее
касается как используемых методов оценивания параметров, так и критериев
проверки статистических гипотез. При проверке сложных гипотез вида (1)
обязательно следует учитывать, что на распределения статистик критериев
согласия влияют используемые методы оценивания параметров. О типичных ошибках
применения критериев типа ![]() подробно говорится в [2], а об ошибках применения
непараметрических критериев – в [3].
подробно говорится в [2], а об ошибках применения
непараметрических критериев – в [3].
Достаточно представительное множество моделей для решения конкретной задачи идентификации в настоящее время можно рассматривать только с использованием соответствующего программного обеспечения. В этом случае предпочтительнее программные системы, обеспечивающие выбор из большего числа видов законов распределений [4, 5] и позволяющие компоновать модели законов распределений в виде смесей законов (двух и более) из имеющегося множества моделей [6-9].
Классический подход к задаче идентификации, на наш взгляд, является наиболее предпочтительным, хотя бы в связи с тем, что полученные по выборкам значения статистик используемых критериев согласия определяют соответствующие расстояния между эмпирическим и теоретическим законом распределения.
Так как в критериях
согласия типа ![]() [10], в непараметрических критериях типа Колмогорова,
типа
[10], в непараметрических критериях типа Колмогорова,
типа ![]() Крамера-Мизеса-Смирнова, типа
Крамера-Мизеса-Смирнова, типа
![]() Андерсона-Дарлинга
[11] используются различные меры, то критерии по-разному улавливают в
выборках различные отклонения от предполагаемых теоретических законов. В этой
связи проверку гипотез (1) и идентификацию закона целесообразно проводить с
использованием ряда критериев согласия. В этом случае окончательное решение
может быть принято либо по совокупности критериев, когда выбирается модель
Андерсона-Дарлинга
[11] используются различные меры, то критерии по-разному улавливают в
выборках различные отклонения от предполагаемых теоретических законов. В этой
связи проверку гипотез (1) и идентификацию закона целесообразно проводить с
использованием ряда критериев согласия. В этом случае окончательное решение
может быть принято либо по совокупности критериев, когда выбирается модель ![]() , для которой достигаемый уровень
значимости по всем критериям максимален
, для которой достигаемый уровень
значимости по всем критериям максимален
![]() ,
(4)
,
(4)
где ![]() – число используемых критериев
согласия, либо по некоторому компромиссному, взвешенному критерию.
– число используемых критериев
согласия, либо по некоторому компромиссному, взвешенному критерию.
Предпочтительность
данного подхода можно связать и с появлением рекомендаций по стандартизации
[10, 11]. Благодаря рекомендациям [10] стала возможной проверка сложных гипотез
вида (1) с использованием непараметрических критериев согласия при достаточно
представительном множестве законов распределений, а приводимые в рекомендациях
[11] таблицы асимптотически оптимального группирования повышают
идентификационные возможности критериев типа ![]() (вследствие большей мощности
критериев по отношению к близким альтернативам).
(вследствие большей мощности
критериев по отношению к близким альтернативам).
Успех в выборе модели закона, наилучшим образом описывающего наблюдаемую случайную величину, не в последнюю очередь зависит от применяемых методов оценивания. Желательно, чтобы используемые методы давали оценки параметров, обладающие лучшими статистическими свойствами (несмещенные, состоятельные и эффективные или асимптотически эффективные оценки). Желательно, чтобы оценки были робастными, то есть устойчивыми к малым отклонениям от предположений, к выбросам. Однако хорошие статистические свойства оценок не всегда сопровождаются свойствами робастности.
При учете введенной Рао [12] эффективности второго порядка наилучшими статистическими
свойствами обладают оценки максимального правдоподобия (ОМП), получаемые в
результате максимизации по ![]() функции правдоподобия
функции правдоподобия
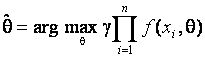 ,
(5)
,
(5)
где ![]() – некоторая константа, и
– некоторая константа, и ![]() – функция плотности, зависящая
от параметра
– функция плотности, зависящая
от параметра ![]() ,
, ![]() – объем выборки,
– объем выборки, ![]() – выборочные наблюдения. Однако
ОМП по точечным (негруппированным) выборкам, за
редким исключением, не являются робастными [13]. Поэтому имеющиеся в реальных
выборках выбросы и другие отклонения от предполагаемого закона могут испортить
всю картину.
– выборочные наблюдения. Однако
ОМП по точечным (негруппированным) выборкам, за
редким исключением, не являются робастными [13]. Поэтому имеющиеся в реальных
выборках выбросы и другие отклонения от предполагаемого закона могут испортить
всю картину.
Следовательно, используя ОМП, необходимо быть уверенным в отсутствии в выборке аномальных измерений или исключить их в процессе обработки. Для этого могут применяться робастные методы оценивания и параметрические алгоритмы отбраковки, опирающиеся на эти методы [14]. Высокой устойчивостью к наличию в выборках аномальных наблюдений обладают ОМП по группированным данным [13] и оптимальные L-оценки по выборочным квантилям [15, 16]. Хорошие робастные свойства [17] у MD-оценок [18], определяемых соотношением
![]() ,
(6)
,
(6)
где ![]() –
эмпирическая функция распределения,
–
эмпирическая функция распределения, ![]() – расстояние
в пространстве функций распределения для функций
– расстояние
в пространстве функций распределения для функций ![]() и
и ![]() . Любая
статистика, из используемых в критериях согласия, может быть положена в основу
этого метода оценивания.
. Любая
статистика, из используемых в критериях согласия, может быть положена в основу
этого метода оценивания.
Признаком наличия в
анализируемой выборке выбросов (данных или результатов измерений, аномальных с
позиций рассматриваемого закона ![]() ) может являться существенное
отличие в значениях ОМП и некоторой робастной оценки, например, ОМП по сгруппированным
данным. В этом случае, опираясь на робастную оценку параметра
) может являться существенное
отличие в значениях ОМП и некоторой робастной оценки, например, ОМП по сгруппированным
данным. В этом случае, опираясь на робастную оценку параметра ![]() , следует воспользоваться параметрическим
алгоритмом отбраковки [14], исключив выбросы, а затем снова вычислить ОМП.
, следует воспользоваться параметрическим
алгоритмом отбраковки [14], исключив выбросы, а затем снова вычислить ОМП.
Топологические методы
идентификации. Существует
ряд подходов, упоминаемых в [19], общим для которых является попытка идентифицировать
вид закона распределения на основании значений оценок некоторых числовых
характеристик, вычисляемых по выборочным данным. Например, по значениям
оценок коэффициентов асимметрии 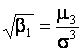 и эксцесса
и эксцесса 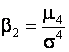 , где
, где ![]() – центральный момент случайной
величины порядка
– центральный момент случайной
величины порядка ![]() ,
, ![]() . Подставив в выражения для коэффициентов асимметрии и
эксцесса оценки соответствующих моментов, получим точку в плоскости (
. Подставив в выражения для коэффициентов асимметрии и
эксцесса оценки соответствующих моментов, получим точку в плоскости (![]() ,
,![]() ), положение которой укажет нам наиболее
предпочтительный закон распределения. В [1] решение предлагается принимать по
значениям оценок контрэксцесса
), положение которой укажет нам наиболее
предпочтительный закон распределения. В [1] решение предлагается принимать по
значениям оценок контрэксцесса ![]() и энтропийного
коэффициента
и энтропийного
коэффициента ![]() , где
, где 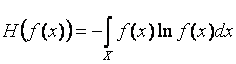 – дифференциальная энтропия величины
– дифференциальная энтропия величины ![]() . В этом случае получают точку в
плоскости (
. В этом случае получают точку в
плоскости (![]() ,
,![]() ), которая должна указать подходящий
закон.
), которая должна указать подходящий
закон.
Идеи привлекательны: получив точку в соответствующей плоскости, можно сразу указать вид закона (определить структуру модели). Однако работоспособность такого подхода на практике не выдерживает критики из-за плохой устойчивости оценок центральных моментов высоких порядков. Выборочные оценки таких моментов не являются робастными. Они очень чувствительны к незначительным отклонениям выборочных данных от предполагаемого закона, к наличию выбросов. Предлагаемая в [1] оценка энтропийного коэффициента
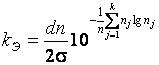 ,
(7)
,
(7)
где ![]() – длина интервала,
– длина интервала, ![]() – объем выборки,
– объем выборки, ![]() – число наблюдений в
– число наблюдений в ![]() -м интервале,
-м интервале, ![]() – число интервалов в
построенной по выборке гистограмме с равной длиной всех интервалов,
чувствительна не только к выбросам и отклонениям от предполагаемого закона, но
и к произвольно выбираемой длине интервала.
– число интервалов в
построенной по выборке гистограмме с равной длиной всех интервалов,
чувствительна не только к выбросам и отклонениям от предполагаемого закона, но
и к произвольно выбираемой длине интервала.
В топологических методах при объемах выборок, типичных для задач метрологии, степень неопределенности при идентификации закона оказывается очень высокой. Действенность подхода можно продемонстрировать только на идеализированных модельных данных.
Сравнительный анализ подходов. Безусловно, классический подход базируется на более основательном математическом аппарате, включающем методы статистического анализа, учитывающие специфику решаемых задач и вид законов, входящих в рассматриваемое множество моделей. При таком подходе и корректном использовании методов статистического анализа выводы о наиболее подходящем законе распределения всегда будут более обоснованы, чем при топологическом.
Топологический подход можно рекомендовать лишь как способ, позволяющий в первом приближении очертить некоторую группу моделей законов распределения, пригодную для описания наблюдаемой случайной величины.
Если при идентификации оперировать терминами ошибок первого и второго рода, мощностью критериев проверки гипотез, то, конечно, в случае классического подхода мы имеем дело с более мощными критериями. Однако нельзя утверждать, что в любом случае процедура идентификации (1)-(4) является наилучшей.
Хотя критерии согласия
при проверке сложных гипотез (1), как правило, мощнее, чем при проверке простых,
они не являются наиболее мощными критериями, ориентированными на проверку
гипотез о согласии с конкретным законом. То есть, для проверки
гипотез вида (1) для конкретного закона ![]() можно построить критерий,
ориентированный на этот закон, более мощный, чем критерий согласия. Например,
как показали наши исследования, критерии нормальности Шапиро-Уилка
и Эппса-Палли [20] при объемах выборок от 10 до 100
мощнее (относительно близких альтернатив) непараметрических критериев
согласия и критериев типа
можно построить критерий,
ориентированный на этот закон, более мощный, чем критерий согласия. Например,
как показали наши исследования, критерии нормальности Шапиро-Уилка
и Эппса-Палли [20] при объемах выборок от 10 до 100
мощнее (относительно близких альтернатив) непараметрических критериев
согласия и критериев типа ![]() , используемых для проверки гипотез о согласии с нормальным
законом.
, используемых для проверки гипотез о согласии с нормальным
законом.
Примечание: Следует отметить, что критерии нормальности Шапиро-Уилка и Эппса-Палли имеют и недостатки: при малых объемах выборок они не способны отличать от нормального закона распределения экспоненциального семейства, более плосковершинные по сравнению с нормальным законом. Наши исследования показали, что из-за повышенных вероятностей ошибок первого рода нецелесообразно применение включенного в стандарт [20] модифицированного критерия Шапиро-Уилка. Кроме того, в данный стандарт оказался не включенным наиболее мощный из известных критерий нормальности.
Состояние исследований. Остановимся на некоторых недостатках в подходе к задаче идентификации законов распределений, которые, на наш взгляд, прослеживаются в работах, связанных с вероятностным описанием погрешностей измерений.
Первое, что, по-видимому, следует отметить, это “историческая” ограниченность множества моделей, используемых для описания законов распределения ошибок измерений, и искусственность многих применяемых моделей (треугольное, трапецеидальное и т.п. распределения) [1, 21]. В реальных задачах неоправданно редко в качестве моделей используется экспоненциальное семейство распределений с плотностью
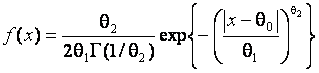 ,
(7)
,
(7)
редко рассматривают модели в виде смесей законов.
Во-вторых, определенная тяга к формализации процесса идентификации законов распределения [1, 19, 22], причем в некотором отрыве от современного аппарата математической статистики. Примеры попыток такой формализации можно назвать, скорее, намерениями, а не реальными попытками.
В-третьих, можно отметить недостаточную нацеленность при решении задач идентификации на использование развитого программного обеспечения задач статистического анализа или на его разработку. Практически не используются при исследовании вероятностных закономерностей возможности компьютерного моделирования, а если используются, то ошибки применения аппарата математической статистики при моделировании сводят на нет результаты исследований.
Например, ряд ошибок, связанных с вопросами применения критериев согласия, содержится в работе [21], где делается попытка сравнительного исследования ряда рассматриваемых критериев согласия при ограниченных объемах выборок. В частности, исследуется способность критериев отличить друг от друга четыре закона: нормальный, треугольный, трапецеидальный и равномерный. Отметим, что это существенно отличающиеся законы распределения и при больших объемах выборок нет проблемы их распознавания. Вполне естественно в целях исследования свойств критериев применение статистического моделирования, хотя не в таком урезанном виде, как в [21]. Принципиальная ошибка всего исследования, проведенного в [21], заключается в том, что выбор в пользу одной из четырех рассматриваемых гипотез осуществлялся по значениям статистики соответствующего критерия. Это было бы справедливо, если бы проверялись простые гипотезы. Но в данном случае речь шла о проверке сложных гипотез: параметры законов оценивались по тем же самым смоделированным выборкам. В такой ситуации распределения статистик всех рассматриваемых непараметрических критериев согласия зависят от вида закона, с которым проверяется согласие, от того, какие параметры оцениваются, и от метода оценивания параметров [10]. Это означает, что при одном и том же уровне значимости критические области одного и того же критерия при проверке согласия эмпирического распределения с различными теоретическими законами не совпадают. И не совпадают очень существенно. Поэтому результаты моделирования, представленные в [21], являются некорректными.
Необходимо также отметить, что статистики, названные в [21, стр. 6] статистиками критериев Мизеса и Пирсона “сложного”, в том виде, как они приведены в [21], вообще не являются статистиками критериев согласия, так как в них не задается расстояния между теоретическим и эмпирическим распределениями.
Еще одно недоразумение в
[21] связано с предложенной “модификацией” критерия ![]() . В результате такой модификации
статистика измеряет расстояние не между эмпирическим и теоретическим законом,
соответствующим проверяемой нулевой гипотезе, а между построенной ядерной
оценкой плотности и теоретическим законом с параметрами, оцененными по данной
выборке. То есть, измеряется расстояние между двумя различными оценками закона
распределения. В этом случае малое значение статистики критерия будет говорить
о близости оценок друг другу, а не о близости их эмпирическому закону
распределения. Но именно в проверке такой близости заключается цель применения
критерия согласия.
. В результате такой модификации
статистика измеряет расстояние не между эмпирическим и теоретическим законом,
соответствующим проверяемой нулевой гипотезе, а между построенной ядерной
оценкой плотности и теоретическим законом с параметрами, оцененными по данной
выборке. То есть, измеряется расстояние между двумя различными оценками закона
распределения. В этом случае малое значение статистики критерия будет говорить
о близости оценок друг другу, а не о близости их эмпирическому закону
распределения. Но именно в проверке такой близости заключается цель применения
критерия согласия.
Заключение.
Решение задач структурно-параметрической идентификации при ограниченных объемах выборок, которыми, как правило, обладают метрологи, обостряет проблему. В этом случае еще более важными оказываются корректность применения статистических методов анализа, использование оценок, обладающих наилучшими статистическими свойствами, и критериев, обладающих наибольшей мощностью.
При решении задач идентификации предпочтительнее опираться на классический подход. При идентификации рекомендуется рассматривать более широкое множество законов распределения, в том числе модели в виде смесей законов. В этом случае для любого эмпирического распределения мы всегда сможем построить адекватную, статистически существенно более обоснованную математическую модель.
Следует ориентироваться на использование и разработку программных систем, обеспечивающих решение задач структурно-параметрической идентификации законов распределений при любой форме регистрируемых наблюдений (измерений), включающих современные методы статистического анализа, ориентироваться на широкое, но корректное использование в исследованиях методов компьютерного моделирования.
ЛИТЕРАТУРА
1. Новицкий П.В., Зограф И.А. Оценка погрешностей результатов измерений. – Л.: Энергоатомиздат, 1991. – 303 с.
2. Лемешко Б.Ю., Чимитова Е.В. Об ошибках
и неверных действиях, совершаемых при использовании критериев согласия типа ![]() // Измерительная техника. 2002. – №
6. – С. 5-11.
// Измерительная техника. 2002. – №
6. – С. 5-11.
3. Лемешко Б.Ю. Об ошибках, совершаемых при использовании непараметрических критериев согласия // Измерительная техника. 2004. – №2. – С. 15-20.
4. Лемешко Б.Ю. Статистический анализ одномерных наблюдений случайных величин: Программная система. – Новосибирск: Изд-во НГТУ, 1995. – 125 с.
5. Лабутин С.А., Пугин М.В. Статистические модели и методы в измерительных задачах. – Н. Новгород: НГТУ, 2000. – 115 с.
6. Лемешко Б.Ю., Постовалов С.Н. Статистический анализ смесей распределений по частично группированным данным // Сб. научных трудов НГТУ. – Новосибирск: Изд-во НГТУ, 1995. – № 1. – С. 25-31.
7. Лемешко Б.Ю., Постовалов С.Н. Программное обеспечение статистического анализа смесей случайных величин, представленных частично группированными и интервальными выборками // Тр. третьей МНТК "Актуальные проблемы электронного приборостроения АПЭП-96". – Новосибирск, 1996. – Т. 6. – Ч.1. – С.50-53.
8. Лемешко Б.Ю., Постовалов С.Н. Система статистического анализа наблюдений и исследования статистических закономерностей // Сб. "Моделирование, автоматизация и оптимизация наукоемких технологий". – Новосибирск: изд-во НГТУ, 2000. – С. 44-46.
9. Лабутин С.А., Алешкин А.Н. Аппроксимация двухмодальных распределений случайных величин // Измерительная техника. 2002. – № 3. – С. 10-14.
10. Р 50.1.037-2002. Рекомендации по стандартизации. Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть II. Непараметрические критерии. – М.: Изд-во стандартов. 2002. – 64 с.
11. Р 50.1.033-2001. Рекомендации по стандартизации.
Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть I. Критерии типа хи-квадрат.
– М.: Изд-во стандартов. 2002. – 87 с.
12. Rao
C.R. Criteria of estimation in large samples // Sankhua,
1962. – V. 25. – P. 189-206.
13. Лемешко Б.Ю. Группирование наблюдений как способ получения робастных оценок // Надежность и контроль качества. – 1997. – № 5. – С. 26-35.
14. Лемешко Б.Ю. Робастные методы оценивания и отбраковка аномальных измерений // Заводская лаборатория. – 1997. – Т.63. – № 5. – С. 43-49.
15. Лемешко Б.Ю., Чимитова Е.В. Построение оптимальных L-оценок параметров сдвига и масштаба распределений по выборочным квантилям // Сибирский журнал индустриальной математики. 2001. – Т.4. – № 2. – С. 166-183.
16. Лемешко Б.Ю., Чимитова Е.В. Оптимальные L-оценки параметров сдвига и масштаба распределений по выборочным квантилям // Заводская лаборатория. Диагностика материалов. 2004. – Т.70. – №1. – С. 54-66.
17. Шуленин В.П. Введение в робастную статистику. – Томск: Изд-во Том. ун-та, 1993. – 227 с.
18. Wolfowitz J. The minimum distance method // Ann. Math. Stat., 1957. V. 28. – P. 75-88.
19. Яшин А.В., Лотонов М.А. Выбор метода решения задачи идентификации законов распределения случайных погрешностей средств измерений // Измерительная техника. 2003. – № 3. – С. 3-5.
20. ГОСТ Р ИСО 5479-2002. Статистические методы. Проверка отклонения распределения вероятностей от нормального распределения. – М.: Изд-во стандартов. 2002. – 30 с.
21. Яшин А.В., Храпов Ф.И. Выбор критерия согласия для определения закона распределения измеряемой величины // Измерительная техника. 2002. – № 1. – С. 16-20.
22. Яшин А.В. Определение закона распределения случайных погрешностей вторичных эталонов // Измерительная техника. 2003. – № 1. – С. 10-12.