3. РОБАСТНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЙ
3.1. Способы вычисления робастных оценок
3.2. Группирование наблюдений как способ получения робастных оценок
3.3. Функции влияния и робастность оценок
См. также: Прикладная
математическая статистика (материалы к семинарам)
3. РОБАСТНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЙ
3.1. Способы вычисления робастных оценок
В статистике под робастностью понимают нечувствительность к малым отклонениям от предположений [178]. Естественно, что при условии сохранения хороших качеств оценок лучше всего использовать робастные методы оценивания.
В выборке могут присутствовать отклонения от предположений двух видов. Допустим,
что наблюдаемая выборка действительно принадлежит тому закону распределения,
оценки которого мы пытаемся найти. В этом случае отклонения могут быть связаны
с наличием аномальных наблюдений, появление которых в выборке определяется
самыми различными причинами, в том числе засорением значениями, принадлежащими
другому закону. Если не учитывать наличие аномальных наблюдений, попытки
оценивания параметров распределения могут привести к самым плачевным результатам.
Что же делать? Естественно, надо отбраковать аномальные измерения, а затем
искать оценки параметров. К сожалению, реализовать отбраковку наблюдений в
общем случае оказывается совсем не просто. Наблюдения, аномальные с позиций
одного закона распределения, являются естественным проявлением закономерностей
второго. Если нет надежной процедуры отбраковки или практических соображений,
связанных с физикой наблюдаемой величины, пытаются выйти из положения одним
из следующих способов. В первом случае усекают выборку, отбрасывая
определенную часть минимальных и/или максимальных наблюдений, и по оставшейся
части оценивают параметры распределения, то есть используют так называемые ![]() -урезанные оценки (отбрасывается
-урезанные оценки (отбрасывается ![]() наименьших и
наименьших и ![]() наибольших
значений выборки [184]). Во втором - перед процедурой оценивания винзорируют выборку [178]: всем наблюдениям левее
и/или правее определенных значений присваивают одинаковые значения. Эти два
подхода используются при обработке наблюдений ещё с XIX века и связаны с
именами Пуанкаре [51] и Винзора [272]. Обе эти
процедуры далеко не всегда приводят к положительным результатам. Кроме того, в
обоих случаях мы имеем дело с новой генеральной совокупностью, которой
принадлежит видоизмененная выборка. Более правильным следует считать третий
подход, когда выборку цензурируют. Для наблюдений, попавших левее и/или правее
определенных значений, фиксируют лишь факт попадания в соответствующий
интервал, опуская конкретные значения этих наблюдений. По такой цензурированной
выборке оценивают параметры закона.
наибольших
значений выборки [184]). Во втором - перед процедурой оценивания винзорируют выборку [178]: всем наблюдениям левее
и/или правее определенных значений присваивают одинаковые значения. Эти два
подхода используются при обработке наблюдений ещё с XIX века и связаны с
именами Пуанкаре [51] и Винзора [272]. Обе эти
процедуры далеко не всегда приводят к положительным результатам. Кроме того, в
обоих случаях мы имеем дело с новой генеральной совокупностью, которой
принадлежит видоизмененная выборка. Более правильным следует считать третий
подход, когда выборку цензурируют. Для наблюдений, попавших левее и/или правее
определенных значений, фиксируют лишь факт попадания в соответствующий
интервал, опуская конкретные значения этих наблюдений. По такой цензурированной
выборке оценивают параметры закона.
Другая ситуация. В выборке нет аномальных наблюдений, но наблюдаемый закон распределения отличается от предполагаемого. Такая ситуация присутствует практически всегда, так как множество законов распределения вероятностей бесконечно, а количество моделей, используемых на практике для описания наблюдаемых случайных величин, очень ограничено. Чем существенней вид предполагаемой модели отличается от реально наблюдаемого закона, тем сильнее это отражается на оценках параметров.
Очевидно, что в наблюдаемых на практике выборках и закон, пусть мало, но отличается от используемой модели, и обычно налицо аномальные наблюдения. Поэтому применение цензурирования, односторонннего или двустороннего, далеко не всегда приносит желаемый эффект.
Вопросам построения и исследования робастных оценок посвящено очень много работ (см., например [178,147]). В данном случае не преследовалась цель анализа всей совокупности подходов и методов построения робастных методов оценивания. Анализируются только свойства робастности оценок максимального правдоподобия по группированным и негруппированным наблюдениям.
3.2. Группирование наблюдений как способ получения робастных
оценок
В работах [76,81,85] подчеркивается высокая устойчивость оценок максимального правдоподобия по группированным наблюдениям к наличию в выборке аномальных измерений, к отклонению реально наблюдаемого закона от предполагаемого, к засорению выборки данными, принадлежащими другому закону. Это подтверждается опытом эксплуатации программной системы [76] и многочисленными результатами модельных экспериментов.
Метод максимального правдоподобия является одним из наиболее популярных и эффективных методов оценивания параметров распределений. Достаточно часто приходится сталкиваться с необоснованными утверждениями, что оценки максимального правдоподобия являются робастными и, именно поэтому, предпочтительно использовать именно их. Автор является сторонником широкого использования метода максимального правдоподобия, но вместе с тем, основываясь на достаточно большом практическом опыте и результатах этого и следующего параграфа, обязан подчеркнуть, возможно очевидное для многих, что в общем случае ОМП параметров распределений не являются робастными.
Проиллюстрируем сказанное следующими примерами. Это можно было бы сделать с одинаковым эффектом на различных законах распределения, но, учитывая роль нормального распределения в теории и приложениях математической статистики, приведем примеры именно с нормальным законом. В первом примере иллюстрируется влияние аномальных ошибок на ОМП параметров нормального распределения, а во втором параметры нормального закона оцениваются по выборке, принадлежащей другому закону распределения. Для чистоты эксперимента выборки моделируются в соответствии с заданными законами.
Пример
3.2.1. Выборка по нормальному
закону моделировалась с математическим ожиданием ![]() и среднеквадратическим отклонением
и среднеквадратическим отклонением ![]() . На рис. 3.2.1 приведены результаты статистического
анализа смоделированной выборки. Вычисленные значения ОМП
. На рис. 3.2.1 приведены результаты статистического
анализа смоделированной выборки. Вычисленные значения ОМП ![]() и
и ![]() . На
этом и последующем аналогичных рисунках приведены значения статистик отношения
правдоподобия,
. На
этом и последующем аналогичных рисунках приведены значения статистик отношения
правдоподобия, ![]() Пирсона, Колмогорова, Смирнова,
Пирсона, Колмогорова, Смирнова, ![]() и
и ![]() Мизеса, вычисляемые при проверке гипотез о согласии, и соответствующие
вероятности вида
Мизеса, вычисляемые при проверке гипотез о согласии, и соответствующие
вероятности вида 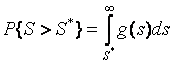 , где
, где ![]() -
вычисленное значение соответствующей статистики,
-
вычисленное значение соответствующей статистики, ![]() - предельное распределение вероятностей для
статистики. Гипотеза о согласии не отвергается, если
- предельное распределение вероятностей для
статистики. Гипотеза о согласии не отвергается, если ![]() , где
, где ![]() -
заданный уровень значимости. Для статистик отношения правдоподобия и
-
заданный уровень значимости. Для статистик отношения правдоподобия и ![]() Пирсона значения вероятностей приводятся при
двух различных степенях свободы. Разность степеней свободы определяется
количеством параметров, оцененных по выборке. При вычислении вероятностей вида
Пирсона значения вероятностей приводятся при
двух различных степенях свободы. Разность степеней свободы определяется
количеством параметров, оцененных по выборке. При вычислении вероятностей вида
![]() для непараметрических критериев типа
Колмогорова, Смирнова,
для непараметрических критериев типа
Колмогорова, Смирнова, ![]() и
и
![]() Мизеса учитывается
факт потери ими свойства “свободы от распределения” [97]. Как видим, согласие
с нормальным законом очень хорошее.
Мизеса учитывается
факт потери ими свойства “свободы от распределения” [97]. Как видим, согласие
с нормальным законом очень хорошее.
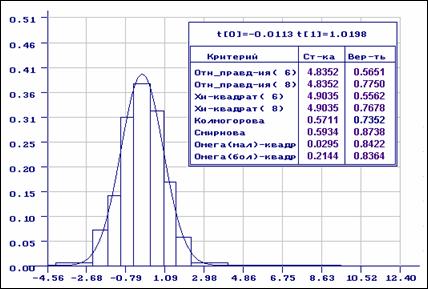
Рис.3.2.1. Результаты статистического анализа исходной выборки по негруппированным данным
Теперь допустим, что в выборку “вкралось” всего 3 аномальных наблюдения (в
результате замены трех первых наблюдений: ![]() на
на ![]() ,
, ![]() на
на ![]() ,
, ![]() на
на ![]() ).
Результаты анализа с теоретической и эмпиричекой функциями распределения приведены на рис.
3.2.2. Полученные ОМП параметров нормального распределения
).
Результаты анализа с теоретической и эмпиричекой функциями распределения приведены на рис.
3.2.2. Полученные ОМП параметров нормального распределения ![]() и
и ![]() .
Особенно существенно наличие аномальных наблюдений повлияло на оценку
среднеквадратичного отклонения. По всем критериям согласие с нормальным законом
распределения будет отклонено при уровене значимости
.
Особенно существенно наличие аномальных наблюдений повлияло на оценку
среднеквадратичного отклонения. По всем критериям согласие с нормальным законом
распределения будет отклонено при уровене значимости ![]() > 0.0008.
> 0.0008.
Пример
3.2.2. Этот пример связан с
использованием нормального закона распределения в ситуации, когда на самом деле
выборка принадлежит распределению Лапласа. Распределение Лапласа с более “тяжелыми”
хвостами, чем у нормального. На
рис. 3.3.3 приведены эмпирическая и теоретические функции нормального
распределения, когда по выборке, смоделированной в соответствии с
распределением Лапласа, оценивались параметры нормального закона (![]() ). Как видно из значений статистик и
соответствующих вероятностей, ни о какой близости эмпирической и теоретической
функций распределения говорить не приходится.
). Как видно из значений статистик и
соответствующих вероятностей, ни о какой близости эмпирической и теоретической
функций распределения говорить не приходится.
Естественно, что использование получившихся в этих 2-х примерах нормальных законов в качестве моделей наблюдаемых выборок ни к чему хорошему не приведет.
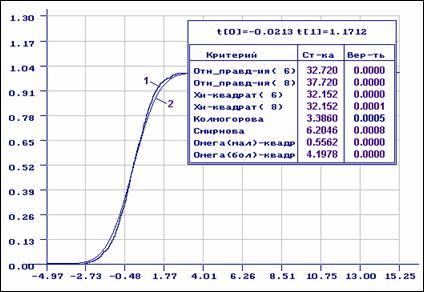
Рис.3.2.2. Эмпирическая функция распределения (1) и теоретическая
функция нормального распределения (2), полученная по выборке с аномальными наблюдениями
Что же можно сделать, чтобы снизить влияние аномальных ошибок и отклонений наблюдаемых выборок от предполагаемого закона на оценки вычисляемых параметров? Мы настоятельно рекомендуем использовать перед вычислением оценок параметров процедуру предварительного группирования наблюдений. Группирование выборки позволяет резко снизить влияние аномальных наблюдений, а иногда практически исключить последствия присутствия их в выборке. Резко снижается влияние на оценки параметров и отклонений вида наблюдаемого закона от предполагаемого. Продемонстрируем это на выборках приведенных примеров.
На рис. 3.2.4 представлены результаты оценивания параметров нормального
распределения и последующего анализа по сгруппированной выборке из примера
3.2.1, содержащей 3 аномальных наблюдения (сравните значения статистик и
соответствующих вероятностей с представленными на рис.
3.2.2). Полученные ОМП параметров нормального распределения по группированным
данным ![]() и
и ![]() .
Визуального различия между эмпирической и теоретической функцией нормального
закона в данном случае нет, поэтому соответствующие графики не приводятся.
.
Визуального различия между эмпирической и теоретической функцией нормального
закона в данном случае нет, поэтому соответствующие графики не приводятся.
На рис. 3.2.5 представлены результаты оценивания по сгруппированным данным
параметров нормального закона по выборке из примера 3.2.2, принадлежащей
распределению Лапласа (сравните результаты анализа с результатами,
представленными на рис. 3.2.3). ОМП параметров нормального распределения по
группированным данным ![]() и
и
![]() . В данном случае в центре области определения
случайной величины наблюдается некоторая близость эмпирической функции распределения
и функции распределения нормального закона.
. В данном случае в центре области определения
случайной величины наблюдается некоторая близость эмпирической функции распределения
и функции распределения нормального закона.
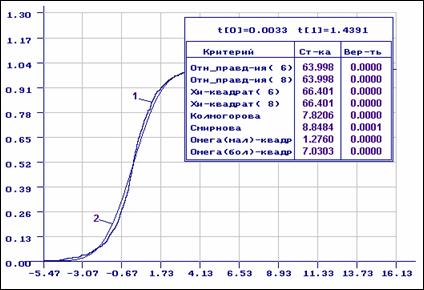
Рис.3.2.3. Эмпирическая функция распределения (1) и функция
распределения нормального закона (2), найденного по выборке,
принадлежащей распределению Лапласа

Рис. 3.2.4. Результаты оценивания по сгруппированной выборке и последующего статистического анализа при наличии в выборке аномальных измерений
Пример 3.2.3. Выборка объёмом 1000 наблюдений была смоделирована в соответствии с распределением Вейбулла с плотностью
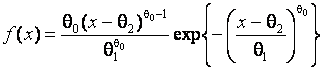 .
.
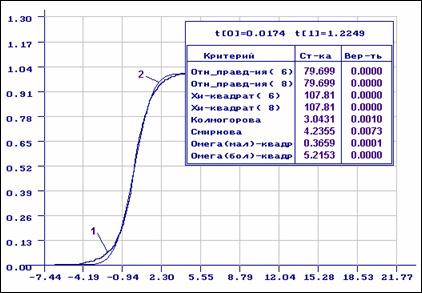
Рис. 3.2.5. Эмпирическая функция, построенная по выборке, принадлежащей распределению Лапласа (1), и теоретическая функция нормального закона (2), найденная по сгруппированной выборке
При
моделировании были заданы параметры: ![]() В
процессе регистрации 8 наблюдений “подверглись” сильным искажениям.
В
процессе регистрации 8 наблюдений “подверглись” сильным искажениям.
На рис. 3.2.6-3.2.7 приведены результаты статистического анализа полученной
выборки. В данном случае получили закон распределения Вейбулла
с параметрами ![]() Как
видим из рис. 3.2.6, согласие по всем критериям отвергается: наличие
аномальных наблюдений сыграло свою роль. На рис. 3.2.7 хорошо заметна разница
между эмпирической и теоретической функциями распределения.
Как
видим из рис. 3.2.6, согласие по всем критериям отвергается: наличие
аномальных наблюдений сыграло свою роль. На рис. 3.2.7 хорошо заметна разница
между эмпирической и теоретической функциями распределения.
На рис. 3.2.8 приведены результаты статистического анализа,
когда перед оцениванием выборка была разбита на интервалы равной частоты, затем
по получившейся группированной выборке были найдены оценки параметров
распределения ![]() , после чего проверены гипотезы о согласии исходной
выборки с полученным законом распределения. При проверке гипотез о согласии исходная выборка разбивалась
на интервалы равной вероятности. Как видим, результаты проверки гипотез о
согласии по всем критериям очень хорошие.
, после чего проверены гипотезы о согласии исходной
выборки с полученным законом распределения. При проверке гипотез о согласии исходная выборка разбивалась
на интервалы равной вероятности. Как видим, результаты проверки гипотез о
согласии по всем критериям очень хорошие.
Отличие результатов на рис. 3.2.9 определяется тем, что при проверке гипотез о
согласии исходная выборка разбивалась на интервалы в соответствии с
асимптотически оптимальным группированием. В данном случае критерии отношения
правдоподобия и ![]() Пирсона оказываются более чувствительными, чем
остальные: улавливают наличие аномальных измерений. Гипотезы о согласии при
Пирсона оказываются более чувствительными, чем
остальные: улавливают наличие аномальных измерений. Гипотезы о согласии при ![]() по
этим критериям должны быть отвергнуты.
по
этим критериям должны быть отвергнуты.
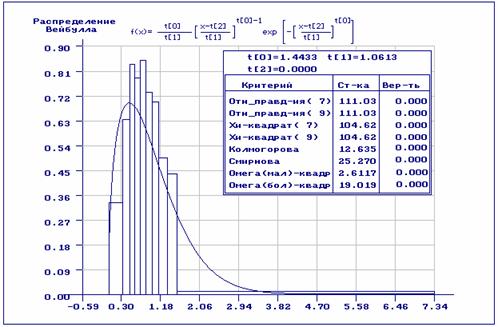
Рис. 3.2.6. Результаты статистического анализа исходной выборки по негруппированным данным
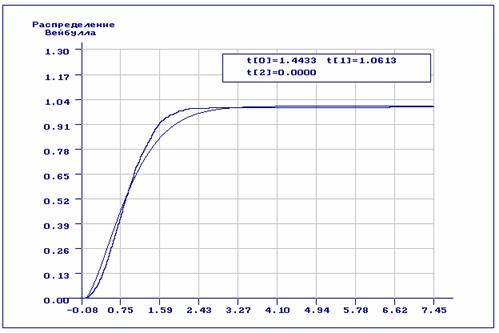
Рис. 3.2.7. Теоретическая и эмпирическая функции распределения
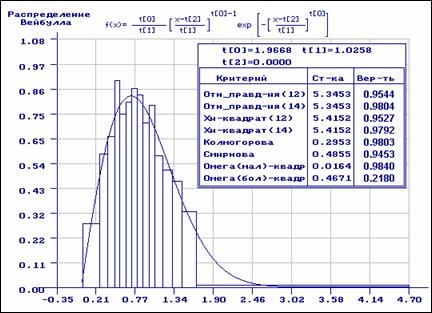
Рис. 3.2.8. Оценивание с предварительным равночастотным группированием и проверкой гипотез о согласии с разбиением на равночастотные интервалы.
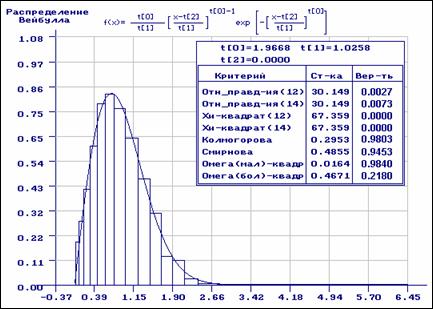
Рис. 3.2.9. Оценивание с предварительным равночастотным группированием и проверкой гипотез о согласии с разбиением на асимптотически оптимальные интервалы
Приведенные на рис. 3.2.10-3.2.11 результаты анализа, аналогичны тем, что
представлены на рис. 3.2.8-3.2.9, но перед оцениванием выборка была разбита на
асимптотически оптимальные интервалы. Получены оценки параметров ![]() . Если при проверке гипотез исходная выборка
разбивалась на интервалы равной вероятности (рис. 3.2.10), то гипотеза о
согласии по всем критериям принимается. При использовании асимптотически
оптимального группирования гипотеза о согласии по критериям отношения
правдоподобия и
. Если при проверке гипотез исходная выборка
разбивалась на интервалы равной вероятности (рис. 3.2.10), то гипотеза о
согласии по всем критериям принимается. При использовании асимптотически
оптимального группирования гипотеза о согласии по критериям отношения
правдоподобия и ![]() Пирсона должна быть отвергнута (рис. 3.2.11).
Если мы сравним эти результаты, с результатами, представленными на рис.
3.2.8-3.2.9, то увидим, что уровень согласия в данном случае ниже. То есть,
полученные оценки оказались хуже, а способ их определения более
чувствителен к аномальным наблюдениям.
Пирсона должна быть отвергнута (рис. 3.2.11).
Если мы сравним эти результаты, с результатами, представленными на рис.
3.2.8-3.2.9, то увидим, что уровень согласия в данном случае ниже. То есть,
полученные оценки оказались хуже, а способ их определения более
чувствителен к аномальным наблюдениям.
Приведем ещё один пример, подчеркивающий устойчивость оценок максимального правдоподобия по группированным данным. Он связан с использованием нормального закона распределения в ситуации, когда на самом деле выборка принадлежит распределению Коши.
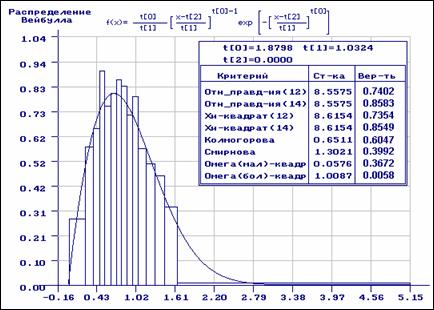
Рис. 3.2.10. Оценивание с предварительным асимптотически оптимальным группированием. При проверке согласия использованы равночастотные интервалы.
Пример
3.2.4. Распределение Коши это
распределение с “тяжелыми” хвостами, а такое отклонение от нормальности
особенно сильно отражается на оценках параметров нормального закона. На рис.
3.2.12-3.2.13 приведены эмпирическая и теоретические
функции нормального распределения при использовании обычных оценок максимального
правдоподобия (рис. 3.2.12, оценки параметров нормального распределения: ![]() ,
, ![]() ) и
оценок максимального правдоподобия по группированным данным (рис. 3.2.13,
оценки:
) и
оценок максимального правдоподобия по группированным данным (рис. 3.2.13,
оценки: ![]() ,
, ![]() ).
Качественная картина, хорошо прослеживаемая на графиках, говорит сама за
себя: во втором случае можно даже говорить об определенной близости эмпирической
и теоретической функций распределения. Выборка объёмом 100 наблюдений моделировалась
по закону Коши с функцией плотности
).
Качественная картина, хорошо прослеживаемая на графиках, говорит сама за
себя: во втором случае можно даже говорить об определенной близости эмпирической
и теоретической функций распределения. Выборка объёмом 100 наблюдений моделировалась
по закону Коши с функцией плотности 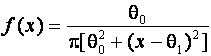 и
параметрами
и
параметрами ![]() ,
, ![]() .
.
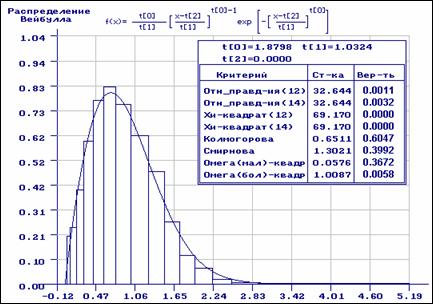
Рис. 3.2.11. Оценивание с предварительным группированием с разбиением на асимптотически оптимальные интервалы. При проверке согласия также использовано асимптотически оптимальное группирование.
Подведем итоги вышесказанному. Группирование наблюдений перед оцениванием и последующее оценивание параметров по группированной выборке позволяет получать устойчивые оценки. Когда мы говорим об оценках по группированным данным, то имеем ввиду ОМП, которые определяются в результате максимизации функции правдоподобия вида
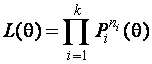 ,
,
где
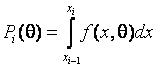 - вероятность попадания наблюдения в
- вероятность попадания наблюдения в ![]() -й интервал
значений, k - число интервалов, но только не
оценки по методу моментов с последующим использованием поправок типа Шеппарда.
-й интервал
значений, k - число интервалов, но только не
оценки по методу моментов с последующим использованием поправок типа Шеппарда.
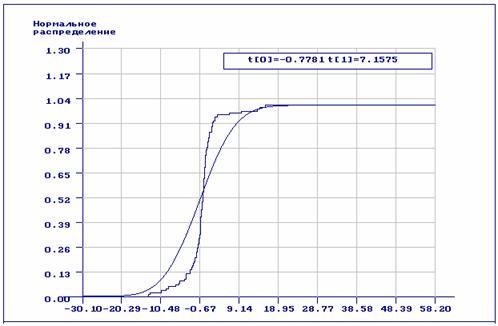
Рис. 3.2.12. Эмпирическая функция распределения и теоретическая
функция нормального закона распределения, найденная по выборке, принадлежащей распределению Коши.
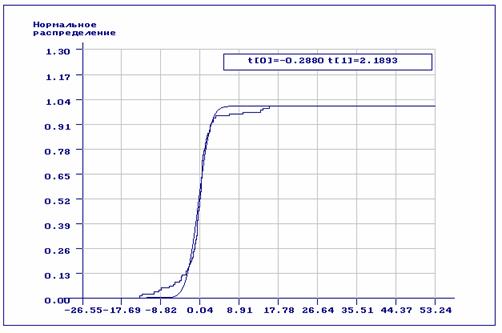
Рис. 3.2.13. Эмпирическая функция распределения и теоретическая функция нормального закона распределения, найденная по сгруппированной выборке, принадлежащей распределению Коши.
Естественно, мы предлагаем использовать оценки по группированным данным не вместо, а вместе с оценками по негруппированным наблюдениям. Качество тех и других зависит от степени засоренности выборки аномальными наблюдениями или близости к предполагаемому закону распределения.
Остаётся вопрос, как группировать? Можно различным образом. Не стоит, конечно, рассматривать крайние случаи: сгруппировать можно и так, что в группированной выборке не останется никакой информации о законе и его параметрах. Реально на интервалы разбивают область, определяемую размахом выборки. Это могут быть или интервалы равной длины, или интервалы равной вероятности (равной частоты), или асимптотически оптимальные интервалы, или интервалы, сформированные по какому-то другому принципу. Обычно наиболее устойчивыми к отклонениям оказываются оценки при разбиении выборки на интервалы равной вероятности. В то же время в случае асимптотически оптимального группирования потери информации о параметрах закона распределения, связанные с группированием, существенно меньше, чем при равновероятном. Если мы знаем, что отклонения от наших предположений в выборке минимальны, то использование полученных таблиц асимптотически оптимального группирования позволяет резко сократить объемы хранимых данных без существенной потери информации о законе распределения. Но всё-таки в общем случае здесь следует ожидать большей чувствительности оценок к отклонениям от предположений.
С другой стороны, достаточно часто мешающая информация, связанная с засорением выборки, оказывает меньшее влияние на оценки, чем потери информации от группирования при асимптотически оптимальном группировании. В некоторых случаях оценки с использованием асимптотически оптимального группирования оказываются так же устойчивыми, как и при равновероятном, и при этом показывают лучшие результаты. Поэтому рекомендуется вычислять две оценки по группированным данным с использованием как оптимального, так и равновероятного группирования, и остановиться на той оценке, которая дает лучшее согласие с исходной выборкой.
Группирование наблюдений приводит к потере в количестве информации Фишера о параметре (параметрах) распределения. При асимптотически оптимальном группировании, как показывают таблицы асимптотически оптимального группирования, эти потери составляют в среднем порядка 2% при оценивании одного параметра и 10-11 интервалах группирования и порядка 5% при оценивании двух параметров и 15 интервалах группирования [42]. Это вызывает соответствующий рост асимптотической дисперсии эффективных оценок. В то же время, так как ОМП по негруппированным наблюдениям (и многие другие оценки) в общем случае чрезвычайно чувствительны к наличию аномальных наблюдений или отклонению наблюдаемой выборки от предполагаемого закона распределения, то дисперсия таких оценок может быть существенно больше асимптотической. Напротив ОМП по группированным данным являются устойчивыми к таким отклонениям в наблюдениях. Реально, при наличии в выборке неоднократно упоминаемых отклонений, дисперсия оценок по группированным данным оказывается меньше, чем по негруппированным. Т.е. вклад в дисперсию от потерь в асимптотике оказывается несоизмеримо мал по сравнению со вкладом, связанным с наличием отклонений.
Существенное различие в оценках, вычисляемых по негруппированным и сгруппированным данным, может служить сигналом о том, что между имеющимися данными и нашими предположениями (знаниями о виде закона распределения) имеются некоторые разногласия: либо налицо засорение выборки, либо в измерения вкрались ошибки, либо наши предположения о виде закона распределения (модели) неверны.
Выводы
1. Предварительное группирование исходной выборки и последующее вычисление ОМП по группированным данным приводит к робастным оценкам, устойчивым как к наличию в исходной выборке аномальных измерений, так и к отклонениям закона распределения выборки от предполагаемого.
2. Процедура предварительного группирования реализована в программном обеспечении. Возможно использование равномерного, равновероятного и асимптотически оптимального группирования. На основании исходной негруппированной выборки может создаваться соответствующая группированная выборка. Реализован режим предварительного группирования при оценивании, в том числе при идентификации закона распределения.
3. Высокая устойчивость к присутствию в выборке грубых искажений или принадлежности выборки к другому закону распределения оценок максимального правдоподобия по группированной выборке позволяет использовать их в процедурах отбраковки аномальных наблюдений.
3.3. Функции влияния и робастность оценок
В работах [76,81,85,100] и предыдущих разделах подчеркивается высокая устойчивость оценок максимального правдоподобия (ОМП) по группированным наблюдениям к наличию в выборке аномальных измерений, к отклонению реально наблюдаемого закона от предполагаемого, к засорению выборки данными, принадлежащими другому закону. Всё это подтверждается опытом эксплуатации программной системы [76] и многочисленными результатами модельных экспериментов. В данном разделе, основные результаты которого изложены в [93], свойство робастности ОМП исследуется с позиций функции влияния, предложенной Хэмпелом [221,222]. Именно анализ функций влияния ОМП параметров различных распределений, в том числе того множества распределений, которое включено в программную систему [76], позволяет утверждать, что ОМП по негруппированным данным, вопреки порой бытующему заблуждению, в большинстве своём являются неробастными. В то же время ОМП по группированным данным всегда оказываются робастными.
Влияние ещё одного наблюдения на очень большую выборку может характеризоваться функцией (кривой) влияния, которая определяется следующим образом [178]
![]() ,
,
где
![]() - единичная масса в точке
- единичная масса в точке ![]() ,
, ![]() -
функция распределения, к которому принадлежит выборка,
-
функция распределения, к которому принадлежит выборка, ![]() - вычисляемая статистика.
- вычисляемая статистика.
Функция влияния позволяет оценить относительное влияние отдельного наблюдения на значение статистики критерия или оценку параметров. Если функция влияния неограничена, то резко выделяющиеся наблюдения могут приводить к существенным изменениям оценок или статистик. Чувствительность к большой ошибке может характеризоваться величиной
![]() .
.
Для асимптотически эффективных оценок, к которым относятся оценки максимального правдоподобия по негруппированным данным, функция влияния удовлетворяет равенству [178]
![]() ,
(3.3.1)
,
(3.3.1)
где
![]() - количество информации Фишера.
- количество информации Фишера.
Для оценок типа максимального правдоподобия (М-оценок), где всякая
оценка ![]() определяется как решение экстремальной задачи на
минимум вида
определяется как решение экстремальной задачи на
минимум вида
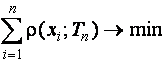
или как решение неявного уравнения
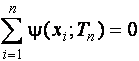 ,
,
где
![]() - произвольная функция,
- произвольная функция, ![]() , функция влияния имеет вид [184]
, функция влияния имеет вид [184]
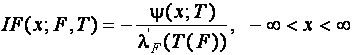 ,
,
где
![]() .
.
В случае ОМП по группированным данным
![]() ,
,
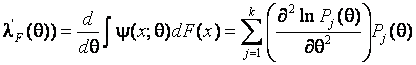
и функция влияния будет иметь вид
 . (3.3.2)
. (3.3.2)
Для оценок, использующих квантили, соответствующие асимптотически оптимальному группированию [88], и являющихся одним из частных случаев L-оценок, функция влияния имеет вид [184]
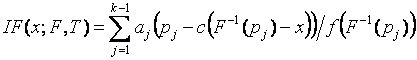 , (3.3.3)
, (3.3.3)
где
![]() - коэффициенты при выборочных квантилях в
формуле для вычисления L-оценок,
- коэффициенты при выборочных квантилях в
формуле для вычисления L-оценок, 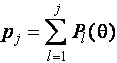 ,
, 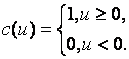
Были рассмотрены функции влияния для оценок параметров множества распределений, включенных в программную систему [76].
Приводимые ниже функции влияния построены при конкретных значениях параметров и характеризуют качественную картину их поведения на области определения случайных величин. На рис. 3.3.1-3.3.2 представлены функции влияния для оценок параметров сдвига и масштаба нормального распределения, определяемых методом максимального правдоподобия по негруппированным и сгруппированным данным. Функция влияния для ОМП параметра сдвига по негруппированным данным имеет вид
![]() ,
,
для ОМП параметра масштаба -
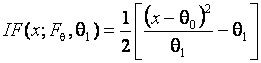 .
.
Функции влияния неограничены, и этим определяется чувствительность данных оценок к ошибкам измерения и засорению выборки. Напротив, функции влияния оценок параметров нормального распределения по группированным данным ограничены. Это ещё раз подчеркивает высокую устойчивость получаемых по группированным наблюдениям оценок, подтверждаемую практикой. На этих и последующих рисунках функции влияния для ОМП по группированным данным соответствуют случаю использования асимптотически оптимального группирования.
Аналогично, на рис. 3.3.3-3.3.4 приведены функции влияния для параметров распределения Вейбулла. Функция влияния для ОМП основного параметра по негруппированным данным имеет вид
![]() ,
,
где
![]() - постоянная Эйлера и
- постоянная Эйлера и  , для ОМП параметра масштаба -
, для ОМП параметра масштаба -
 .
.
Для основного параметра функция влияния по негруппированным данным неограничена снизу на левой и правой границе области определения случайной величины, для масштабного параметра - неограничена сверху на правой границе. В то же время для группированных наблюдений функции влияния являются ступенчатыми ограниченными функциями.
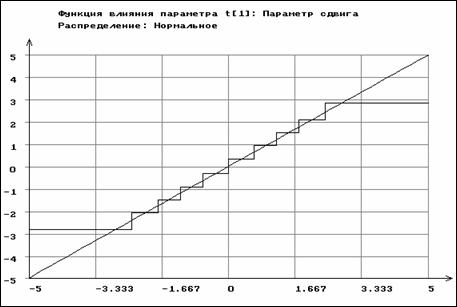
Рис. 3.3.1. Функции влияния для параметра сдвига
нормального распределения по негруппированным (прямая)
и сгруппированным данным (ступенчатая линия)
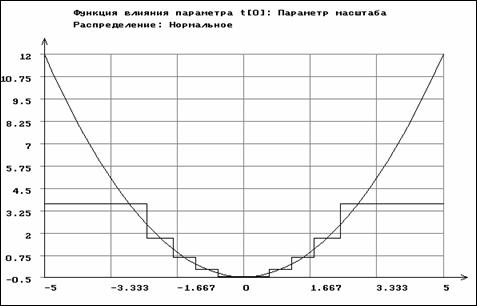
Рис. 3.3.2. Функции влияния для параметра масштаба
нормального распределения по негруппированным
и сгруппированным данным (ступенчатая линия)
Совершенно другую картину мы наблюдаем для ОМП по негруппированным наблюдениям для параметров распределения Коши (см. рис. 3.3.5-3.3.6). Функция влияния для ОМП параметра сдвига по негруппированным данным имеет вид
![]() ,
,
где
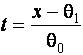 .
.
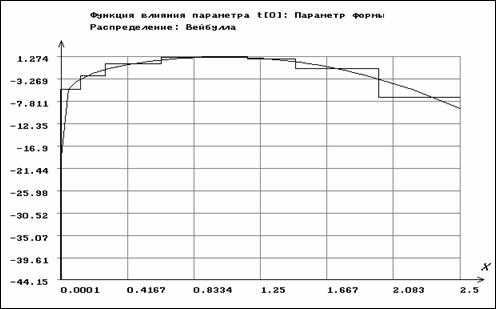
Рис. 3.3.3. Функции влияния для основного параметра
распределения Вейбулла по негруппированным
и сгруппированным данным (ступенчатая линия)
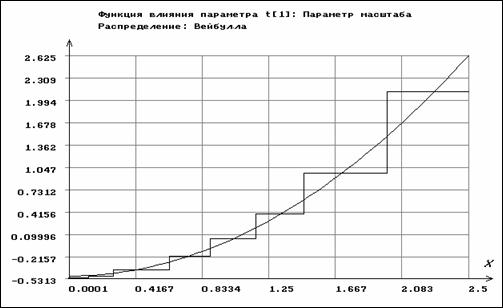
Рис. 3.3.4. Функции влияния для параметра масштаба распределения
Вейбулла по негруппированным и сгруппированным данным
Для ОМП параметра масштаба -
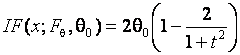 .
.
Их функции влияния ограничены на области определения случайной величины, что говорит о робастности этих оценок, их устойчивости к грубым ошибкам измерений.
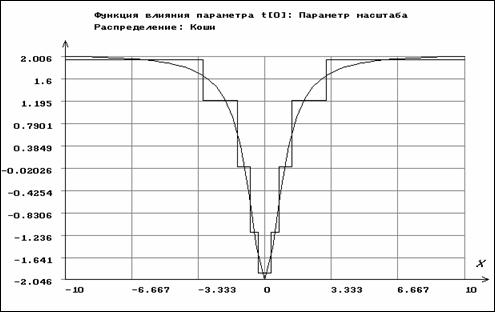
Рис. 3.3.5. Функции влияния для параметра масштаба
распределения Коши по негруппированным (непрерывная)
и сгруппированным данным (ступенчатая линия)
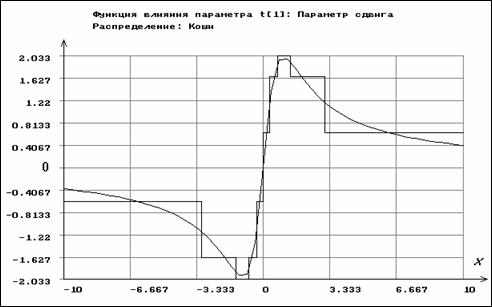
Рис. 3.3.6. Функции влияния для параметра сдвига распределения
Коши по негруппированным и сгруппированным данным
Для логистического распределения функция влияния ОМП параметра масштаба по негруппированным данным имеет вид
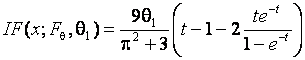 ,
,
где
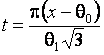 , (см. рис. 3.3.7). Из её
неограниченности следует, что соответствующая оценка неробастна.
В то же время функция влияния ОМП параметра сдвига
, (см. рис. 3.3.7). Из её
неограниченности следует, что соответствующая оценка неробастна.
В то же время функция влияния ОМП параметра сдвига
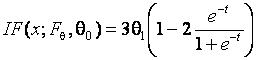
ограничена сверху и снизу, А это свидетельствует о робастности ОМП этого параметра.
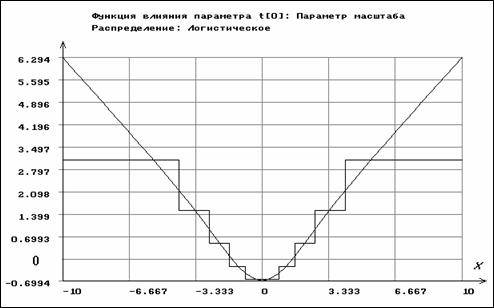
Рис. 3.3.7. Функции влияния для параметра масштаба
логистического распределения по негруппированным
и сгруппированным данным (ступенчатая линия)
Ситуация, которую мы наблюдаем для функций влияния ОМП по негруппированным наблюдениям параметров распределений Коши и логистического (параметр сдвига), оказывается явно нетипичной. Для ОМП параметров остальных законов распределения, включенных в программную систему [76], а в совокупности это 26 законов и семейств непрерывных распределений, функции влияния неограничены, откуда следует неробастность этих оценок. С другой стороны, фунции влияния для ОМП по группированным данным всегда представляют собой ограниченные ступенчатые зависимости, что свидетельствует о робастности этих оценок.
Функции влияния L-оценок с использованием оптимальных порядковых статистик, как следует из вида соотношения (3.3.3), также представляют собой ступенчатые ограниченные зависимости, что говорит о робастности этих оценок. Это же подтверждают и проведенные эксперименты по моделированию выборок, их засорению, оцениванию параметров и анализу.
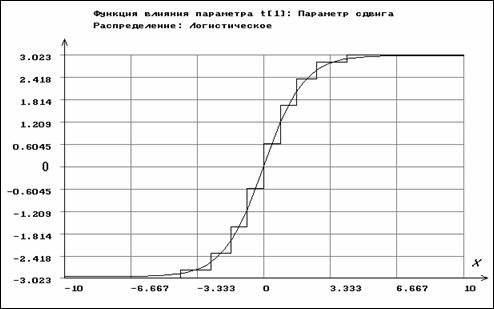
Рис. 3.3.8 Функции влияния для параметра масштаба
логистического распределения по негруппированным
и сгруппированным данным (ступенчатая линия)
Выводы
Таким образом, анализ функций влияния оценок по негруппированным и группированным выборкам ещё раз позволяет сделать следующие выводы.
1. За редким исключением ОМП по негруппированным наблюдениям являются неробастными.
2. Напротив, ОМП по группированным данным и оптимальные оценки параметров сдвига и масштаба по выборочным квантилям для больших выборок устойчивы как к аномальным ошибкам измерений, так и к отклонениям наблюдаемого закона от предполагаемого.
[Возврат к вопросам
]