яЛ. РЮЙФЕ: оПХЙКЮДМЮЪ
ЛЮРЕЛЮРХВЕЯЙЮЪ ЯРЮРХЯРХЙЮ (ЛЮРЕПХЮКШ Й ЯЕЛХМЮПЮЛ)
мЮДЕФМНЯРЭ Х ЙНМРПНКЭ ЙЮВЕЯРБЮ. - 1997. - ╧ 8. - я. 3-14.
сдй 519.2
юЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЕ ЦПСООХПНБЮМХЕ МЮАКЧДЕМХИ - ЩРН НАЕЯОЕВЕМХЕ ЛЮЙЯХЛЮКЭМНИ ЛНЫМНЯРХ ЙПХРЕПХЕБ ЯНЦКЮЯХЪ
кЕЛЕЬЙН а.ч
оНЙЮГШБЮЕРЯЪ, ВРН ЮЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЕ
ЦПСООХПНБЮМХЕ МЮАКЧДЕМХИ НАЕЯґОЕВХБЮЕР ОПХ АКХГЙХУ ЮКЭРЕПМЮРХБЮУ ЛЮЙЯХЛЮКЭМСЧ
ЛНЫМНЯРЭ ЙПХРЕПХЕБ ЯНЦКЮЯХЪ ![]() оХПЯНМЮ
Х НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ. хЯОНКЭГНБЮМХЕ ОНКСВЕММШУ РЮАКХЖ НОРХЛЮКЭМНЦН
ЦПСООХПНБЮМХЪ ЯНЙПЮЫЮЕР ПХЯЙ МЕНАНЯМНБЮММНЦН ОПХМЪРХЪ ЦХОНРЕГ Н ЯНЦКЮЯХХ.
оХПЯНМЮ
Х НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ. хЯОНКЭГНБЮМХЕ ОНКСВЕММШУ РЮАКХЖ НОРХЛЮКЭМНЦН
ЦПСООХПНБЮМХЪ ЯНЙПЮЫЮЕР ПХЯЙ МЕНАНЯМНБЮММНЦН ОПХМЪРХЪ ЦХОНРЕГ Н ЯНЦКЮЯХХ.
мХ ДКЪ ЙНЦН МЕ ЯЕЙПЕР, ВРН ПЕГСКЭРЮРШ ОПНБЕПЙХ ЦХОНРЕГ Н ЯНЦКЮЯХХ Б
ЯННРБЕРЯРБХХ Я ЙПХРЕПХЕЛ ![]() оХПЯНМЮ
ЯСЫЕЯРБЕММН ГЮБХЯЪР НР РНЦН, ЙЮЙ ЯЦПСООХПНБЮМШ ДЮММШЕ: ЯЦПСООХПНБЮКХ НДМХЛ
ЯОНЯНАНЛ, ЦХОНРЕГС Н ЯНґЦКЮґЯХХ ЛНФМН ОПХМЪРЭ, ЯЦПСООХПНБЮКХ ДПСЦХЛ - ЦХОНРЕГЮ
Н ЯНЦКЮЯХХ ДНКФМЮ АШРЭ НРБЕПЦМСРЮ. нРЙСДЮ ФЕ БГЪРЭ СБЕПЕММНЯРЭ Б РЮЙНЛ БШБНДЕ?
оХПЯНМЮ
ЯСЫЕЯРБЕММН ГЮБХЯЪР НР РНЦН, ЙЮЙ ЯЦПСООХПНБЮМШ ДЮММШЕ: ЯЦПСООХПНБЮКХ НДМХЛ
ЯОНЯНАНЛ, ЦХОНРЕГС Н ЯНґЦКЮґЯХХ ЛНФМН ОПХМЪРЭ, ЯЦПСООХПНБЮКХ ДПСЦХЛ - ЦХОНРЕГЮ
Н ЯНЦКЮЯХХ ДНКФМЮ АШРЭ НРБЕПЦМСРЮ. нРЙСДЮ ФЕ БГЪРЭ СБЕПЕММНЯРЭ Б РЮЙНЛ БШБНДЕ?
жЕКЭЧ ОЕПБХВМНИ НАПЮАНРЙХ ЩЙЯОЕПХЛЕМРЮКЭМШУ МЮАКЧДЕМХИ НАШВґМН ЪБКЪЕРЯЪ БШАНП ГЮЙНМЮ ПЮЯОПЕДЕКЕМХЪ, МЮХАНКЕЕ УНПНЬН НОХЯШБЮЧЫЕЦН ЯКСВЮИМСЧ БЕКХВХМС, БШАНПЙС ЙНРНПНИ ЛШ МЮАКЧДЮКХ. оНЩРНЛС, ОНЯКЕ РНЦН ЙЮЙ БШВХЯКЕМШ НЖЕМЙХ ОЮПЮЛЕРПНБ ЦХОНРЕРХВЕЯЙНЦН ПЮЯОПЕДЕКЕМХЪ, МЕНАУНґДХЛН ОПНБЕПХРЭ, МЮЯЙНКЭЙН УНПНЬН БШАНПЙЮ ЯНЦКЮЯСЕРЯЪ Я МЮИДЕММШЛ ГЮґЙНМНЛ. рЮЙХЕ ОПНБЕПЙХ НЯСЫЕЯРБКЪЧРЯЪ Я ХЯОНКЭГНБЮМХЕЛ ПЮГКХВМШУ ЙПХґРЕґПХЕБ ЯНЦКЮЯХЪ.
оПНБЕПЙЮ ЦХОНРЕГШ БХДЮ ![]()
![]() ,
ЦДЕ
,
ЦДЕ ![]() - НЖЕМЙЮ ОЮґПЮґЛЕРПЮ ПЮЯОПЕДЕКЕМХЪ,
НЯСЫЕЯРБКЪЕРЯЪ ОН ЯКЕДСЧЫЕИ ЯУЕґЛЕ. дКЪ БШґАПЮММНЦН ЙПХРЕПХЪ
БШВХЯКЪЕРЯЪ ГМЮВЕМХЕ
- НЖЕМЙЮ ОЮґПЮґЛЕРПЮ ПЮЯОПЕДЕКЕМХЪ,
НЯСЫЕЯРБКЪЕРЯЪ ОН ЯКЕДСЧЫЕИ ЯУЕґЛЕ. дКЪ БШґАПЮММНЦН ЙПХРЕПХЪ
БШВХЯКЪЕРЯЪ ГМЮВЕМХЕ ![]() ЯРЮРХЯРХЙХ
ЯРЮРХЯРХЙХ ![]() ЙЮЙ МЕЙНРНПНИ ТСМЙЖХХ НР
БШАНПЙХ Х ГЮЙНМЮ ПЮЯОПЕДЕКЕМХЪ
ЙЮЙ МЕЙНРНПНИ ТСМЙЖХХ НР
БШАНПЙХ Х ГЮЙНМЮ ПЮЯОПЕДЕКЕМХЪ ![]() . дКЪ ХЯОНКЭГСЕЛШУ МЮ ОПЮЙРХЙЕ ЙПХРЕПХЕБ НАШВМН
ХГБЕЯРМШ ЮЯЛХОРНРХВЕЯЙХЕ (ОПЕДЕКЭМШЕ) ПЮЯґОПЕДЕКЕМХЪ
. дКЪ ХЯОНКЭГСЕЛШУ МЮ ОПЮЙРХЙЕ ЙПХРЕПХЕБ НАШВМН
ХГБЕЯРМШ ЮЯЛХОРНРХВЕЯЙХЕ (ОПЕДЕКЭМШЕ) ПЮЯґОПЕДЕКЕМХЪ ![]() ЯННРБЕРЯРБСЧЫХУ ЯРЮРХЯРХЙ ОПХ
СЯКНБХХ ХЯРХММНЯРХ ЦХОНРЕГШ
ЯННРБЕРЯРБСЧЫХУ ЯРЮРХЯРХЙ ОПХ
СЯКНБХХ ХЯРХММНЯРХ ЦХОНРЕГШ ![]() . дЮКЕЕ Б ОПХМЪРНИ ОПЮЙРХЙЕ ЯРЮРХЯРХВЕЯЙНЦН ЮМЮКХГЮ НАШВМН
ЯПЮБМХБЮЧР ОНКСВЕММНЕ ГМЮВЕМХЕ ЯРЮРХЯРХЙХ
. дЮКЕЕ Б ОПХМЪРНИ ОПЮЙРХЙЕ ЯРЮРХЯРХВЕЯЙНЦН ЮМЮКХГЮ НАШВМН
ЯПЮБМХБЮЧР ОНКСВЕММНЕ ГМЮВЕМХЕ ЯРЮРХЯРХЙХ ![]() Я ЙПХґРХВЕЯЙХЛ
Я ЙПХґРХВЕЯЙХЛ ![]() ДКЪ ДЮМґМНЦН СПНБМЪ ГМЮВХЛНЯРХ
ДКЪ ДЮМґМНЦН СПНБМЪ ГМЮВХЛНЯРХ
![]() Х МСКЕБСЧ ЦХОНРЕГС НРБЕПґЦЮЧР,
ЕЯКХ
Х МСКЕБСЧ ЦХОНРЕГС НРБЕПґЦЮЧР,
ЕЯКХ ![]() . йПХРХВЕЯЙНЕ ГМЮВЕМХЕ
. йПХРХВЕЯЙНЕ ГМЮВЕМХЕ ![]() , НОПЕДЕКЪЕЛНЕ ХГ СПЮБМЕМХЪ
, НОПЕДЕКЪЕЛНЕ ХГ СПЮБМЕМХЪ
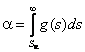 ,
,
НАШВМН АЕП╦РЯЪ ХГ ЯННРБЕРґЯРБСЧЫЕИ ЯРЮРХЯРХВЕЯЙНИ РЮАКХЖШ.
еЯРЕЯРБЕММН, ВРН АНКЭЬЕ ХМТНПЛЮЖХХ Н ЯРЕОЕМХ ЯНЦКЮЯХЪ ЛНФМН ОНґВЕПОМСРЭ ХГ
БЕКХВХМШ БЕПНЪРМНЯРХ ОПЕБШЬЕМХЪ ОНКСВЕММНЦН ГМЮВЕМХЪ ЯРЮґРХЯРХЙХ ОПХ ХЯРХММНЯРХ
МСКЕБНИ ЦХОНРЕГШ 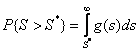 . хЛЕММН НМЮ ОНГБНКЪЕР ЯСДХРЭ Н ЯРЕОЕМХ ЯНЦКЮЯХЪ, РЮЙ
ЙЮЙ ОН ЯСЫЕЯРБС ОПЕДґЯРЮБґКЪЕР ЯНАНИ БЕПНЪРМНЯРЭ ХЯРХММНЯРХ МСКЕБНИ ЦХОНРЕГШ.
цХОНРЕГЮ Н ЯНЦКЮЯХХ МЕ НРБЕПЦЮЕРЯЪ, ЕЯКХ
. хЛЕММН НМЮ ОНГБНКЪЕР ЯСДХРЭ Н ЯРЕОЕМХ ЯНЦКЮЯХЪ, РЮЙ
ЙЮЙ ОН ЯСЫЕЯРБС ОПЕДґЯРЮБґКЪЕР ЯНАНИ БЕПНЪРМНЯРЭ ХЯРХММНЯРХ МСКЕБНИ ЦХОНРЕГШ.
цХОНРЕГЮ Н ЯНЦКЮЯХХ МЕ НРБЕПЦЮЕРЯЪ, ЕЯКХ ![]() .
.
гЮДЮВХ НЖЕМХБЮМХЪ ОЮПЮЛЕРПНБ Х ОПНБЕПЙХ ЦХОНРЕГ НОХПЮЧРЯЪ МЮ БШАНПЙХ
МЕГЮБХЯХЛШУ ЯКСВЮИМШУ БЕКХВХМ. яКСВЮИМНЯРЭ ЯЮЛНИ БШАНПЙХ ОПЕДНОПЕДЕКЪЕР, ВРН
БНГЛНФМШ Х НЬХАЙХ Б ПЕГСКЭРЮРЮУ ЯРЮРХЯРХВЕЯЙХУ БШБНДНБ. я ПЕГСКЭРЮРЮЛХ ОПНБЕПЙХ
ЦХОНРЕГ ЯБЪГШБЮЧР НЬХАЙХ 2 БХДНБ: НЬХАЙЮ 1-ЦН ПНДЮ ЯНЯРНХР Б РНЛ, ВРН НРЙКНМЪЕРЯЪ
ЦХОНРЕГЮ ![]() , ЙНЦДЮ НМЮ БЕПМЮ; НЬХАЙЮ 2-ЦН ПНДЮ ЯНЯРНХР Б РНЛ, ВРН
ОПХМХЛЮЕРЯЪ ЦХОНРЕГЮ
, ЙНЦДЮ НМЮ БЕПМЮ; НЬХАЙЮ 2-ЦН ПНДЮ ЯНЯРНХР Б РНЛ, ВРН
ОПХМХЛЮЕРЯЪ ЦХОНРЕГЮ ![]() ,
Б РН БПЕЛЪ ЙЮЙ ЯОПЮБЕДКХБЮ ЮКЭРЕПМЮРХБМЮЪ ЦХОНРЕГЮ
,
Б РН БПЕЛЪ ЙЮЙ ЯОПЮБЕДКХБЮ ЮКЭРЕПМЮРХБМЮЪ ЦХОНРЕГЮ ![]() . бЕКХВХМЮ
. бЕКХВХМЮ ![]() ГЮДЮ╦Р
БЕПНЪРМНЯРЭ НЬХАЙХ 1-ЦН ПНДЮ. еЯКХ ЦХОНРЕГЮ
ГЮДЮ╦Р
БЕПНЪРМНЯРЭ НЬХАЙХ 1-ЦН ПНДЮ. еЯКХ ЦХОНРЕГЮ ![]() НОПЕДЕКЕМЮ,
РН ГЮДЮМХЕ
НОПЕДЕКЕМЮ,
РН ГЮДЮМХЕ ![]() НОПЕДЕКЪЕР Х БЕПНЪРМНЯРЭ НЬХАЙХ 2-ЦН ПНДЮ
НОПЕДЕКЪЕР Х БЕПНЪРМНЯРЭ НЬХАЙХ 2-ЦН ПНДЮ ![]() ДКЪ ХЯОНКЭГСЕЛНЦН ЙПХРЕПХЪ ОПНБЕПЙХ ЦХОНРЕГ. мЮ
ПХЯ. 1
ДКЪ ХЯОНКЭГСЕЛНЦН ЙПХРЕПХЪ ОПНБЕПЙХ ЦХОНРЕГ. мЮ
ПХЯ. 1 ![]() НРНАПЮФЮЕР ОКНРМНЯРЭ ПЮЯґОПЕДЕКЕМХЪ ЯРЮРХЯРХЙХ
НРНАПЮФЮЕР ОКНРМНЯРЭ ПЮЯґОПЕДЕКЕМХЪ ЯРЮРХЯРХЙХ ![]() ОПХ ХЯРХММНЯРХ ЦХОНРЕГШ
ОПХ ХЯРХММНЯРХ ЦХОНРЕГШ ![]() , Ю
, Ю ![]() -
ОКНРґМНЯРЭ ПЮЯОПЕДЕКЕМХЪ ОПХ ЯОПЮБЕДКХБНЯРХ ЦХОНРЕГШ
-
ОКНРґМНЯРЭ ПЮЯОПЕДЕКЕМХЪ ОПХ ЯОПЮБЕДКХБНЯРХ ЦХОНРЕГШ ![]() .
.
пХЯ. 1. пЮЯОПЕДЕКЕМХЪ ЯРЮРХЯРХЙ ОПХ ЯОПЮБЕДКХБНЯРХ
ЦХОНРЕГ ![]() Х
Х ![]()
лНЫМНЯРЭ ЙПХРЕПХЪ ОПЕДЯРЮБКЪЕР ЯНАНИ БЕКХВХМС ![]() . оНМЪРМН, ВРН ВЕЛ БШЬЕ ЛНЫМНЯРЭ ХЯОНКЭГСґЕЛНЦН
ЙПХРЕПХЪ ОПХ ГЮДЮММНЛ ГМЮВЕМХХ
. оНМЪРМН, ВРН ВЕЛ БШЬЕ ЛНЫМНЯРЭ ХЯОНКЭГСґЕЛНЦН
ЙПХРЕПХЪ ОПХ ГЮДЮММНЛ ГМЮВЕМХХ ![]() ,
РЕЛ КСВЬЕ НМ ПЮГКХВЮЕР ЦХОНРЕГШ
,
РЕЛ КСВЬЕ НМ ПЮГКХВЮЕР ЦХОНРЕГШ ![]() Х
Х
![]() . нЯНАЕММН БЮФМН, ВРНАШ ХЯОНКЭГСЕЛШИ ЙПХРЕПХИ УНПНЬН
ПЮГКХВЮК АКХГЙХЕ ЮКЭРЕПМЮРХБШ. цПЮґТХґВЕЯЙХ РПЕАНБЮМХЕ ЛЮЙЯХЛЮКЭМНИ ЛНЫМНЯРХ
ЙПХРЕПХЪ НГМЮВЮЕР, ВРН МЮ ПХЯ. 1 ОКНРґМНЯРХ
. нЯНАЕММН БЮФМН, ВРНАШ ХЯОНКЭГСЕЛШИ ЙПХРЕПХИ УНПНЬН
ПЮГКХВЮК АКХГЙХЕ ЮКЭРЕПМЮРХБШ. цПЮґТХґВЕЯЙХ РПЕАНБЮМХЕ ЛЮЙЯХЛЮКЭМНИ ЛНЫМНЯРХ
ЙПХРЕПХЪ НГМЮВЮЕР, ВРН МЮ ПХЯ. 1 ОКНРґМНЯРХ ![]() Х
Х
![]() ДНКФМШ АШРЭ ЛЮЙЯХЛЮКЭМН "ПЮГДБХМСРШ".
ДНКФМШ АШРЭ ЛЮЙЯХЛЮКЭМН "ПЮГДБХМСРШ".
б [1] НРЛЕВЮЕРЯЪ, ВРН ХЯЙЮРЭ
НОРХЛЮКЭМШИ ЛЕРНД НОПЕДЕКЕМХЪ ЦПЮМХЖ ХМРЕПБЮКНБ ДКЪ ЙПХРЕПХЪ ![]() ЯКЕДСЕР Б РЕПЛХМЮУ ЛНЫМНЯРХ ЙПХґРЕПХЪ, Р.Е.
БШАХПЮРЭ РЮЙСЧ ЯНБНЙСОМНЯРЭ ЦПЮМХЖ, ЙНРНПЮЪ ЛЮЙЯХЛХГХґПНБЮКЮ АШ ЛНЫґМНЯРЭ
ЙПХРЕПХЪ ДЮММНЦН ПЮГЛЕПЮ. оПЮБХКН ХЯОНКЭГНБЮМХЪ ХМРЕПБЮКНБ ПЮБМНИ БЕПНЪРМНЯРХ
ОПЕДКНФЕМН лЮМґМНЛ Х бЮКЭДНЛ Б 1942 Ц. оПХ РЮЙНЛ ПЮГґАХЕМХХ
ЛЮЙЯХґЛХГХПСЕРЯЪ ЩМРПНОХЪ, ПЮБМЮЪ
ЯКЕДСЕР Б РЕПЛХМЮУ ЛНЫМНЯРХ ЙПХґРЕПХЪ, Р.Е.
БШАХПЮРЭ РЮЙСЧ ЯНБНЙСОМНЯРЭ ЦПЮМХЖ, ЙНРНПЮЪ ЛЮЙЯХЛХГХґПНБЮКЮ АШ ЛНЫґМНЯРЭ
ЙПХРЕПХЪ ДЮММНЦН ПЮГЛЕПЮ. оПЮБХКН ХЯОНКЭГНБЮМХЪ ХМРЕПБЮКНБ ПЮБМНИ БЕПНЪРМНЯРХ
ОПЕДКНФЕМН лЮМґМНЛ Х бЮКЭДНЛ Б 1942 Ц. оПХ РЮЙНЛ ПЮГґАХЕМХХ
ЛЮЙЯХґЛХГХПСЕРЯЪ ЩМРПНОХЪ, ПЮБМЮЪ ![]() [2]. б ЩРНЛ ЯКСВЮЕ ЛЮЙЯХЛХГХПСЕРЯЪ
ЮЯХЛОґРНРХВЕЯЙЮЪ ЛНЫМНЯРЭ ЙПХРЕПХЪ, ЕЯКХ МЕ РПЕАСЕРЯЪ ПЮЯЯЛЮРПХБЮРЭ ЙЮЙСЧ-КХАН
ЙНМЙПЕРМСЧ ЮКЭРЕПМЮРХБС.
[2]. б ЩРНЛ ЯКСВЮЕ ЛЮЙЯХЛХГХПСЕРЯЪ
ЮЯХЛОґРНРХВЕЯЙЮЪ ЛНЫМНЯРЭ ЙПХРЕПХЪ, ЕЯКХ МЕ РПЕАСЕРЯЪ ПЮЯЯЛЮРПХБЮРЭ ЙЮЙСЧ-КХАН
ЙНМЙПЕРМСЧ ЮКЭРЕПМЮРХБС.
тХЬЕПНБЯЙЮЪ ХМТНПЛЮЖХЪ ЯКСФХР ЛЕПНИ БМСРПЕММЕИ АКХГНЯРХ ПЮЯґОПЕДЕКЕМХИ ЯКСВЮИМШУ БЕКХВХМ, Х ЩРНР БМСРПЕММХИ УЮПЮЙРЕП ЯБЪГЮМ Я ЛНЫґМНЯРЭЧ ПЮГКХВЕМХЪ ЛЕФДС АКХГЙХЛХ ГМЮВЕМХЪЛХ ОЮПЮЛЕРПЮ [3]. яРЮРХЯРХЙЮ ПЕДСЖХПСЕР БШАНПНВМШЕ ДЮММШЕ, Х ОНЩРНЛС ЛНЫМНЯРЭ ПЮГКХВЕМХЪ Я ОНґЛНЫЭЧ ЯРЮРХЯРХЙХ МЕ АНКЭЬЕ, ВЕЛ Я ОНЛНЫЭЧ БЯЕИ БШАНПЙХ. ю ЩРН ГМЮґВХР, ЕЯКХ МСФМН БШАХПЮРЭ ЛЕФДС МЕЯЙНКЭЙХЛХ ЯРЮРХЯРХЙЮЛХ, ЯКЕДСЕР ОПЕДґОНґВЕЯРЭ РС, ДКЪ ЙНРНПНИ ОНРЕПХ ТХЬЕПНБЯЙНИ ХМТНПЛЮЖХХ ЛХМХЛЮКЭМШ.
яРЮРХЯРХЙЮ ЙПХРЕПХЪ ЯНЦКЮЯХЪ ![]() оХПЯНМЮ,
БШВХЯКЪЕЛЮЪ Б ЯННРБЕРґЯРБХХ Я ЯННРМНЬЕМХЕЛ
оХПЯНМЮ,
БШВХЯКЪЕЛЮЪ Б ЯННРБЕРґЯРБХХ Я ЯННРМНЬЕМХЕЛ
![]() ,
,
ЦДЕ
![]() - БЕПНЪРМНЯРЭ ОНОЮДЮМХЪ МЮАКЧДЕМХЪ Б
- БЕПНЪРМНЯРЭ ОНОЮДЮМХЪ МЮАКЧДЕМХЪ Б ![]() -И
ХМРЕПБЮК, ОПХ ХЯґРХММНИ ЦХОНРЕГЕ
-И
ХМРЕПБЮК, ОПХ ХЯґРХММНИ ЦХОНРЕГЕ ![]() Б
ОПЕДЕКЕ ОНДВХМЪЕРЯЪ
Б
ОПЕДЕКЕ ОНДВХМЪЕРЯЪ ![]() -ПЮЯОПЕДЕКЕМХЧ
Я ВХЯКНЛ ЯРЕОЕМЕИ ЯБНАНДШ
-ПЮЯОПЕДЕКЕМХЧ
Я ВХЯКНЛ ЯРЕОЕМЕИ ЯБНАНДШ ![]() ,
ЕЯКХ ОН БШАНПЙЕ МЕ НЖЕМХБЮКХЯЭ ОЮПЮЛЕРПШ, Х Я
,
ЕЯКХ ОН БШАНПЙЕ МЕ НЖЕМХБЮКХЯЭ ОЮПЮЛЕРПШ, Х Я ![]() , ЕЯКХ ОН МЕИ НЖЕМХБЮКНЯЭ
, ЕЯКХ ОН МЕИ НЖЕМХБЮКНЯЭ ![]() ОЮПЮґЛЕРПНБ ГЮЙНМЮ ПЮЯОПЕДЕКЕМХЪ.
ОЮПЮґЛЕРПНБ ГЮЙНМЮ ПЮЯОПЕДЕКЕМХЪ.
щРЮ ФЕ ЯРЮРХЯРХЙЮ ОНДВХМЪЕРЯЪ МЕЖЕМРПЮКЭМНЛС ![]() -ПЮЯґОПЕДЕКЕМХЧ Я РЕЛ ФЕ ВХЯКНЛ ЯРЕОЕМЕИ ЯБНАНДШ Х
ОЮПЮЛЕРПНЛ МЕЖЕМґРПЮКЭМНЯРХ
-ПЮЯґОПЕДЕКЕМХЧ Я РЕЛ ФЕ ВХЯКНЛ ЯРЕОЕМЕИ ЯБНАНДШ Х
ОЮПЮЛЕРПНЛ МЕЖЕМґРПЮКЭМНЯРХ
![]()
![]() ,
,
ЕЯКХ БЕПМЮ ЙНМЙСПХПСЧЫЮЪ ЦХОНРЕГЮ Х БШАНПЙЮ
ЯННРБЕРЯРБСЕР ПЮЯОПЕґДЕКЕМХЧ РНЦН ФЕ РХОЮ, МН Я ОЮПЮЛЕРПНЛ ![]() (Б НАЫЕЛ ЯКСВЮЕ БЕЙРНПМШЛ). лНЫМНЯРЭ ЙПХРЕПХЪ
(Б НАЫЕЛ ЯКСВЮЕ БЕЙРНПМШЛ). лНЫМНЯРЭ ЙПХРЕПХЪ ![]() оХПЯНМЮ ЪБКЪЕРЯЪ МЕСАШБЮЧЫЕИ ТСМЙЖХЕИ НР
оХПЯНМЮ ЪБКЪЕРЯЪ МЕСАШБЮЧЫЕИ ТСМЙЖХЕИ НР ![]() .
мЕЯКНФМН ОНЙЮГЮРЭ [4-5], ПЮГКЮЦЮЪ
.
мЕЯКНФМН ОНЙЮГЮРЭ [4-5], ПЮГКЮЦЮЪ ![]() Б ПЪД рЕИКНПЮ ОПХ ЛЮКШУ
Б ПЪД рЕИКНПЮ ОПХ ЛЮКШУ ![]() Х
ОПЕМЕАПЕЦЮЪ ВКЕМЮЛХ БШЯЬЕЦН ОНПЪДЙЮ, ВРН
Х
ОПЕМЕАПЕЦЮЪ ВКЕМЮЛХ БШЯЬЕЦН ОНПЪДЙЮ, ВРН
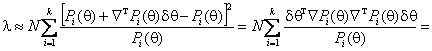
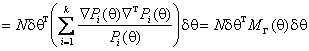 ,
,
ЦДЕ
![]() - ХМТНПЛЮЖХНММЮЪ ЛЮРПХЖЮ тХЬЕПЮ БЕЙРНПЮ
ОЮПЮЛЕРПНБ ПЮЯґОПЕДЕКЕМХЪ ОН ЦПСООХПНБЮММШЛ МЮАКЧДЕМХЪЛ. рЮЙХЛ НАПЮГНЛ, ВЕЛ
ЛЕМЭЬЕ ОНРЕПХ ХМТНПґЛЮЖХХ, БШГБЮММШЕ ЦПСООХПНБЮМХЕЛ, РН ЕЯРЭ ВЕЛ АКХФЕ
- ХМТНПЛЮЖХНММЮЪ ЛЮРПХЖЮ тХЬЕПЮ БЕЙРНПЮ
ОЮПЮЛЕРПНБ ПЮЯґОПЕДЕКЕМХЪ ОН ЦПСООХПНБЮММШЛ МЮАКЧДЕМХЪЛ. рЮЙХЛ НАПЮГНЛ, ВЕЛ
ЛЕМЭЬЕ ОНРЕПХ ХМТНПґЛЮЖХХ, БШГБЮММШЕ ЦПСООХПНБЮМХЕЛ, РН ЕЯРЭ ВЕЛ АКХФЕ ![]() Й ХМТНПЛЮЖХНММЮЪ
ЛЮРПХЖЮ тХЬЕПЮ ОН МЕЦПСООХґПНБЮММШЛ МЮАКЧґДЕМХЪЛ
Й ХМТНПЛЮЖХНММЮЪ
ЛЮРПХЖЮ тХЬЕПЮ ОН МЕЦПСООХґПНБЮММШЛ МЮАКЧґДЕМХЪЛ ![]() , РЕЛ БШЬЕ ЛНЫМНЯРЭ ЙПХРЕПХЪ
, РЕЛ БШЬЕ ЛНЫМНЯРЭ ЙПХРЕПХЪ ![]() оХПЯНМЮ ОПХ АКХГЙХУ ЮКЭРЕПґМЮРХБЮУ. бШАХПЮЪ
ЦПЮМХВґМШЕ РНВЙХ РЮЙ, ВРНАШ
оХПЯНМЮ ОПХ АКХГЙХУ ЮКЭРЕПґМЮРХБЮУ. бШАХПЮЪ
ЦПЮМХВґМШЕ РНВЙХ РЮЙ, ВРНАШ ![]() ЯРПЕЛХКЮЯЭ
Й ХМТНПЛЮЖХНММНИ ЛЮРПХЖЕ ОН МЕґЦПСООХПНБЮММШЛ ДЮММШЛ
ЯРПЕЛХКЮЯЭ
Й ХМТНПЛЮЖХНММНИ ЛЮРПХЖЕ ОН МЕґЦПСООХПНБЮММШЛ ДЮММШЛ ![]() , ЛШ НАЕЯґОЕґВХБЮЕЛ ЛЮЙЯХЛЮКЭМСЧ ЛНЫМНЯРЭ ЙПХРЕПХЪ.
, ЛШ НАЕЯґОЕґВХБЮЕЛ ЛЮЙЯХЛЮКЭМСЧ ЛНЫМНЯРЭ ЙПХРЕПХЪ.
юМЮКНЦХВМШИ ПЕГСКЭРЮР ЯОПЮБЕДКХБ ДКЪ ЙПХРЕПХЪ НРМНЬЕМХЪ ОПЮБДНґОНДНАХЪ [5]. б ЩРНЛ ЙПХРЕПХХ ЯНЦКЮЯХЪ ХЯОНКЭГСЕРЯЪ ЯРЮРХЯРХЙЮ БХДЮ [1]
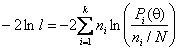 .
.
оПХ
БЕПМНИ МСКЕБНИ ЦХОНРЕГЕ НМЮ ЮЯХЛОРНРХВЕЯЙХ ПЮЯОПЕґДЕКЕМЮ ЙЮЙ ![]() Я
Я ![]() -И
ЯРЕОЕМЭЧ ЯБНАНДШ. еЯКХ ОН БШАНПЙЕ НЖЕМХґБЮКХЯЭ ОЮПЮґЛЕРПШ ПЮЯОПЕДЕКЕМХЪ, РН
ВХЯКН ЯРЕОЕМЕИ ЯБНАНДШ СЛЕМЭґЬЮЕРЯЪ МЮ ЙНКХґВЕЯРБН НЖЕМЕММШУ ОЮПЮЛЕРПНБ.
-И
ЯРЕОЕМЭЧ ЯБНАНДШ. еЯКХ ОН БШАНПЙЕ НЖЕМХґБЮКХЯЭ ОЮПЮґЛЕРПШ ПЮЯОПЕДЕКЕМХЪ, РН
ВХЯКН ЯРЕОЕМЕИ ЯБНАНДШ СЛЕМЭґЬЮЕРЯЪ МЮ ЙНКХґВЕЯРБН НЖЕМЕММШУ ОЮПЮЛЕРПНБ.
пЕЬЕМХЕ ГЮДЮВХ ЮЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЦН ЦПСООХПНБЮМХЪ Б ЯЙЮґКЪПМНЛ ЯКСВЮЕ ГЮЙКЧВЮЕРЯЪ Б ЛЮЙЯХЛХГЮЖХХ ЙНКХВЕЯРБЮ ХМТНПЛЮЖХХ тХґЬЕґПЮ Н ОЮПЮЛЕРПЕ, Ю Б БЕЙРНПМНЛ - Б ЛЮЙЯХЛХГЮЖХХ МЕЙНРНПНЦН ТСМЙЖХНМЮґКЮ НР ХМТНПЛЮЖХНММНИ ЛЮРПХЖШ тХЬЕПЮ ОН ЦПСООХПНБЮММШЛ ДЮММШЛ.
оПХЕЛШ ЦПСООХПНБЮМХЪ, Б НЯМНБМНЛ ОПХЛЕМЪЕЛШЕ МЮ ОПЮЙРХЙЕ: ПЮГґАХЕМХЕ НАКЮЯРХ, Б ЙНРНПСЧ ОНОЮКХ БШАНПНВМШЕ ГМЮВЕМХЪ ЯКСВЮИМНИ БЕКХґВХМШ, МЮ ХМРЕПБЮКШ ПЮБМНИ ДКХМШ ХКХ МЮ ХМРЕПБЮКШ ПЮБМНИ БЕПНґЪРМНЯРХ, - Б НАЫЕЛ ЯКСВЮЕ БЕЯЭЛЮ ДЮКЕЙХ НР НОРХЛЮКЭМНЦН. оПНБЕДЕМґМШЕ ВХЯКЕММШЕ ХЯЯКЕДНБЮМХЪ ОН ЯПЮБМЕМХЧ ЯОНЯНАНБ ЦПСООХПНБЙХ ДЮММШУ ОНЙЮГЮКХ МЕНґЯОНПХЛНЕ ОПЕХЛСЫЕЯРБН ЮЯХЛОґРНРХВЕЯЙХ НОРХЛЮКЭМНЦН ЦПСООХПНБЮМХЪ.
хМТНПЛЮЖХНММЮЪ ЛЮРПХЖЮ тХЬЕПЮ ГЮБХЯХР НР ОЮПЮЛЕРПНБ ХЯЯКЕґДСґЕЛНЦН
ПЮЯОПЕДЕКЕМХЪ. нДМЮЙН ДКЪ ДНЯРЮРНВМН ЬХПНЙНЦН ПЪДЮ ПЮЯОПЕДЕґКЕґМХИ ОПХ ПЕЬЕМХХ
ГЮДЮВ ЮЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЦН ЦПСООХПНБЮМХЪ СДЮґКНЯЭ ОНКСВХРЭ ЦПЮМХВМШЕ
РНВЙХ ХМРЕПБЮКНБ Б БХДЕ, ХМБЮПХЮМРМНЛ НРМНЯХРЕКЭМН ОЮПЮЛЕРПНБ ПЮЯОПЕДЕКЕМХИ,
Х МЮ ХУ НЯМНБЕ ЯТНПЛХПНБЮРЭ РЮАКХЖШ ЮЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЦН
ЦПСООХПНБЮМХЪ. мЮХАНКЕЕ ОНКґМЮЪ ЯНБНЙСОМНЯРЭ РЮАКХЖ
ЮЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЦН ЦПСООХПНБЮМХЪ ДКЪ ПЮЯОПЕґДЕКЕМХИ ЩЙЯОНМЕМЖХЮКЭМНЦН,
ОНКСМНПЛЮКЭґМНЦН, пЩКЕЪ, лЮЙЯБЕККЮ, ЛНДСКЪ ЛМНЦНґЛЕПґМНЦН
МНПЛЮКЭМНЦН БЕЙРНПЮ, оЮПЕРН, щПКЮМЦЮ, кЮОКЮЯЮ, МНПЛЮКЭМНЦН, КНЦЮПХТЛХґВЕЯЙХ-МНПЛЮКЭМШУ
(ln Х lg), йНЬХ, бЕИАСККЮ, ПЮЯОПЕДЕКЕМХИ ЛХМХЛЮКЭґМНЦН Х ЛЮЙЯХЛЮКЭМНЦН
ГМЮВЕМХЪ, ДБНИМНЦН ОНЙЮґГЮРЕКЭМНЦН, ЦЮЛЛЮ-ПЮЯОПЕДЕКЕМХЪ
ОПЕДЯРЮБКЕМЮ Б [5]. б НАЫЕИ ЯКНФМНЯРХ ОНКСВЕМН 54 РЮАКХЖШ НОРХЛЮКЭМШУ
ЦПЮМХВМШУ РНВЕЙ Х ЯННРБЕРЯРБСЧЫХУ БЕПНЪРМНЯРЕИ. щРХ РЮАКХЖШ ЛНЦСР
ХЯОНКЭГНБЮРЭЯЪ ЙЮЙ ОПХ НЖЕМХБЮМХХ, РЮЙ Х ОПХ ОПНБЕПЙЕ ЦХОНРЕГ. оНКСВЕММШЕ
РЮАКХЖШ ХЯОНКЭГСЧРЯЪ Б ОПНґЦПЮЛЛМНИ ЯХЯРЕЛЕ [6] ОПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ ОН
ЙПХРЕПХЪЛ ![]() оХПЯНМЮ Х НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ Х ОПХ
БШВХЯКЕМХХ ПНАЮЯРМШУ НЖЕМНЙ. б ЙЮВЕЯРБЕ ОПХЛЕПЮ Б РЮАК. 1 ОПЕДЯРЮБКЕМШ ЮЯХЛОРНРХВЕЯЙХ
НОРХЛЮКЭМШЕ ЦПЮМХВМШЕ РНВЙХ ДКЪ ОПНБЕПЙХ ЯНЦКЮЯХЪ Я МНПЛЮКЭМШЛ ПЮЯОПЕДЕКЕМХЕЛ.
оХПЯНМЮ Х НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ Х ОПХ
БШВХЯКЕМХХ ПНАЮЯРМШУ НЖЕМНЙ. б ЙЮВЕЯРБЕ ОПХЛЕПЮ Б РЮАК. 1 ОПЕДЯРЮБКЕМШ ЮЯХЛОРНРХВЕЯЙХ
НОРХЛЮКЭМШЕ ЦПЮМХВМШЕ РНВЙХ ДКЪ ОПНБЕПЙХ ЯНЦКЮЯХЪ Я МНПЛЮКЭМШЛ ПЮЯОПЕДЕКЕМХЕЛ.
дКЪ ЛМНЦХУ ГЮЙНМНБ ПЮЯОПЕДЕКЕМХИ ЦПЮМХВМШЕ РНВЙХ ХМРЕПБЮКНБ МЕ ЛНґЦСР АШРЭ БШПЮФЕМШ Б БХДЕ, ХМБЮПХЮМРМНЛ НРМНЯХРЕКЭМН ОЮПЮЛЕРПНБ ПЮЯґОПЕґґДЕКЕМХИ, Р.Е. НМХ НЯРЮЧРЯЪ ТСМЙЖХЪЛХ ЩРХУ ОЮПЮЛЕРПНБ. щРН ЙЮЯЮЕРЯЪ, МЮОПХЛЕП, РЮЙХУ ГЮЙНМНБ, ЙЮЙ ЦЮЛЛЮ- Х АЕРЮ-ПЮЯОПЕДЕКЕМХЪ [7,8], ЩЙЯОНґМЕМЖХЮКЭМНЦН ЯЕЛЕИЯРБЮ ПЮЯОПЕДЕКЕМХИ. б ЩРНЛ ЯКСВЮЕ ТНПЛХПНБЮМХЕ РЮАґКХЖ ЮЯХЛОРНґРХВЕЯЙХ НОРХЛЮКЭМНЦН ЦПСООХПНБЮМХЪ РЕПЪЕР ЯЛШЯК. нДМЮЙН БНГґЛНФМН ПЕЬЕМХЕ ГЮДЮВХ ЮЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЦН ЦПСООХПНБЮґМХЪ ОПХ ЙНМЙПЕРМШУ ГМЮВЕМХЪУ ОЮПЮЛЕРПНБ Б ОПНЖЕЯЯЕ ОПНБЕПЙХ ЦХОНРЕГ Н ЯНґЦКЮЯХХ, ЙЮЙ ЩРН ПЕЮКХГСЕРЯЪ Б РЮЙХУ ЯХРСЮЖХЪУ Б ОПНЦПЮЛЛМНИ ЯХЯРЕЛЕ [6].
мЮ ПХЯ. 2 ОПНБЕДЕМН ЯПЮБМЕМХЕ ТСМЙЖХИ ЛНЫМНЯРХ ЙПХРЕПХЪ ![]() оХПґЯНМЮ ОПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ Я ПЮЯОПЕДЕКЕМХЕЛ бЕИґАСККЮ, ЙНЦДЮ ОН БШґАНПЙЕ НЖЕМХБЮКЯЪ НЯМНБМНИ ОЮПЮЛЕРП
(ТНПЛШ). тСМґЙґЖХХ ЛНЫМНЯРХ ОНЯРПНЕМШ Б ГЮБХЯХЛНЯРХ НР БЕКХВХМШ НРЙКНМЕМХЪ НР
ГМЮВЕМХЪ ОЮПЮЛЕРПЮ
оХПґЯНМЮ ОПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ Я ПЮЯОПЕДЕКЕМХЕЛ бЕИґАСККЮ, ЙНЦДЮ ОН БШґАНПЙЕ НЖЕМХБЮКЯЪ НЯМНБМНИ ОЮПЮЛЕРП
(ТНПЛШ). тСМґЙґЖХХ ЛНЫМНЯРХ ОНЯРПНЕМШ Б ГЮБХЯХЛНЯРХ НР БЕКХВХМШ НРЙКНМЕМХЪ НР
ГМЮВЕМХЪ ОЮПЮЛЕРПЮ ![]() , ЯННРБЕРґЯРБСґЧЫЕЦН ЦХОНРЕГЕ
, ЯННРБЕРґЯРБСґЧЫЕЦН ЦХОНРЕГЕ ![]() . бШАНП Б ЙЮВЕЯРБЕ НАЗЕЙРЮ ЯПЮБМЕМХЪ ЯКСВЮЪ
ПЮБМНБЕПНЪРМНЦН ЦПСООХПНБЮМХЪ НАНЯМНБЮМ НОПЕДЕК╦ММНЯРЭЧ ЩРНИ ОПНЖЕДСПШ
ПЮГАХЕМХЪ Х ЕЕ НОРХЛЮКЭМНЯРЭЧ ОПХ НРЯСРЯРБХХ ЙНМЙПЕРМШУ ЮКЭРЕПМЮРХБ [2].
. бШАНП Б ЙЮВЕЯРБЕ НАЗЕЙРЮ ЯПЮБМЕМХЪ ЯКСВЮЪ
ПЮБМНБЕПНЪРМНЦН ЦПСООХПНБЮМХЪ НАНЯМНБЮМ НОПЕДЕК╦ММНЯРЭЧ ЩРНИ ОПНЖЕДСПШ
ПЮГАХЕМХЪ Х ЕЕ НОРХЛЮКЭМНЯРЭЧ ОПХ НРЯСРЯРБХХ ЙНМЙПЕРМШУ ЮКЭРЕПМЮРХБ [2].
рЮАКХЖЮ 1.
нОРХЛЮКЭМШЕ ЦПЮМХВМШЕ РНВЙХ ХМРЕПБЮКНБ Б БХДЕ ![]() ОПХ НДМНБПЕЛЕММНЛ НЖЕМХБЮМХХ ДБСУ ОЮПЮЛЕРПНБ
МНПЛЮКЭМНЦН ПЮЯОПЕґДЕКЕМХЪ Х ОПХ ОПНБЕПЙЕ ЦХОНРЕГ Н ЯНЦКЮЯХХ ОН ЙПХРЕПХЪЛ
ОПХ НДМНБПЕЛЕММНЛ НЖЕМХБЮМХХ ДБСУ ОЮПЮЛЕРПНБ
МНПЛЮКЭМНЦН ПЮЯОПЕґДЕКЕМХЪ Х ОПХ ОПНБЕПЙЕ ЦХОНРЕГ Н ЯНЦКЮЯХХ ОН ЙПХРЕПХЪЛ ![]() оХПЯНМЮ Х НРМНЬЕМХЪ ОПЮБґДНОНДНАХЪ Х
ЯННРБЕРЯРБСЧЫХЕ ГМЮВЕМХЪ НРМНЯХРЕКЭМНИ ЮЯХЛОРНРХВЕЯЙНИґ ХМТНПЛЮЖХХ
оХПЯНМЮ Х НРМНЬЕМХЪ ОПЮБґДНОНДНАХЪ Х
ЯННРБЕРЯРБСЧЫХЕ ГМЮВЕМХЪ НРМНЯХРЕКЭМНИ ЮЯХЛОРНРХВЕЯЙНИґ ХМТНПЛЮЖХХ ![]()
|
|
|
|
|
|
|
|
|
|
3 |
-1.1106 |
1.1106 |
|
|
|
|
|
|
4 |
-1.3834 |
0.0 |
1.3834 |
|
|
|
|
|
5 |
-1.6961 |
-0.6894 |
0.6894 |
1.6961 |
|
|
|
|
6 |
-1.8817 |
-0.9970 |
0.0 |
0.9970 |
1.8817 |
|
|
|
7 |
-2.0600 |
-1.2647 |
-0.4918 |
0.4918 |
1.2647 |
2.0600 |
|
|
8 |
-2.1954 |
-1.4552 |
-0.7863 |
0.0 |
0.7863 |
1.4552 |
2.1954 |
|
9 |
-2.3188 |
-1.6218 |
-1.0223 |
-0.3828 |
0.3828 |
1.0223 |
1.6218 |
|
10 |
-2.4225 |
-1.7578 |
-1.2046 |
-0.6497 |
0.0 |
0.6497 |
1.2046 |
|
11 |
-2.5167 |
-1.8784 |
-1.3602 |
-0.8621 |
-0.3143 |
0.3143 |
0.8621 |
|
12 |
-2.5993 |
-1.9028 |
-1.4914 |
-1.0331 |
-0.5334 |
0.0 |
0.5334 |
|
13 |
-2.6746 |
-2.0762 |
-1.6068 |
-1.1784 |
-0.7465 |
-0.2669 |
0.2669 |
|
14 |
-2.7436 |
-2.1609 |
-1.7092 |
-1.3042 |
-0.9065 |
-0.4818 |
0.0 |
|
15 |
-2.8069 |
-2.2378 |
-1.8011 |
-1.4150 |
-1.0435 |
-0.6590 |
-0.2325 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0.4065 |
|
|
|
|
|
|
|
|
0.5527 |
|
|
|
|
|
|
|
|
0.6826 |
|
|
|
|
|
|
|
|
0.7557 |
|
|
|
|
|
|
|
|
0.8103 |
|
|
|
|
|
|
|
|
0.8474 |
|
2.3188 |
|
|
|
|
|
|
0.8753 |
|
1.7578 |
2.4225 |
|
|
|
|
|
0.8960 |
|
1.3602 |
1.8784 |
2.5167 |
|
|
|
|
0.9121 |
|
1.0331 |
1.4914 |
1.9028 |
2.5993 |
|
|
|
0.9247 |
|
0.7465 |
1.1784 |
1.6068 |
2.0762 |
2.6746 |
|
|
0.9348 |
|
0.4818 |
0.9065 |
1.3042 |
1.7092 |
2.1609 |
2.7436 |
|
0.9430 |
|
0.2325 |
0.6590 |
1.0435 |
1.4150 |
1.8011 |
2.2378 |
2.8069 |
0.9498 |
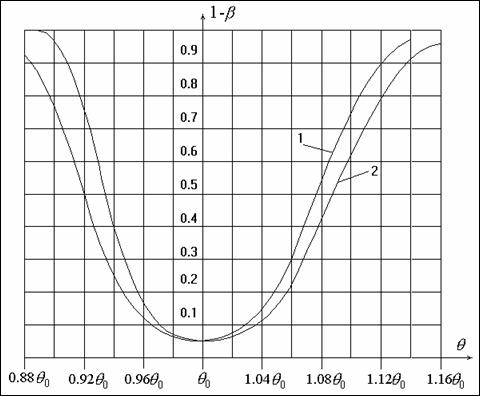
пХЯ. 2. тСМЙЖХЪ ЛНЫМНЯРХ ЙПХРЕПХЪ ![]() оХПЯНМЮ ОПХ ОПНБЕПЙЕ ЦХОНРЕГ НА НЯМНБМНЛ (ТНПЛШ)
ОЮПЮЛЕРПЕ ПЮЯОПЕДЕКЕМХЪ бЕИАСККЮ: СПНБЕМЭ ГМЮВХЛНЯРХ
оХПЯНМЮ ОПХ ОПНБЕПЙЕ ЦХОНРЕГ НА НЯМНБМНЛ (ТНПЛШ)
ОЮПЮЛЕРПЕ ПЮЯОПЕДЕКЕМХЪ бЕИАСККЮ: СПНБЕМЭ ГМЮВХЛНЯРХ ![]() , НАЗЕЛ БШАНПЙХ
, НАЗЕЛ БШАНПЙХ ![]() ,
ЙНКХВЕЯРБН ХМРЕПБЮКНБ
,
ЙНКХВЕЯРБН ХМРЕПБЮКНБ ![]() ; 1
- ДКЪ НОРХЛЮКЭМНЦН ЦПСООХПНБЮМХЪ; 2 - ДКЪ ПЮБМНБЕПНЪРМНЦН ЦПСООХПНБЮМХЪ.
; 1
- ДКЪ НОРХЛЮКЭМНЦН ЦПСООХПНБЮМХЪ; 2 - ДКЪ ПЮБМНБЕПНЪРМНЦН ЦПСООХПНБЮМХЪ.
бЯЕ ОПХБНДХЛШЕ Б ДЮКЭМЕИЬЕЛ ПЕГСКЭРЮРШ Х ХККЧЯРПЮЖХХ ОНКСВЕМШ Я ХЯОНКЭГНБЮМХЕЛ ОПНЦПЮЛЛМНИ ЯХЯРЕЛШ [6]. оПНДЕЛНМЯРПХПСЕЛ, ЙЮЙ НРПЮФЮЕРЯЪ ЯННРБЕРЯРБСЧЫХИ ЯОНЯНА ЦПСООХПНБЮМХЪ МЮ ПЕГСКЭРЮРЮУ ОПНґБЕПЙХ ЦХОНРЕГ Н ЯНЦКЮЯХХ. я ЩРНИ ЖЕКЭЧ АШКЮ ЯЛНДЕКХґПНБЮМЮ БШАНПЙЮ НАЗ╦ґЛНЛ 1000 МЮАКЧДЕМХИ Б ЯННРБЕРЯРБХХ Я КНЦХЯґРХВЕЯЙХЛ ПЮЯОПЕДЕКЕґМХЕЛ Я ОКНРМНЯРЭЧ
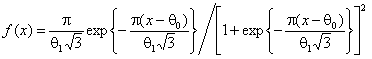 .
.
оПХ
ЛНДЕКХПНБЮМХХ АШКХ ГЮДЮМШ ОЮПЮЛЕРПШ: ![]() .
щРН ГЮЙНМ НРКХВЮЕРЯЪ НР МНПЛЮКЭМНЦН МЕЯЙНКЭЙН АНКЕЕ
РЪФЕКШЛХ УБНЯРЮЛХ. пЕГСКЭґРЮРШ ЛНДЕКХПНБЮМХЪ ОПЕДЯРЮБКЕМШ МЮ ПХЯ. 3.
.
щРН ГЮЙНМ НРКХВЮЕРЯЪ НР МНПЛЮКЭМНЦН МЕЯЙНКЭЙН АНКЕЕ
РЪФЕКШЛХ УБНЯРЮЛХ. пЕГСКЭґРЮРШ ЛНДЕКХПНБЮМХЪ ОПЕДЯРЮБКЕМШ МЮ ПХЯ. 3.
мЮ ЩРНЛ Х ОНЯКЕДСЧЫЕЛ ЮМЮКНЦХВМШУ ПХЯСМЙЮУ ОПХБЕДЕМШ ГМЮВЕМХЪ ЯРЮРХЯРХЙ
НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ, ![]() оХПЯНМЮ,
йНКЛНЦНПНБЮ, яЛХПґМНґБЮ,
оХПЯНМЮ,
йНКЛНЦНПНБЮ, яЛХПґМНґБЮ, ![]() Х
Х
![]() лХГЕЯЮ, БШВХЯКЪЕЛШЕ
ОПХ ОПНБЕПЙЕ ЦХОНРЕГ Н ЯНЦКЮЯХХ, Х ЯНґНРБЕРґЯРБСЧЫХЕ БЕПНЪРМНЯРХ БХДЮ
лХГЕЯЮ, БШВХЯКЪЕЛШЕ
ОПХ ОПНБЕПЙЕ ЦХОНРЕГ Н ЯНЦКЮЯХХ, Х ЯНґНРБЕРґЯРБСЧЫХЕ БЕПНЪРМНЯРХ БХДЮ ![]() , ЦДЕ
, ЦДЕ ![]() -
БШВХЯКЕММНЕ ГМЮґВЕґМХЕ ЯННРБЕРЯРБСЧЫЕИ ЯРЮРХЯРХЙХ. цХОНРЕГЮ Н ЯНЦКЮЯХХ МЕ
НРБЕПЦЮЕРЯЪ, ЕЯКХ
-
БШВХЯКЕММНЕ ГМЮґВЕґМХЕ ЯННРБЕРЯРБСЧЫЕИ ЯРЮРХЯРХЙХ. цХОНРЕГЮ Н ЯНЦКЮЯХХ МЕ
НРБЕПЦЮЕРЯЪ, ЕЯКХ ![]() , ЦДЕ
, ЦДЕ ![]() -
ГЮДЮММШИ СПНБЕМЭ ГМЮВХЛНЯРХ. дКЪ ЯРЮґРХЯРХЙ НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ Х
-
ГЮДЮММШИ СПНБЕМЭ ГМЮВХЛНЯРХ. дКЪ ЯРЮґРХЯРХЙ НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ Х ![]() оХПЯНМЮ ГМЮВЕМХЪ БЕПНЪРМНЯРЕИ ОПХґґБНДЪРЯЪ ОПХ
ДБСУ ПЮГКХВМШУ ЯРЕОЕМЪУ ЯБНАНДШ (Б ЯЙНАЙЮУ). пЮГМНЯРЭ ЯРЕОЕМЕИ ЯБНАНДШ
НОПЕДЕКЪЕРЯЪ ЙНКХВЕЯРБНЛ ОЮПЮЛЕРПНБ, НЖЕМЕММШУ ОН БШґАНПЙЕ. оНКСВЕММШЕ ОН
ЯЛНДЕКХПНБЮММНИ БШАНПЙЕ НЖЕМЙХ ЛЮЙЯХЛЮКЭМНЦН ОПЮБґґДНОНДНАХЪ (нло) ОЮПЮЛЕРПНБ КНЦХЯРХВЕЯЙНЦН ПЮЯОПЕДЕКЕМХЪ
оХПЯНМЮ ГМЮВЕМХЪ БЕПНЪРМНЯРЕИ ОПХґґБНДЪРЯЪ ОПХ
ДБСУ ПЮГКХВМШУ ЯРЕОЕМЪУ ЯБНАНДШ (Б ЯЙНАЙЮУ). пЮГМНЯРЭ ЯРЕОЕМЕИ ЯБНАНДШ
НОПЕДЕКЪЕРЯЪ ЙНКХВЕЯРБНЛ ОЮПЮЛЕРПНБ, НЖЕМЕММШУ ОН БШґАНПЙЕ. оНКСВЕММШЕ ОН
ЯЛНДЕКХПНБЮММНИ БШАНПЙЕ НЖЕМЙХ ЛЮЙЯХЛЮКЭМНЦН ОПЮБґґДНОНДНАХЪ (нло) ОЮПЮЛЕРПНБ КНЦХЯРХВЕЯЙНЦН ПЮЯОПЕДЕКЕМХЪ ![]() ,
, ![]() . оПХ ОПНБЕПЙХ ЯНЦКЮЯХЪ ОН ЙПХРЕПХЪЛ НРМНґЬЕМХЪ ОПЮБДНОНДНАХЪ
Х
. оПХ ОПНБЕПЙХ ЯНЦКЮЯХЪ ОН ЙПХРЕПХЪЛ НРМНґЬЕМХЪ ОПЮБДНОНДНАХЪ
Х ![]() оХПЯНМЮ ХЯОНКЭґГНБЮМН ЮЯХЛОґРНґРХВЕЯЙХ НОРХґЛЮКЭМНЕ
ЦПСООХПНБЮМХЕ. йЮЙ БХДХЛ ОН ГМЮВЕМХЪЛ ЯРЮРХЯРХЙ Х ЯННРґБЕРґЯРБСЧЫХЛ
БЕПНЪРМНЯРЪЛ, ЯНЦКЮЯХЕ ОН БЯЕЛ ЙПХРЕПХЪЛ НВЕМЭ УНПНЬЕЕ.
оХПЯНМЮ ХЯОНКЭґГНБЮМН ЮЯХЛОґРНґРХВЕЯЙХ НОРХґЛЮКЭМНЕ
ЦПСООХПНБЮМХЕ. йЮЙ БХДХЛ ОН ГМЮВЕМХЪЛ ЯРЮРХЯРХЙ Х ЯННРґБЕРґЯРБСЧЫХЛ
БЕПНЪРМНЯРЪЛ, ЯНЦКЮЯХЕ ОН БЯЕЛ ЙПХРЕПХЪЛ НВЕМЭ УНПНЬЕЕ.
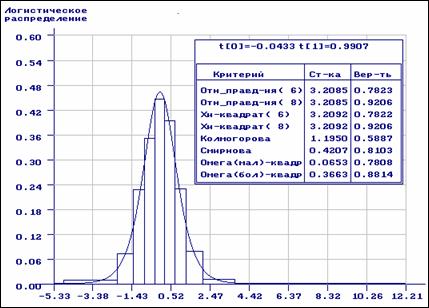
пХЯ. 3. пЕГСКЭРЮРШ ЯРЮРХЯРХВЕЯЙНЦН ЮМЮКХГЮ ДКЪ КНЦХЯРХВЕЯЙНЦН ПЮЯОПЕДЕКЕМХЪ
дНОСЯРХЛ, С МЮЯ БНГМХЙКЮ ОНРПЕАМНЯРЭ НОХЯЮРЭ ДЮММСЧ БШАНПЙС Я ОНЛНЫЭЧ
МНПЛЮКЭМНЦН ПЮЯОПЕДЕКЕМХЪ. мЮ ПХЯ. 4 ОПЕДЯРЮБКЕМШ ПЕГСКЭРЮРШ БШПЮБґМХБЮМХЪ Б
ЯННРБЕРЯРБХХ Я МНПЛЮКЭМШЛ ГЮЙНМНЛ. мЮИДЕММШЕ нло ОЮПЮґЛЕРПНБ МНПЛЮКЭМНЦН
ПЮЯОПЕДЕКЕМХЪ ![]() ,
, ![]() .
оПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ ОН ЙПХРЕПХЪЛ НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ Х
.
оПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ ОН ЙПХРЕПХЪЛ НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ Х ![]() оХПЯНМЮ ХЯОНКЭГНБЮКНЯЭ ПЮБМНБЕПНЪРМНЕ
ЦПСООХПНБЮМХЕ. еЯКХ НАПЮґРХЛ БМХЛЮМХЕ МЮ ПЕГСКЭРЮРШ ОПНБЕПЙХ ЦХОНРЕГ Н
ЯНЦКЮЯХХ, РН СБХДХЛ, ВРН ОПХ СПНБМЕ ГМЮВХЛНЯРХ
оХПЯНМЮ ХЯОНКЭГНБЮКНЯЭ ПЮБМНБЕПНЪРМНЕ
ЦПСООХПНБЮМХЕ. еЯКХ НАПЮґРХЛ БМХЛЮМХЕ МЮ ПЕГСКЭРЮРШ ОПНБЕПЙХ ЦХОНРЕГ Н
ЯНЦКЮЯХХ, РН СБХДХЛ, ВРН ОПХ СПНБМЕ ГМЮВХЛНЯРХ ![]() С МЮЯ МЕР НЯМНБЮМХИ НРЙКНМЪРЭ ЦХОНРЕГС Н МНПґЛЮКЭМНЯРХ
ОН ЙПХРЕПХЪЛ
С МЮЯ МЕР НЯМНБЮМХИ НРЙКНМЪРЭ ЦХОНРЕГС Н МНПґЛЮКЭМНЯРХ
ОН ЙПХРЕПХЪЛ ![]() оХПЯНМЮ Х НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ.
оХПЯНМЮ Х НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ.
нло ОНДБЕПФЕМШ БКХЪМХЧ ЦПСАШУ НЬХАНЙ Х НРЙКНМЕМХИ НР БХДЮ ОПЕДОНКЮЦЮЕЛНЦН
ПЮЯОПЕДЕКЕМХЪ. рЮЙ ЙЮЙ БШАНПЙЮ ЛНДЕґКХґПНБЮКЮЯЭ Б ЯННРґБЕРЯРБХХ Я КНЦХЯРХВЕЯЙХЛ ПЮЯОПЕДЕКЕМХЕЛ, РН, ЕЯРЕЯРБЕММН, ЩРН ОНБКХЪКН
МЮ НЖЕМЙХ ОЮПЮЛЕРПНБ МНПЛЮКЭМНЦН ПЮЯОПЕДЕКЕМХЪ. мЮ ПХЯ. 5. ОПЕДґЯРЮБКЕМШ
ЮМЮКНЦХВМШЕ ПЕГСКЭРЮРШ, МН Б ДЮММНЛ ЯКСВЮЕ АШКХ МЮИДЕМШ ПНАЮЯРМШЕ нло
ОЮПЮЛЕРПНБ ОН ЦПСООХПНБЮММШЛ ДЮММШЛ. х ОПХ НЖЕґМХБЮМХХ, Х ОПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ
БШАНПЙЮ ПЮГАХБЮКЮЯЭ МЮ ПЮБМНБЕПНЪРМШЕ ХМРЕПБЮКШ. нло ОЮПЮґЛЕРПНБ МНПЛЮКЭМНЦН
ПЮЯОПЕДЕКЕМХЪ ОН ЦПСООХПНґБЮММШЛ ДЮММШЛ ![]() ,
, ![]() . йЮЙ БХДХЛ, ДНЯРЮРНВМН УНПНЬЕЕ ЯНЦКЮЯХЕ: ЕЯКХ СПНБЕМЭ
ГМЮВХЛНЯРХ
. йЮЙ БХДХЛ, ДНЯРЮРНВМН УНПНЬЕЕ ЯНЦКЮЯХЕ: ЕЯКХ СПНБЕМЭ
ГМЮВХЛНЯРХ ![]() , РН ОН БЯЕЛ ЙПХґРЕПХЪЛ, ЙПНЛЕ
, РН ОН БЯЕЛ ЙПХґРЕПХЪЛ, ЙПНЛЕ ![]() лХГЕЯЮ, ЦХОНРЕГЮ Н
ЯНЦКЮЯХХ АСДЕР ОПХМЪРЮ! щЛОХПХВЕЯЙЮЪ Х ОНКСВЕММЮЪ РЕНґПЕРХВЕЯЙЮЪ ТСМЙЖХЪ
ПЮЯОПЕДЕКЕМХЪ МНПЛЮКЭМНЦН ГЮЙНМЮ БХГСЮКЭМН ХЛЕґЧР МЕЙНРНПНЕ ПЮЯУНФДЕМХЕ МЮ
УБНЯРЮУ, МН Я РНВЙХ ГПЕМХЪ ОПЮЙРХВЕЯЙХ БЯЕУ ХЯОНКЭґГСЕЛШУ ЙПХРЕПХЕБ ЩРН
ПЮЯУНФДЕМХЕ МЕГМЮВХЛН.
лХГЕЯЮ, ЦХОНРЕГЮ Н
ЯНЦКЮЯХХ АСДЕР ОПХМЪРЮ! щЛОХПХВЕЯЙЮЪ Х ОНКСВЕММЮЪ РЕНґПЕРХВЕЯЙЮЪ ТСМЙЖХЪ
ПЮЯОПЕДЕКЕМХЪ МНПЛЮКЭМНЦН ГЮЙНМЮ БХГСЮКЭМН ХЛЕґЧР МЕЙНРНПНЕ ПЮЯУНФДЕМХЕ МЮ
УБНЯРЮУ, МН Я РНВЙХ ГПЕМХЪ ОПЮЙРХВЕЯЙХ БЯЕУ ХЯОНКЭґГСЕЛШУ ЙПХРЕПХЕБ ЩРН
ПЮЯУНФДЕМХЕ МЕГМЮВХЛН.
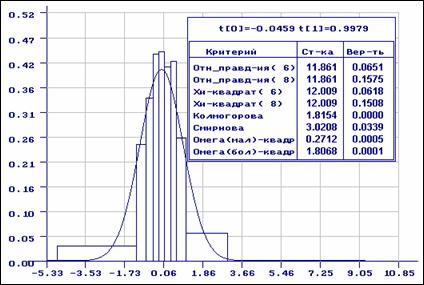
пХЯ. 4. бШПЮБМХБЮМХЕ Б ЯННРБЕРЯРБХХ Я МНПЛЮКЭМШЛ ГЮЙНМНЛ нло МЮИДЕМШ ОН МЕЦПСООХПНБЮММШЛ ДЮММШЛ; ОПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ ХЯОНКЭГНБЮМН ПЮБМНБЕПНЪРМНЕ ЦПСООХПНБЮМХЕ
пЕГСКЭРЮРШ ЯРЮРХЯРХВЕЯЙНЦН ЮМЮКХГЮ, ОПЕДЯРЮБКЕММШЕ МЮ ПХЯ. 6, НРКХВЮЧРЯЪ НР
ОПЕДШДСЫЕЦН ЯКСВЮЪ РЕЛ, ВРН Б ЙПХРЕПХЪУ ЯНЦКЮЯХЪ НРМНґЬЕМХЪ ОПЮБДНОНДНАХЪ Х ![]() оХПЯНМЮ ХЯОНКЭГНБЮКНЯЭ ЮЯХЛОРНРХВЕЯЙХ НОРХґЛЮКЭМНЕ
ЦПСООХПНБЮМХЕ. яПЮБМХРЕ ГМЮВЕМХЪ ЯРЮРХЯРХЙ НРМНЬЕМХЪ ОПЮБДНґОНДНАХЪ Х
оХПЯНМЮ ХЯОНКЭГНБЮКНЯЭ ЮЯХЛОРНРХВЕЯЙХ НОРХґЛЮКЭМНЕ
ЦПСООХПНБЮМХЕ. яПЮБМХРЕ ГМЮВЕМХЪ ЯРЮРХЯРХЙ НРМНЬЕМХЪ ОПЮБДНґОНДНАХЪ Х ![]() оХПЯНМЮ Я ХУ ГМЮВЕМХЪЛХ, ОПЕДЯРЮБКЕММШЛХ МЮ ПХЯ.
5. цХОНРЕГЮ Н ЯНЦКЮЯХХ Б ДЮММНЛ ЯКСВЮЕ АСДЕР НРЙКНМЪРЭЯЪ ОПХ
оХПЯНМЮ Я ХУ ГМЮВЕМХЪЛХ, ОПЕДЯРЮБКЕММШЛХ МЮ ПХЯ.
5. цХОНРЕГЮ Н ЯНЦКЮЯХХ Б ДЮММНЛ ЯКСВЮЕ АСДЕР НРЙКНМЪРЭЯЪ ОПХ
![]() ОН ЙПХРЕПХЧ НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ Х ОПХ
ОН ЙПХРЕПХЧ НРМНЬЕМХЪ ОПЮБДНОНДНАХЪ Х ОПХ ![]() ОН ЙПХРЕПХЧ
ОН ЙПХРЕПХЧ ![]() оХПЯНМЮ.
оХПЯНМЮ.
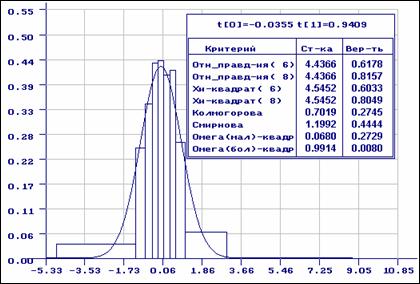
пХЯ. 5. бШПЮБМХБЮМХЕ Б ЯННРБЕРЯРБХХ Я МНПЛЮКЭМШЛ ГЮЙНМНЛ:
нло МЮИДЕМШ ОН ЦПСООХПНБЮММШЛ ДЮММШЛ; ОПХ НЖЕМХБЮМХХ
Х ОПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ ХЯОНКЭГНБЮМН ПЮБМНБЕПНЪРМНЕ
ЦПСООХПНБЮМХЕ
хГ ОПХБЕДЕММШУ ОПХЛЕПНБ Х БЯЕЦН БШЬЕЯЙЮГЮММНЦН ДНКФМН АШРЭ
НВЕБХДМН, ВРН ОПХЛЕМЕМХЕ ЮЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЦН ЦПСОґОХПНБЮМХЪ Б ЙПХРЕПХЪУ
ЯНЦКЮЯХЪ ЯМХФЮЕР ПХЯЙ МЕНАНЯМНБЮММНЦН ОПХґМЪРХЪ ЦХОНРЕГ Н ЯНЦКЮЯХХ. еЯКХ
МЮЯ ДЕИЯРБХґРЕКЭМН ХМРЕПЕЯСЕР, МЮЯЙНКЭЙН ЯХКЭМН НРКХВЮґЕРЯЪ БШАНПЙЮ НР
ОПЕДОНКЮЦЮЕЛНЦН ПЮЯОПЕДЕКЕМХЪ, ЯКЕДСЕР ОПХЛЕМЪРЭ ЙПХґРЕПХґХ НРМНґЬЕМХЪ ОПЮБДНґОНґДНАХЪ
Х ![]() оХПЯНМЮ Я ХЯОНКЭГНБЮМХЕЛ ЮЯХЛОРНРХґВЕЯЙХ НОРХЛЮКЭґМНЦН
ЦПСООХПНБЮМХЪ, ВРН ЦЮПЮМРХПСЕР ХУ ЛЮЙЯХґЛЮКЭМСЧ ЛНЫМНЯРЭ ОПХ ПЮЯОНГМЮБЮМХХ
АКХГЙХУ ЦХОНРЕГ.
оХПЯНМЮ Я ХЯОНКЭГНБЮМХЕЛ ЮЯХЛОРНРХґВЕЯЙХ НОРХЛЮКЭґМНЦН
ЦПСООХПНБЮМХЪ, ВРН ЦЮПЮМРХПСЕР ХУ ЛЮЙЯХґЛЮКЭМСЧ ЛНЫМНЯРЭ ОПХ ПЮЯОНГМЮБЮМХХ
АКХГЙХУ ЦХОНРЕГ.
б ПЮЯЯЛНРПЕММШУ МЮ ПХЯ. 4-6 ОПХЛЕПЮУ ОПХ ХЯОНКЭГНБЮМХХ ЙПХРЕґПХЕБ РХОЮ
йНКЛНЦНПНґБЮ, яЛХПМНБЮ, ![]() Х
Х
![]() лХГЕЯЮ ОПХ БШВХЯКЕМХХ
БЕПНЪРґМНЯРХ БХДЮ
лХГЕЯЮ ОПХ БШВХЯКЕМХХ
БЕПНЪРґМНЯРХ БХДЮ ![]() СВХРШБЮКЯЪ ТЮЙР НЖЕМХБЮМХЪ ОН БШАНПЙЕ ОЮПЮЛЕРґПНБ
ПЮЯОПЕДЕКЕМХЪ. хГБЕЯРМН, ВРН Б ЩРНЛ ЯКСВЮЕ ОПЕДЕКЭМШЕ ПЮЯОПЕДЕКЕМХЪ ЯРЮРХЯРХЙ
ЩРХУ ЙПХРЕПХЕБ ГЮґБХЯЪР ЙЮЙ НР БХДЮ ПЮЯЯЛЮРПХБЮЕЛНЦН ГЮЙНМЮ, РЮЙ Х НР ВХЯКЮ
НЖЕМЕММШУ ОЮПЮґЛЕРПНБ. хЯЙНЛШЕ БЕПНЪРМНЯРХ БШВХЯКЪКХЯЭ Б ЯННРБЕРЯРБХХ Я
ЛНДЕКЪЛХ ОПЕДЕКЭМШУ ПЮЯОПЕДЕКЕМХИ ЯРЮРХЯРХЙ, ОНКСВЕМґМШЛХ Б [9].
СВХРШБЮКЯЪ ТЮЙР НЖЕМХБЮМХЪ ОН БШАНПЙЕ ОЮПЮЛЕРґПНБ
ПЮЯОПЕДЕКЕМХЪ. хГБЕЯРМН, ВРН Б ЩРНЛ ЯКСВЮЕ ОПЕДЕКЭМШЕ ПЮЯОПЕДЕКЕМХЪ ЯРЮРХЯРХЙ
ЩРХУ ЙПХРЕПХЕБ ГЮґБХЯЪР ЙЮЙ НР БХДЮ ПЮЯЯЛЮРПХБЮЕЛНЦН ГЮЙНМЮ, РЮЙ Х НР ВХЯКЮ
НЖЕМЕММШУ ОЮПЮґЛЕРПНБ. хЯЙНЛШЕ БЕПНЪРМНЯРХ БШВХЯКЪКХЯЭ Б ЯННРБЕРЯРБХХ Я
ЛНДЕКЪЛХ ОПЕДЕКЭМШУ ПЮЯОПЕДЕКЕМХИ ЯРЮРХЯРХЙ, ОНКСВЕМґМШЛХ Б [9].
бЯЕ СОНЛХМЮЕЛШЕ Б ДЮММНИ ПЮАНРЕ ЙПХРЕПХХ ХЯОНКЭґГСЧР ПЮГКХВМШЕ ЛЕПШ АКХГНЯРХ ПЮЯОПЕДЕКЕМХИ, ОН ПЮГМНЛС СКЮБКХБЮЧР ПЮГКХВМШЕ НРґЙКНМЕМХЪ. оНЩРНЛС ДКЪ МЮДЕФМНЯРХ ЯРЮРХЯРХВЕЯЙХУ БШБНДНБ МЕ ЯКЕДСЕР НЯРЮМЮБКХБЮРЭЯЪ МЮ ОПХЛЕМЕМХХ ЙЮЙНЦН-РН НДМНЦН ЙПХґРЕПХЪ.
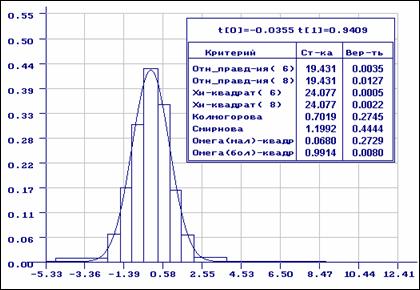
пХЯ. 6. бШПЮБМХБЮМХЕ Б ЯННРБЕРЯРБХХ Я МНПЛЮКЭМШЛ ГЮЙНМНЛ: нло МЮИДЕМШ ОН ЦПСООХПНБЮММШЛ ДЮММШЛ; ОПХ ОПНБЕПЙЕ ЯНЦКЮЯХЪ ХЯОНКЭГНБЮМН ЮЯХЛОРНРХВЕЯЙХ НОРХЛЮКЭМНЕ ЦПСООХПНБЮМХЕ
дНЯРЮРНВМН ВЮЯРН ХЯОНКЭГСЕЛШЕ ЙПХґРЕПХХ МЕ ОНГБНКЪЧР НРґЙКНґМХРЭ ЦХОНРЕГС Н ЯНЦКЮЯХХ Я НДМХЛ ПЮЯОПЕДЕґКЕМХЕЛ, Я ДПСЦХЛ, Я РПЕРЭХЛ ... нЯНАЕММН ЩРН УЮПЮЙРЕПМН ДКЪ НЦПЮМХВЕММШУ НАЗ╦ЛНБ БШАНПНЙ, ГЮВЮЯРСЧ БЯРПЕВЮЧЫХУЯЪ МЮ ОПЮЙРХЙЕ. еЯКХ ЛШ ЯРПЕЛХЛЯЪ ОНДНАПЮРЭ ЛНДЕКЭ, ЙНґРНПЮЪ МЮХАНКЕЕ УНПНЬН НОХЯШБЮЕР БШАНПНВМШЕ МЮАКЧДЕМХЪ, МЕКЭГЪ ДНБЕґПЪРЭ БШБНДЮЛ РХОЮ ⌠Я СПНБґМЕЛ ГМЮВХЛНЯРХ РЮЙХЛ-РН ЦХОНРЕГЮ Н ЯНЦКЮЯХХ Я МНПЛЮКЭМШЛ ПЮЯОПЕґДЕКЕМХЕЛ МЕ НРБЕПЦЮЕРЯЪ■, РЮЙ ЙЮЙ МЮБЕПМЪЙЮ Я АНКЭЬХЛ НЯМНґБЮМХЕЛ МЕ АСДЕР НРБЕПґЦЮРЭЯЪ ЦХОНРЕГЮ Н ЯНЦКЮЯХХ Х Я ДПСЦХЛХ ПЮЯґОПЕДЕґКЕМХЪЛХ.
1. йЕМДЮКК л., яРЭЧЮПР ю. яРЮРХЯРХВЕЯЙХЕ БШБНДШ Х ЯБЪГХ. - л.: мЮСЙЮ, 1973. - 900 Я.
2. йНЙЯ д., уХМЙКХ д. рЕНПЕРХВЕЯЙЮЪ ЯРЮРХЯРХЙЮ. - л.: лХП, 1978. - 560 Я.
3. пЮН. я.п. кХМЕИМШЕ ЯРЮРХЯРХВЕЯЙХЕ ЛЕРНДШ Х ХУ ОПХЛЕМЕМХЪ. - л.: мЮСЙЮ, 1968. - 548 Я.
4. дЕМХЯНБ б.х., кЕЛЕЬЙН а.ч. нОРХЛЮКЭМНЕ ЦПСООХПНБЮМХЕ ОПХ НАґПЮґАНРЙЕ ЩЙЯОЕПХЛЕМРЮКЭМШУ ДЮММШУ // хГЛЕПХРЕКЭМШЕ ХМТНПЛЮЖХґНММШЕ ЯХЯРЕЛШ. - мНБНЯХАХПЯЙ, 1979. - я. 5-14.
5. дЕМХЯНБ б.х., кЕЛЕЬЙН а.ч., жНИ е.а. нОРХЛЮКЭМНЕ ЦПСООХґПНБЮМХЕ, НЖЕМґЙЮ ОЮПЮЛЕРПНБ Х ОКЮМХПНБЮМХЕ ПЕЦПЕЯЯХНММШУ ЩЙЯОЕПХґЛЕМРНБ. б 2-У В. / мНБНЯХА. ЦНЯ. РЕУМ. СМ-Р. - мНБНґЯХАХПЯЙ, 1993. - 347 Я.
6. кЕЛЕЬЙН а.ч. яРЮРХЯРХВЕЯЙХИ ЮМЮКХГ НДМНЛЕПМШУ МЮАКЧДЕМХИ ЯКСґВЮИґґМШУ БЕКХВХМ: оПНЦПЮЛЛМЮЪ ЯХЯРЕЛЮ. - мНБНЯХґАХПЯЙ: хГД-БН мцрс, 1995. - 125 Я.
7. дЕМХЯНБ б.х., гЮВЕОЮ ц.ц., кЕЛЕЬЙН а.ч. нА ЮЯХЛОРНРХВЕЯЙХ НОРХґЛЮКЭМНЛ ЦПСООХПНБЮМХХ ОПХ НЖЕМХБЮМХХ НЯМНБМНЦН ОЮПЮЛЕРПЮ ЦЮЛЛЮ-ПЮЯґОПЕДЕКЕМХЪ ОН ЦПСООХПНБЮММШЛ ДЮММШЛ // оПХЛЕМЕМХЕ щбл Б НОРХґЛЮКЭМНЛ ОКЮМХПНБЮМХХ Х ОПНЕЙРХПНБЮМХХ. - мНБНЯХґАХПЯЙ, 1974. - я. 50-53.
8. кЕЛЕЬЙН а.ч. й БНОПНЯС ПЕЬЕМХЪ ГЮДЮВХ ЮЯХЛОРНРХВЕЯЙХ НОРХґЛЮКЭґМНЦН ЦПСООХПНБЮМХЪ ДЮММШУ ОПХ НАПЮАНРЙЕ МЮАКЧДЕМХИ, ОНДВХґМЪЧЫХУЯЪ АЕРЮ-ПЮЯОПЕДЕКЕМХЧ // лЮЬХММШЕ ЛЕРНДШ НОРХЛХГЮЖХХ, ЛНДЕКХґПНБЮґМХЪ Х ОКЮМХПНБЮМХЪ ЩЙЯОЕПХЛЕМРЮ. - мНБНЯХАХПЯЙ, 1988. - я. 134-138.
9.
кЕЛЕЬЙН а.ч., оНЯРНБЮКНБ я.м. й БНОПНЯС Н
ПЮЯОПЕДЕКЕМХЪУ ЯРЮґРХЯРХЙ МЕОЮПЮЛЕРПХВЕЯЙХУ ЙПХРЕПХЕБ ЯНЦКЮЯХЪ // яА. МЮСВМШУ
РПСґДНБ мцрс. - 1997. - ╧ 1(6). - я. 23-32.