2.3 Критерии типа c2 при сложных гипотезах
При справедливости H0 в случае проверки сложной гипотезы и при условии, что оценки параметров находятся в результате минимизации статистики Sc2 по этой же самой выборке, статистика Sc2 асимптотически распределена как c2r с числом степеней свободы r=k-m-1, где m – число оцененных параметров. Статистика Sc2 имеет это же распределение, если в качестве метода оценивания выбирают метод максимального правдоподобия и оценки вычисляют по сгруппированным данным в результате максимизации по q функции правдоподобия
![]() ,
(8)
,
(8)
где
g – некоторая константа и 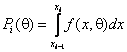 –
вероятность попадания наблюдения в i-й
интервал значений, зависящая от q.
–
вероятность попадания наблюдения в i-й
интервал значений, зависящая от q.
При вычислении оценок максимального правдоподобия
(ОМП) по негруппированным данным эта же статистика распределена как сумма
независимых слагаемых ![]() , где x1,
x1,….,
xm – стандартные
нормальные случайные величины, независимые одна от другой и от c2k-m-1, а l1,
l1,….,
lm – некоторые числа
между 0 и 1 [2], [6], [7],
представляющие собой корни уравнения
, где x1,
x1,….,
xm – стандартные
нормальные случайные величины, независимые одна от другой и от c2k-m-1, а l1,
l1,….,
lm – некоторые числа
между 0 и 1 [2], [6], [7],
представляющие собой корни уравнения
![]() .
.
В данном уравнении J(q) – информационная матрица Фишера по негруппированным наблюдениям с элементами, определяемыми соотношением
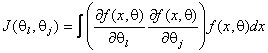 ,
(9)
,
(9)
а JG(q) – информационная матрица по группированным наблюдениям
![]() .
(10)
.
(10)
Функция распределения статистики лежит между c2k-1– и c2k-m-1–распределениями. В этом случае, принимая нулевую гипотезу, следует удостовериться, что статистика Sc2 не превышает критических значений c2k-m-1,a и c2k-1,a, где a – задаваемый уровень значимости. И если c2k-m-1,a < S*c2<c2k-1,a, то, принимая или отклоняя гипотезу о согласии, можно с одинаковым риском совершить ошибку.
Вышеизложенное относится и к критерию отношения правдоподобия.
Влияние способа группирования на распределения этих статистик при использовании оценок максимального правдоподобия по негруппированным данным – по 2.7.