См. также: Прикладная
математическая статистика (материалы к семинарам)
Заводская лаборатория. Диагностика материалов. 2001. Т. 67. - № 3. - С. 52-58.
УДК 519.2
О РАСПРЕДЕЛЕНИЯХ СТАТИСТИКИ И МОЩНОСТИ КРИТЕРИЯ ТИПА ![]() НИКУЛИНА
НИКУЛИНА
Б.Ю. Лемешко, С.Н. Постовалов, Е.В. Чимитова
С использованием критериев согласия могут проверяться простые гипотезы вида ![]() :
: ![]() ,
где
,
где ![]() – функция распределения вероятностей, с которой
проверяется согласие наблюдаемой выборки независимых одинаково распределенных
величин
– функция распределения вероятностей, с которой
проверяется согласие наблюдаемой выборки независимых одинаково распределенных
величин ![]() , а
, а ![]() –
известное значение параметра (скалярного или векторного), и сложные гипотезы
–
известное значение параметра (скалярного или векторного), и сложные гипотезы ![]() :
: ![]() ,
где
,
где ![]() – пространство параметров. В процессе проверки
сложной гипотезы оценка параметра
– пространство параметров. В процессе проверки
сложной гипотезы оценка параметра ![]() вычисляется
по этой же самой выборке. Если оценка
вычисляется
по этой же самой выборке. Если оценка ![]() вычислена
по другой выборке, то гипотеза простая.
вычислена
по другой выборке, то гипотеза простая.
При использовании критериев согласия типа ![]() область
определения случайной величины разбивается на
область
определения случайной величины разбивается на ![]() интервалов граничными точками
интервалов граничными точками
![]() .
.
Статистика ![]() Пирсона вычисляется в соответствии с
соотношением
Пирсона вычисляется в соответствии с
соотношением
![]() ,
(1)
,
(1)
где
![]() – количество наблюдений, попавших в интервал,
– количество наблюдений, попавших в интервал, ![]() – вероятность попадания наблюдения в
– вероятность попадания наблюдения в ![]() -й
интервал,
-й
интервал, ![]() ,
, ![]() .
При справедливой простой гипотезе
.
При справедливой простой гипотезе ![]() предельное
распределение статистики
предельное
распределение статистики ![]() есть
есть
![]() -распределение с числом степеней свободы
-распределение с числом степеней свободы ![]() . Если по выборке оценивалось
. Если по выборке оценивалось ![]() параметров закона в результате минимизации статистики
параметров закона в результате минимизации статистики
![]() , статистика подчиняется
, статистика подчиняется ![]() -распределению с
-распределению с ![]() степенями
свободы. При справедливой альтернативной гипотезе
степенями
свободы. При справедливой альтернативной гипотезе ![]() предельное распределение
предельное распределение ![]() представляет собой нецентральное
представляет собой нецентральное ![]() -распределение с тем же числом степеней свободы и
параметром нецентральности
-распределение с тем же числом степеней свободы и
параметром нецентральности
![]() .
(2)
.
(2)
В случае проверки сложных гипотез и оценивании по выборке параметров наблюдаемого
закона использование в качестве предельных ![]() -распределений справедливо лишь при определении
оценок минимизацией статистики
-распределений справедливо лишь при определении
оценок минимизацией статистики ![]() [1]
или при вычислении по сгруппированным данным оценок максимального
правдоподобия (ОМП).
[1]
или при вычислении по сгруппированным данным оценок максимального
правдоподобия (ОМП).
Если при проверке такой сложной гипотезы используются
ОМП по негруппированным данным, то эта же статистика
распределена в пределе как сумма независимых слагаемых ![]() , где
, где ![]() -
стандартные нормальные случайные величины, независимые между собой и с
-
стандартные нормальные случайные величины, независимые между собой и с ![]() . Величины
. Величины ![]() –
некоторые числа между 0 и 1 [2-3], представляющие собой корни уравнения
–
некоторые числа между 0 и 1 [2-3], представляющие собой корни уравнения
![]() ,
(3)
,
(3)
где
![]() – информационная матрица Фишера по негруппированным данным, соответствующая одному
наблюдению,
– информационная матрица Фишера по негруппированным данным, соответствующая одному
наблюдению,
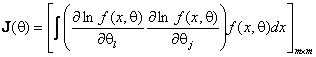 ,
(4)
,
(4)
а ![]() – по группированным
– по группированным
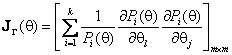 .
(5)
.
(5)
В работе [4] распределения ![]() этой
статистики при проверке сложных гипотез были исследованы методами компьютерного
моделирования в зависимости от способа группирования наблюдений (от способа
разбиения области определения на интервалы). Было показано, что при использовании
асимптотически оптимального группирования, при котором минимизируются потери в
информации Фишера [5-8], например, максимизируется
определитель матрицы
этой
статистики при проверке сложных гипотез были исследованы методами компьютерного
моделирования в зависимости от способа группирования наблюдений (от способа
разбиения области определения на интервалы). Было показано, что при использовании
асимптотически оптимального группирования, при котором минимизируются потери в
информации Фишера [5-8], например, максимизируется
определитель матрицы ![]() ,
зависящей от граничных точек интервалов, распределения
,
зависящей от граничных точек интервалов, распределения ![]() в области больших значений статистики настолько
близки к соответствующим
в области больших значений статистики настолько
близки к соответствующим ![]() -распределениям,
что последними можно пользоваться без опасения совершить большую ошибку при
вычислении вероятности вида
-распределениям,
что последними можно пользоваться без опасения совершить большую ошибку при
вычислении вероятности вида ![]() ,
где
,
где ![]() - значение статистики, вычисленное по выборке.
Однако в общем случае условные распределения статистики
- значение статистики, вычисленное по выборке.
Однако в общем случае условные распределения статистики ![]() существенно отличаются от
существенно отличаются от ![]() -распределений. И для корректного применения критерия
согласия желательно более точное знание предельного распределения статистики.
-распределений. И для корректного применения критерия
согласия желательно более точное знание предельного распределения статистики.
В работах [9-12] Никулиным предлагается такое
видоизменение стандартной статистики ![]() ,
при котором предельное
распределение есть обычное распределение
,
при котором предельное
распределение есть обычное распределение ![]() (количество
степеней свободы не зависит от числа оцениваемых параметров). Неизвестные
параметры распределения
(количество
степеней свободы не зависит от числа оцениваемых параметров). Неизвестные
параметры распределения ![]() в
этом случае должны оцениваться по негруппированным
данным методом максимального правдоподобия. При этом вектор вероятностей
попадания в интервал
в
этом случае должны оцениваться по негруппированным
данным методом максимального правдоподобия. При этом вектор вероятностей
попадания в интервал ![]() предполагается
заданным и граничные точки интервалов определяются
соотношениями
предполагается
заданным и граничные точки интервалов определяются
соотношениями ![]() ,
, ![]() .
.
Предложенная статистика отличается от
![]() только при сложных гипотезах и имеет вид [10]
только при сложных гипотезах и имеет вид [10]
![]() ,
(6)
,
(6)
где
![]() вычисляется в соответствии с (1). Элементы и
размерность матрицы
вычисляется в соответствии с (1). Элементы и
размерность матрицы
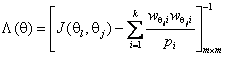 (7)
(7)
определяются
оцениваемыми компонентами вектора параметров ![]() ,
, ![]() -
элементы информационной матрицы
-
элементы информационной матрицы ![]() ,
, ![]() - элементы вектора
- элементы вектора ![]() , величины
, величины ![]() определяются
соотношением
определяются
соотношением
![]() .
(8)
.
(8)
Несложно показать, что для законов ![]() ,
определяемых только двумя параметрами сдвига и масштаба, справедливо
соотношение
,
определяемых только двумя параметрами сдвига и масштаба, справедливо
соотношение
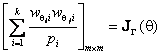 (9)
(9)
и, следовательно,
![]() .
(10)
.
(10)
Действительно, для законов с параметром сдвига ![]() и масштаба
и масштаба ![]() с
функцией распределения
с
функцией распределения ![]() и
плотностью
и
плотностью ![]() элементы информационной матрицы
элементы информационной матрицы ![]() имеют вид:
имеют вид:
![]() ,
,
![]() ,
,
![]() ,
,
где
![]() . Тогда нетрудно заметить, что
. Тогда нетрудно заметить, что
![]() ,
,
![]() .
.
С момента публикации работ [9-10] прошло более 25 лет, но, не считая работ
самого Никулина, нам не известны публикации других авторов, посвященные этой
статистике, и, тем более, какие-либо упоминания о результатах использования
статистики ![]() в приложениях.
в приложениях.
Целью настоящей работы явилось стремление проверить, насколько хорошо
распределение статистики ![]() при
справедливой нулевой гипотезе
при
справедливой нулевой гипотезе ![]() соответствует
распределению
соответствует
распределению ![]() , а, во-вторых, сравнить мощность предложенного
Никулиным критерия с мощностью критерия
, а, во-вторых, сравнить мощность предложенного
Никулиным критерия с мощностью критерия ![]() Пирсона.
Основанием для проведения исследований послужили следующие соображения. С одной
стороны, как уже говорилось, при вычислении ОМП по негруппированным
наблюдениям, и использовании асимптотически оптимального группирования
распределения
Пирсона.
Основанием для проведения исследований послужили следующие соображения. С одной
стороны, как уже говорилось, при вычислении ОМП по негруппированным
наблюдениям, и использовании асимптотически оптимального группирования
распределения ![]() в области больших значений статистики достаточно
близки к
в области больших значений статистики достаточно
близки к ![]() -распределениям [4]. С другой стороны, очевидно, что
вычисление статистики
-распределениям [4]. С другой стороны, очевидно, что
вычисление статистики ![]() сопряжено
с несколько большими вычислительными (и аналитическими) затратами.
Следовательно, для того, чтобы рекомендовать её применение, необходимо указать
конкретные преимущества, связанные с этой статистикой и показывающие, что
использование статистики
сопряжено
с несколько большими вычислительными (и аналитическими) затратами.
Следовательно, для того, чтобы рекомендовать её применение, необходимо указать
конкретные преимущества, связанные с этой статистикой и показывающие, что
использование статистики ![]() не
хуже в каком-то смысле. Например, что при близких альтернативах, как показано
в [9,11,12], мощность критерия Никулина действительно не меньше мощности
критерия Пирсона.
не
хуже в каком-то смысле. Например, что при близких альтернативах, как показано
в [9,11,12], мощность критерия Никулина действительно не меньше мощности
критерия Пирсона.
В данной работе, как и в [4,8,13], нами использована методика компьютерного
анализа статистических закономерностей, которая позволяет с достаточной для
практических задач точностью моделировать законы распределения исследуемых
статистик. Эмпирические функции смоделированных распределений статистик,
приводимые в статье, строились при объемах выборок статистик ![]() . Полученные результаты для наглядности иллюстрируются
на приводимых рисунках без сглаживания эмпирических распределений
аппроксимирующими зависимостями. С одной стороны это позволяет проследить
реальные закономерности, с другой – судить о точности построения
соответствующих функций распределения. Естественно, что такая методика анализа допредельных и предельных распределений статистик, как
справедливо отмечает А.И. Орлов [14], имеет свои недостатки, связанные с
ограниченной точностью построения закона распределения статистики и влиянием
качества используемого датчика псевдослучайных чисел. В нашем случае качество
датчиков, генерирующих числа в соответствии с заданными законами «наблюдаемых»
случайных величин, контролировалась с использованием программной системы [15].
По нашим оценкам отклонения смоделированного распределения от теоретического при
. Полученные результаты для наглядности иллюстрируются
на приводимых рисунках без сглаживания эмпирических распределений
аппроксимирующими зависимостями. С одной стороны это позволяет проследить
реальные закономерности, с другой – судить о точности построения
соответствующих функций распределения. Естественно, что такая методика анализа допредельных и предельных распределений статистик, как
справедливо отмечает А.И. Орлов [14], имеет свои недостатки, связанные с
ограниченной точностью построения закона распределения статистики и влиянием
качества используемого датчика псевдослучайных чисел. В нашем случае качество
датчиков, генерирующих числа в соответствии с заданными законами «наблюдаемых»
случайных величин, контролировалась с использованием программной системы [15].
По нашим оценкам отклонения смоделированного распределения от теоретического при ![]() обычно
имеют порядок
обычно
имеют порядок ![]() . Об этом же позволяет судить и степень совпадения
моделируемых распределений классических статистик с их известными предельными
законами распределения.
. Об этом же позволяет судить и степень совпадения
моделируемых распределений классических статистик с их известными предельными
законами распределения.
Как показано в [4], распределения ![]() существенно зависят от способа группирования
выборки. В частности, эти распределения заметно отличаются при разбиении
выборки на равновероятные и асимптотически оптимальные интервалы. Ещё в
большей степени способ группирования отражается на распределениях
существенно зависят от способа группирования
выборки. В частности, эти распределения заметно отличаются при разбиении
выборки на равновероятные и асимптотически оптимальные интервалы. Ещё в
большей степени способ группирования отражается на распределениях ![]() и, следовательно, на мощности критерия Пирсона:
при близких альтернативах и асимптотически оптимальном группировании его
мощность максимальна.
и, следовательно, на мощности критерия Пирсона:
при близких альтернативах и асимптотически оптимальном группировании его
мощность максимальна.
Исследование методами компьютерного моделирования распределений ![]() показало, что на эти распределения способы
группирования практически не влияют: и при равновероятном (РВГ), и при асимптотически
оптимальном (АОГ) группировании распределения
показало, что на эти распределения способы
группирования практически не влияют: и при равновероятном (РВГ), и при асимптотически
оптимальном (АОГ) группировании распределения ![]() хорошо согласуются с
хорошо согласуются с ![]() -распределением. Например, на рис. 1 показаны эмпирические
распределения
-распределением. Например, на рис. 1 показаны эмпирические
распределения ![]() при проверке гипотезы о согласии с логистическим законом
при проверке гипотезы о согласии с логистическим законом 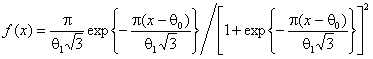 и
вычислении по выборке ОМП двух параметров этого распределения. Выборка
разбивалась на 7 интервалов. И при равновероятном
и
вычислении по выборке ОМП двух параметров этого распределения. Выборка
разбивалась на 7 интервалов. И при равновероятном ![]() и при асимптотически оптимальном группировании
и при асимптотически оптимальном группировании
![]() эмпирические распределения практически совпали с
эмпирические распределения практически совпали с
![]() -распределением. Аналогичная картина наблюдается и при
других нулевых гипотезах.
-распределением. Аналогичная картина наблюдается и при
других нулевых гипотезах.
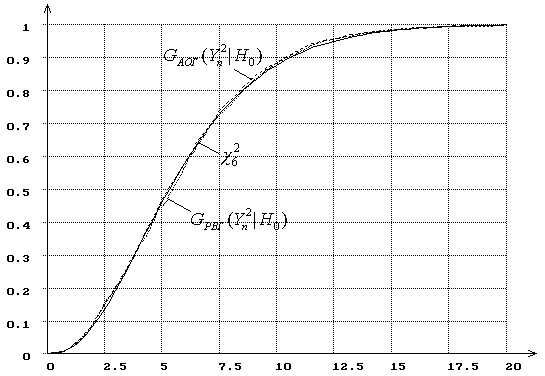
Рис.1. Распределения статистики ![]() при оценивании двух параметров логистического распределения, соответствующего верной
гипотезе
при оценивании двух параметров логистического распределения, соответствующего верной
гипотезе ![]() .
.
На предельные распределения ![]() способ группирования оказывает
заметное, но не сравнимо меньшее влияние, чем на распределения
способ группирования оказывает
заметное, но не сравнимо меньшее влияние, чем на распределения ![]() . Проведенные исследования показали,
что различия между распределениями
. Проведенные исследования показали,
что различия между распределениями ![]() и
и ![]() заметны, но не так существенны, как для
аналогичных распределений статистики
заметны, но не так существенны, как для
аналогичных распределений статистики ![]() . При этом в большинстве случаев кривая распределения
. При этом в большинстве случаев кривая распределения
![]() проходит ниже, чем
проходит ниже, чем ![]() , что, вообще говоря, указывает на
то, что, в отличие от критерия
, что, вообще говоря, указывает на
то, что, в отличие от критерия ![]() Пирсона, критерий типа
Пирсона, критерий типа ![]() Никулина несколько мощнее в случае равновероятного группирования(!). В табл. 1
приведены значения
Никулина несколько мощнее в случае равновероятного группирования(!). В табл. 1
приведены значения ![]() мощности критериев типа
мощности критериев типа ![]() Пирсона (
Пирсона (![]() ) и Никулина (
) и Никулина (![]() )
при проверке сложных гипотез с оцениванием двух параметров распределения,
соответствующего гипотезе
)
при проверке сложных гипотез с оцениванием двух параметров распределения,
соответствующего гипотезе ![]() при
уровне значимости
при
уровне значимости ![]() , объеме выборки
, объеме выборки ![]() ,
при числе интервалов группирования
,
при числе интервалов группирования ![]() .
В первом случае гипотезе
.
В первом случае гипотезе ![]() соответствовало
нормальное распределение
соответствовало
нормальное распределение 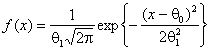 ,
а гипотезе
,
а гипотезе ![]() – логистическое. Во
втором случае – наоборот.
– логистическое. Во
втором случае – наоборот.
Таблица 1.
|
Оценивались |
|
|
||||||
|
параметры |
|
|
|
|
||||
|
|
АОГ |
РВГ |
АОГ |
РВГ |
АОГ |
РВГ |
АОГ |
РВГ |
|
Оба параметра |
0.69 |
0.71 |
0.57 |
0.53 |
0.43 |
0.47 |
0.45 |
0.23 |
|
Сдвига |
0.44 |
0.45 |
0.45 |
0.46 |
0.4 |
0.4 |
0.44 |
0.44 |
|
Масштаба |
0.64 |
0.69 |
0.61 |
0.47 |
0.5 |
0.46 |
0.5 |
0.19 |
На рис. 2-4 представлены графики распределений
статистик ![]() и
и ![]() при
справедливой нулевой гипотезе (
при
справедливой нулевой гипотезе (![]() и
и
![]() ), которая соответствует нормальному распределению,
и при верной альтернативе (
), которая соответствует нормальному распределению,
и при верной альтернативе (![]() и
и
![]() ), соответствующей логистическому
закону. Условные распределения статистик при справедливой альтернативе всюду
строились при объеме выборки
), соответствующей логистическому
закону. Условные распределения статистик при справедливой альтернативе всюду
строились при объеме выборки ![]() .
Распределения на рис. 2 соответствуют случаю, когда вычисляются ОМП двух
параметров нормального распределения, на рис. 3 – при вычислении ОМП только
параметра сдвига, а на рис. 4 – при вычислении ОМП только параметра масштаба. На рис. 2 и последующих вертикальная линия от условного
распределения при справедливой нулевой гипотезе
.
Распределения на рис. 2 соответствуют случаю, когда вычисляются ОМП двух
параметров нормального распределения, на рис. 3 – при вычислении ОМП только
параметра сдвига, а на рис. 4 – при вычислении ОМП только параметра масштаба. На рис. 2 и последующих вертикальная линия от условного
распределения при справедливой нулевой гипотезе ![]() до условного распределения,
соответствующего верной альтернативе
до условного распределения,
соответствующего верной альтернативе ![]() , позволяет ориентироваться в
значениях мощности при уровне значимости
, позволяет ориентироваться в
значениях мощности при уровне значимости ![]() : ордината её нижнего конца
определяет ошибку второго рода
: ордината её нижнего конца
определяет ошибку второго рода ![]() .
.
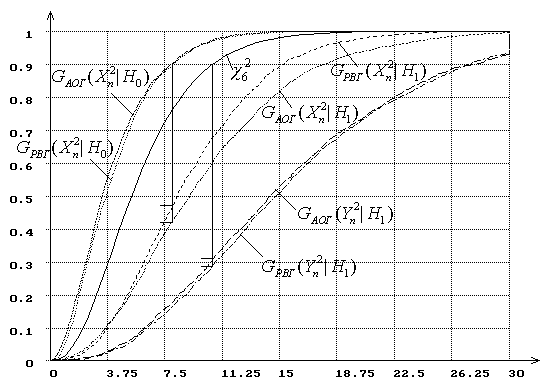
Рис. 2. Распределения
статистик ![]() и
и ![]() при
вычислении ОМП двух параметров нормального распределения (
при
вычислении ОМП двух параметров нормального распределения (![]() : нормальный закон,
: нормальный закон, ![]() : логистический).
: логистический).
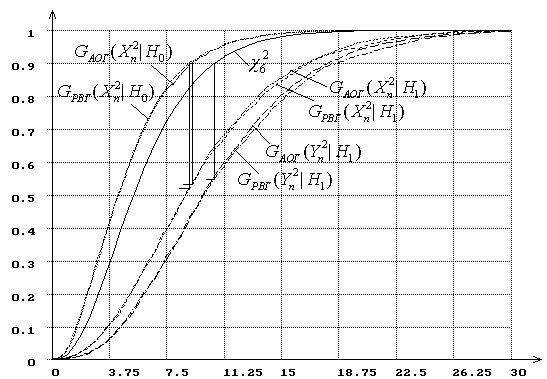
Рис. 3. Распределения
статистик ![]() и
и ![]() при
вычислении ОМП параметра сдвига нормального распределения
при
вычислении ОМП параметра сдвига нормального распределения
|
(![]() : нормальный закон,
: нормальный закон, ![]() : логистический).
: логистический).
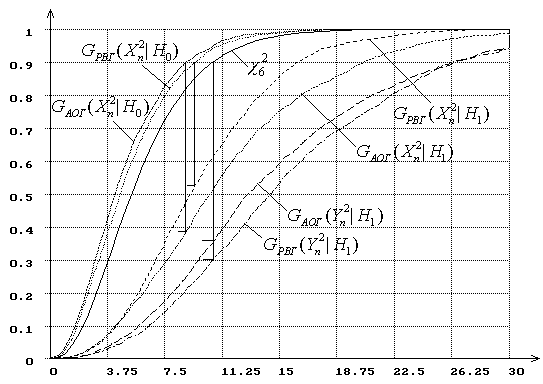
Рис. 4. Распределения статистик ![]() и
и ![]() при
вычислении ОМП параметра масштаба нормального распределения
при
вычислении ОМП параметра масштаба нормального распределения
|
(![]() :
нормальный закон,
:
нормальный закон, ![]() : логистический).
: логистический).
Как следует из результатов,
представленных в табл. 1 и на рис. 2-4, мощность критерия типа ![]() Никулина с использованием
статистики
Никулина с использованием
статистики ![]() при различении близких
гипотез, каковыми являются нормальное и логистическое
распределения, не хуже, чем в этой же ситуации (при проверке сложной гипотезы)
мощность критерия типа
при различении близких
гипотез, каковыми являются нормальное и логистическое
распределения, не хуже, чем в этой же ситуации (при проверке сложной гипотезы)
мощность критерия типа ![]() Пирсона с использованием статистики
Пирсона с использованием статистики ![]() с применением асимптотически
оптимального группирования.
Необходимо особо отметить, что группирование, при котором минимизируются
потери в информации Фишера и при котором критерий типа
с применением асимптотически
оптимального группирования.
Необходимо особо отметить, что группирование, при котором минимизируются
потери в информации Фишера и при котором критерий типа ![]() Пирсона лучше всего различает близкие гипотезы,
уже не является оптимальным в этом смысле для критерия Никулина: при
равновероятном группировании этот критерий обычно оказывается мощнее.
Пирсона лучше всего различает близкие гипотезы,
уже не является оптимальным в этом смысле для критерия Никулина: при
равновероятном группировании этот критерий обычно оказывается мощнее.
Сравним по мощности рассматриваемые критерии с
непараметрическими критериями типа Колмогорова и типа ![]() Мизеса при проверке
сложной гипотезы в полностью аналогичной ситуации: по выборке вычисляются ОМП
двух параметров нормального распределения,
Мизеса при проверке
сложной гипотезы в полностью аналогичной ситуации: по выборке вычисляются ОМП
двух параметров нормального распределения, ![]() соответствует
нормальному закону,
соответствует
нормальному закону, ![]() –
логистическому, объём выборки
–
логистическому, объём выборки ![]() .
.
На рис. 5 представлены распределения ![]() и
и ![]() статистики
типа Колмогорова, имеющей вид [16]
статистики
типа Колмогорова, имеющей вид [16]
![]() ,
,
где
![]()
![]() -
объем выборки,
-
объем выборки, ![]() - упорядоченные по возрастанию выборочные
значения,
- упорядоченные по возрастанию выборочные
значения, ![]() - функция закона распределения, согласие с
которым проверяется. А на рис. 6 – распределения
- функция закона распределения, согласие с
которым проверяется. А на рис. 6 – распределения ![]() и
и ![]() статистики
типа
статистики
типа ![]() Мизеса вида [16]
Мизеса вида [16]
![]() .
.
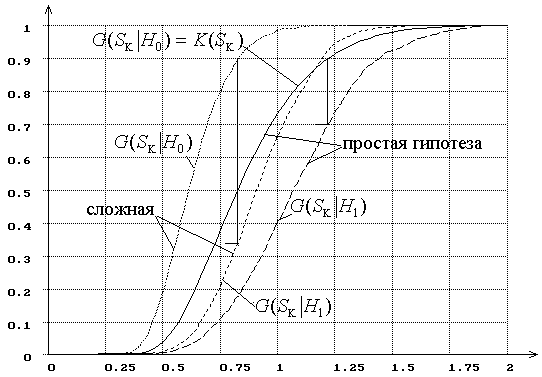
Рис.5. Распределения
статистики критерия типа Колмогорова при проверке сложной гипотезы и вычислении
ОМП двух параметров нормального распределения (![]() : нормальный закон,
: нормальный закон, ![]() : логистический) и при
проверке простой гипотезы.
: логистический) и при
проверке простой гипотезы.![]() – распределение Колмогорова.
– распределение Колмогорова.
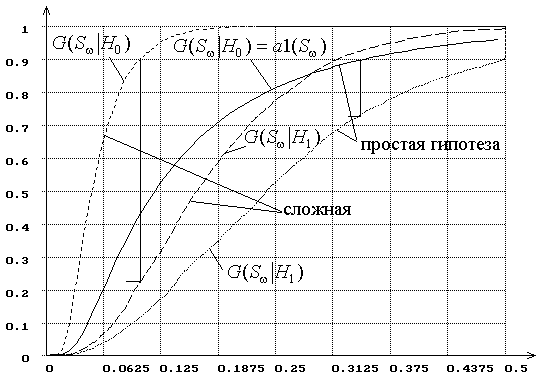
Рис. 6. Распределения
статистики критерия типа ![]() Мизеса при проверке сложной гипотезы и вычислении ОМП двух
параметров нормального распределения (
Мизеса при проверке сложной гипотезы и вычислении ОМП двух
параметров нормального распределения (![]() :
нормальный закон,
:
нормальный закон, ![]() : логистический) и при
проверке простой гипотезы.
: логистический) и при
проверке простой гипотезы. ![]() – предельное
распределение статистики при простой гипотезе.
– предельное
распределение статистики при простой гипотезе.
Мощность
критерия типа Колмогорова при уровне значимости ![]() оказывается равной 0.66 (см. рис. 5), критерия
типа
оказывается равной 0.66 (см. рис. 5), критерия
типа ![]() Мизеса – 0.775 (см.
рис.6) (сравните с 0.71 для
Мизеса – 0.775 (см.
рис.6) (сравните с 0.71 для ![]() и 0.53 для
и 0.53 для ![]() , рис. 2 и табл. 1).
, рис. 2 и табл. 1).
Если рассмотреть те же самые, но простые гипотезы ![]() и
и ![]() , то мощность этих критериев при
, то мощность этих критериев при ![]() составит величину: для
критерия Колмогорова – 0.3 (рис. 5), для критерия
составит величину: для
критерия Колмогорова – 0.3 (рис. 5), для критерия ![]() Мизеса
– 0.275 (рис. 6), для критерия
Мизеса
– 0.275 (рис. 6), для критерия ![]() Пирсона – 0.43 при равновероятном группировании
и 0.54 при асимптотически оптимальном (рис. 7).
Пирсона – 0.43 при равновероятном группировании
и 0.54 при асимптотически оптимальном (рис. 7).
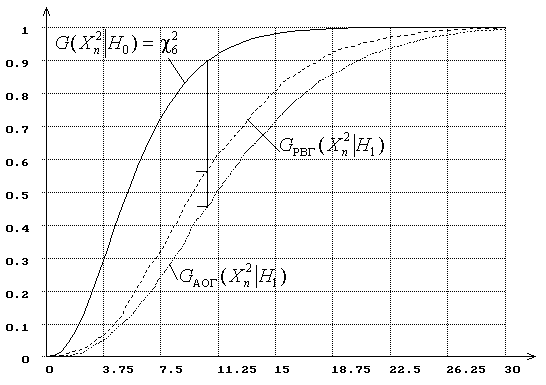
Рис.7. Распределения статистики ![]() при проверке простой гипотезы
при проверке простой гипотезы
|
(![]() :
нормальный закон,
:
нормальный закон, ![]() : логистический,
: логистический, ![]() ).
).
Применяя критерии типа ![]() Пирсона,
стараются разбить область определения случайной величины, по возможности, на
большее число интервалов. Конечно, в этом случае потери информации
уменьшаются. Но интересно, что в этом случае происходит с мощностью критерия
согласия. Об изменении мощности критерия с ростом числа
интервалов для статистики
Пирсона,
стараются разбить область определения случайной величины, по возможности, на
большее число интервалов. Конечно, в этом случае потери информации
уменьшаются. Но интересно, что в этом случае происходит с мощностью критерия
согласия. Об изменении мощности критерия с ростом числа
интервалов для статистики ![]() при проверке простой гипотезы можно судить по
рис. 8, на котором представлены распределения
при проверке простой гипотезы можно судить по
рис. 8, на котором представлены распределения ![]() и
и ![]() для рассматриваемых гипотез
для рассматриваемых гипотез ![]() и
и ![]() при числе интервалов
при числе интервалов ![]() и объёме выборки
и объёме выборки ![]() . Для
. Для ![]() на рисунке приведены
на рисунке приведены ![]() и
и ![]() . Ордината нижнего конца
соответствующей вертикальной линии определяет величину
. Ордината нижнего конца
соответствующей вертикальной линии определяет величину ![]() при уровне значимости
при уровне значимости ![]() . Как видим, в полном соответствии с
результатами работ [17,18] при увеличении числа интервалов мощность критерия падает.
. Как видим, в полном соответствии с
результатами работ [17,18] при увеличении числа интервалов мощность критерия падает.
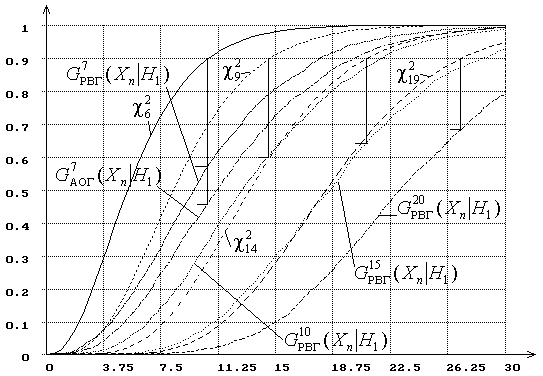
Рис.8. Распределения статистики ![]() при проверке простой гипотезы
при проверке простой гипотезы
|
(![]() : нормальный закон,
: нормальный закон, ![]() : логистический,
: логистический, ![]() ).
).
Аналогичные изменения мощности критерия для статистики ![]() в зависимости от числа интервалов при проверке
сложной гипотезы иллюстрирует рис. 9. И здесь с ростом
в зависимости от числа интервалов при проверке
сложной гипотезы иллюстрирует рис. 9. И здесь с ростом ![]() мощность критерия падает.
мощность критерия падает.
А вот мощность критерия Никулина с использованием статистики ![]() с ростом
с ростом ![]() уменьшается
существенно медленней (см. рис. 10) и она выше, чем мощность критерия
уменьшается
существенно медленней (см. рис. 10) и она выше, чем мощность критерия ![]() Пирсона.
Пирсона.
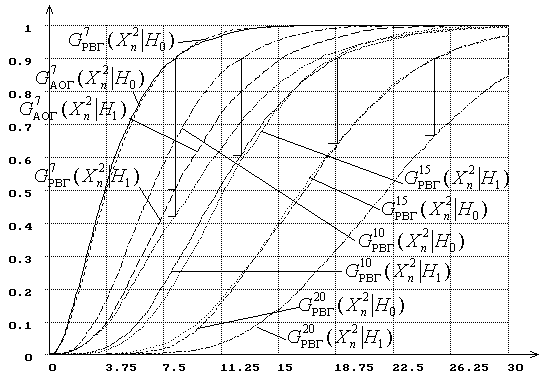
Рис.9. Распределения статистики ![]() при проверке сложной гипотезы
при проверке сложной гипотезы
|
(![]() : нормальный закон,
: нормальный закон, ![]() : логистический,
: логистический, ![]() ).
).
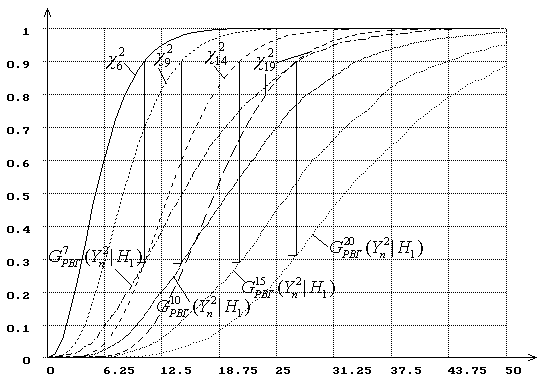
Рис.10. Распределения статистики ![]() при проверке сложной гипотезы
при проверке сложной гипотезы
|
(![]() : нормальный закон,
: нормальный закон, ![]() : логистический,
: логистический, ![]() ).
).
В табл. 2 представлены значения мощности критериев ![]() Пирсона и типа
Пирсона и типа ![]() Никулина в случае рассматриваемой пары
альтернатив (
Никулина в случае рассматриваемой пары
альтернатив (![]() : нормальный
закон,
: нормальный
закон, ![]() : логистический) при
различном числе интервалов
: логистический) при
различном числе интервалов ![]() в
случае простых и сложных гипотез. В колонке «2» приведены значения мощности
критерия
в
случае простых и сложных гипотез. В колонке «2» приведены значения мощности
критерия ![]() Пирсона при проверке простой гипотезы,
полученные по результатам моделирования. В колонке «3» приведены теоретические
значения мощности, вычисленные при условии, что
Пирсона при проверке простой гипотезы,
полученные по результатам моделирования. В колонке «3» приведены теоретические
значения мощности, вычисленные при условии, что ![]() представляет собой
представляет собой ![]() -распределение, а
-распределение, а ![]() –
соответствующее нецентральное распределение. Колонка «4» содержит значения
мощности критерия
–
соответствующее нецентральное распределение. Колонка «4» содержит значения
мощности критерия ![]() Пирсона при проверке сложной гипотезы,
полученные по результатам моделирования при использовании ОМП по негруппированным наблюдениям. В колонке «5» приведены
теоретические значения мощности критерия
Пирсона при проверке сложной гипотезы,
полученные по результатам моделирования при использовании ОМП по негруппированным наблюдениям. В колонке «5» приведены
теоретические значения мощности критерия ![]() Пирсона
при проверке сложной гипотезы, вычисленные при условии, что
Пирсона
при проверке сложной гипотезы, вычисленные при условии, что ![]() представляет собой
представляет собой ![]() -распределение (оценки параметров вычисляются при
минимизации статистики
-распределение (оценки параметров вычисляются при
минимизации статистики ![]() ),
а
),
а ![]() – соответствующее нецентральное распределение. В
колонке «6» приведены значения мощности критерия Никулина, полученные в
результате моделирования распределений статистики
– соответствующее нецентральное распределение. В
колонке «6» приведены значения мощности критерия Никулина, полученные в
результате моделирования распределений статистики ![]() , а в колонке «7» – расчетные значения мощности этой
статистики при рассматриваемой паре гипотез
, а в колонке «7» – расчетные значения мощности этой
статистики при рассматриваемой паре гипотез ![]() и
и
![]() .
.
Таблица 2.
Значения мощности критериев ![]() Пирсона и типа
Пирсона и типа ![]() Никулина
Никулина
при уровне значимости a=0.1
(![]() :
нормальный закон,
:
нормальный закон, ![]() : логистический закон)
: логистический закон)
|
|
В случае простой гипотезы |
В
случае сложной гипотезы
|
||||
|
Для статистики
|
Для статистики |
Для статистики |
||||
|
По результатам моделирования |
Теоретическая |
По результатам моделирования (при использовании ОМП) |
Теоретическая
(при использовании оценок min |
По результатам моделирования |
Теоретическая |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
6 |
0.46 |
0.449 |
0.53 |
0.526 |
0.70 |
0.742 |
|
7 |
0.43 |
0.427 |
0.49 |
0.488 |
0.71 |
0.752 |
|
8 |
0.42 |
0.409 |
0.45 |
0.459 |
0.71 |
0.757 |
|
9 |
0.38 |
0.395 |
0.43 |
0.436 |
0.71 |
0.758 |
|
10 |
0.38 |
0.383 |
0.43 |
0.418 |
0.71 |
0.757 |
|
11 |
0.37 |
0.373 |
0.41 |
0.403 |
0.71 |
0.756 |
|
12 |
0.35 |
0.364 |
0.41 |
0.391 |
0.70 |
0.753 |
|
13 |
0.35 |
0.357 |
0.38 |
0.381 |
0.70 |
0.750 |
|
14 |
0.34 |
0.351 |
0.38 |
0.373 |
0.69 |
0.747 |
|
15 |
0.33 |
0.345 |
0.38 |
0.365 |
0.69 |
0.743 |
|
16 |
0.33 |
0.340 |
0.38 |
0.359 |
0.69 |
0.739 |
|
17 |
0.32 |
0.336 |
0.37 |
0.353 |
0.69 |
0.735 |
|
18 |
0.32 |
0.332 |
0.37 |
0.348 |
0.69 |
0.731 |
|
19 |
0.32 |
0.328 |
0.35 |
0.343 |
0.68 |
0.727 |
|
20 |
0.31 |
0.325 |
0.35 |
0.339 |
0.68 |
0.723 |
|
21 |
0.31 |
0.322 |
0.34 |
0.335 |
0.67 |
0.719 |
|
22 |
0.31 |
0.319 |
0.34 |
0.331 |
0.67 |
0.715 |
|
23 |
0.31 |
0.317 |
0.34 |
0.328 |
0.66 |
0.711 |
|
24 |
0.30 |
0.314 |
0.34 |
0.325 |
0.66 |
0.707 |
|
25 |
0.30 |
0.312 |
0.34 |
0.322 |
0.66 |
0.703 |
|
26 |
0.30 |
0.310 |
0.33 |
0.320 |
0.65 |
0.699 |
|
27 |
0.30 |
0.308 |
0.33 |
0.317 |
0.65 |
0.695 |
|
28 |
0.30 |
0.306 |
0.32 |
0.315 |
0.65 |
0.692 |
|
29 |
0.30 |
0.304 |
0.32 |
0.313 |
0.65 |
0.688 |
|
30 |
0.30 |
0.302 |
0.32 |
0.310 |
0.65 |
0.685 |
В табл. 2 приводятся значения мощности критериев ![]() от 6 до 30. Проследив изменение мощности
критериев при
от 6 до 30. Проследив изменение мощности
критериев при ![]() <6, мы убедимся, что, если мощность критерия
<6, мы убедимся, что, если мощность критерия ![]() Пирсона с уменьшением числа интервалов
продолжает возрастать, то мощность критерия Никулина со статистикой
Пирсона с уменьшением числа интервалов
продолжает возрастать, то мощность критерия Никулина со статистикой ![]() при
при ![]() начинает падать. Об этом свидетельствуют как
результаты моделирования распределений статистик, так теоретические расчеты
мощности критериев. Следовательно, для критерия Никулина существует оптимальное
число интервалов, при котором его мощность максимальна.
начинает падать. Об этом свидетельствуют как
результаты моделирования распределений статистик, так теоретические расчеты
мощности критериев. Следовательно, для критерия Никулина существует оптимальное
число интервалов, при котором его мощность максимальна.
Выводы
Таким образом, проведенные исследования свойств статистики, предложенной Никулиным, показали, что она обладает тремя важными для практического применения достоинствами.
Во-первых, при любой сложной проверяемой гипотезе ![]() и использовании асимптотически эффективных ОМП
параметров по исходной негруппированной выборке
статистика
и использовании асимптотически эффективных ОМП
параметров по исходной негруппированной выборке
статистика ![]() при справедливой гипотезе
при справедливой гипотезе ![]() имеет в качестве предельного известное точно распределение
имеет в качестве предельного известное точно распределение
![]() . По существу, это уникальное свойство “свободы от распределения”
при проверке сложной гипотезы.
. По существу, это уникальное свойство “свободы от распределения”
при проверке сложной гипотезы.
Во-вторых, распределения статистики ![]() практически не зависят от способа группирования,
способа разбиения области определения случайной величины на интервалы.
практически не зависят от способа группирования,
способа разбиения области определения случайной величины на интервалы.
В-третьих, мощность критерия Никулина при близких альтернативах выше мощности критерия Пирсона. Это говорит о том, что с его помощью лучше различаются близкие гипотезы.
Вышеперечисленное позволяет настойчиво рекомендовать
применение статистики ![]() в
приложениях и, особенно, для включения в программное обеспечение задач
статистического анализа. Некоторые дополнительные усилия при реализации,
связанные с большей сложностью статистики
в
приложениях и, особенно, для включения в программное обеспечение задач
статистического анализа. Некоторые дополнительные усилия при реализации,
связанные с большей сложностью статистики ![]() по
сравнению со статистикой
по
сравнению со статистикой ![]() ,
в конечном счете, себя оправдывают.
,
в конечном счете, себя оправдывают.
Отметим попутно следующие, по нашему мнению,
бесспорные факты, которые должны учитываться при проведении статистического анализа.
Во-первых, выбирая число интервалов в критериях типа ![]() , мы должны осознавать, что увеличение их числа не
приводит к росту мощности критерия. Во-вторых, следует
учитывать, что при проверке простых гипотез непараметрические критерии
согласия уступают по мощности критериям типа
, мы должны осознавать, что увеличение их числа не
приводит к росту мощности критерия. Во-вторых, следует
учитывать, что при проверке простых гипотез непараметрические критерии
согласия уступают по мощности критериям типа ![]() , особенно, если в последних
применяется асимптотически оптимальное группирование [5-7]. В то же время, при проверке сложных гипотез
непараметрические критерии оказываются более мощными. И в этом случае критерий
Никулина по мощности приближается к непараметрическим.
, особенно, если в последних
применяется асимптотически оптимальное группирование [5-7]. В то же время, при проверке сложных гипотез
непараметрические критерии оказываются более мощными. И в этом случае критерий
Никулина по мощности приближается к непараметрическим.
ЛИТЕРАТУРА
1. Кендалл М., Стьюарт А. Статистические выводы и связи. – М.: Наука, 1973. – 900 с.
2. Chernoff H., Lehmann E.L.
The use of maximum likelihood estimates in ![]() test for goodness of fit
// Ann. Math. Stat., 1954. V. 25. – P. 579-586.
test for goodness of fit
// Ann. Math. Stat., 1954. V. 25. – P. 579-586.
3. Чибисов Д.М. Некоторые критерии типа хи-квадрат для непрерывных распределений // Теория вероятностей и ее применение. 1971. Т. XVI. № 1. – С. 3-20.
4.
Лемешко Б.Ю., Постовалов С.Н. О
зависимости предельных распределений статистик ![]() Пирсона и отношения правдоподобия от способа
группирования данных // Заводская лаборатория. 1998. Т. 64. – № 5. – С.56-63.
Пирсона и отношения правдоподобия от способа
группирования данных // Заводская лаборатория. 1998. Т. 64. – № 5. – С.56-63.
5. Денисов В.И., Лемешко Б.Ю., Цой Е.Б. Оптимальное группирование, оценка параметров и планирование регрессионных экспериментов: В 2 ч. / Новосиб. гос. техн. ун-т. - Новосибирск, 1993. – 346 с.
6. Лемешко Б.Ю. Асимптотически оптимальное группирование наблюдений - это обеспечение максимальной мощности критериев // Надежность и контроль качества. – 1997. – № 8. – С. 3-14.
7. Лемешко Б.Ю. Асимптотически оптимальное группирование наблюдений в критериях согласия // Заводская лаборатория, 1998. Т. 64. – №1. – С.56-64.
8.
Денисов В.И., Лемешко Б.Ю., Постовалов
С.Н. Прикладная статистика. Правила проверки согласия опытного распределения с
теоретическим. Методические рекомендации. Часть
I. Критерии типа ![]() .
– Новосибирск: Изд-во НГТУ, 1998. – С. 126.
.
– Новосибирск: Изд-во НГТУ, 1998. – С. 126.
9. Никулин М.С. Критерий хи-квадрат для непрерывных распределений с параметрами сдвига и масштаба // Теория вероятностей и ее применение. 1973. Т. XVIII. № 3. – С.583-591.
10.Никулин М.С. О критерии хи-квадрат для непрерывных распределений // Теория вероятностей и ее применение. 1973. Т. XVIII. № 3. – С.675-676.
11.Мирвалиев М., Никулин М.С. Критерии
согласия типа хи-квадрат // Заводская лаборатория. 1992. Т. 58. № 3. – С.52-58.
12.Aguirre N., Nikulin M. Chi-squared goodness-of-fit test for the family of logistic distributions // Kybernetika. 1994. V. 30. № 3. – P.214-222.
13.Лемешко Б.Ю., Постовалов С.Н. О распределениях статистик непараметрических критериев согласия при оценивании по выборкам параметров наблюдаемых законов // Заводская лаборатория. 1998. Т. 64. – № 3. – С. 61-72.
14.Орлов А.И. Методы оценки близости допредельных и предельных распределений статистик // Заводская лаборатория. 1998. Т. 64. – № 5. – С. 64-67.
15.Лемешко Б.Ю. Статистический анализ одномерных наблюдений случайных величин: Программная система. – Новосибирск: Изд-во НГТУ. – 1995. – 125 с.
16.Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. – М.: Наука, 1983. – 416 с.
17.Чибисов Д.М., Гванцеладзе Л.Г. О критериях согласия, основанных на группированных данных // III советско-японский симпозиум по теории вероятностей. Ташкент: изд-во “Фан”, 1975. – С. 183-185.
18.Боровков А.А. О мощности критерия ![]() при увеличении числа групп // Теория
вероятностей и ее применение. 1977. Т. XXII. № 2. – С.375-378.
при увеличении числа групп // Теория
вероятностей и ее применение. 1977. Т. XXII. № 2. – С.375-378.